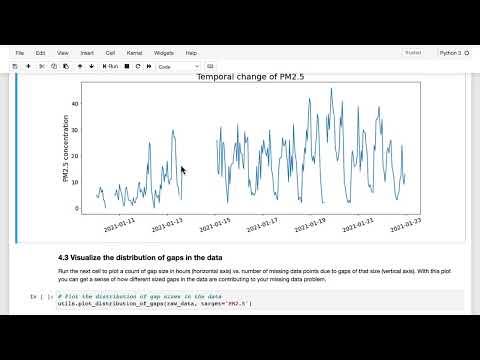
На прошедшем мероприятии Аман Хан из компании Arise представил новый взгляд на тестирование ИИ-агентов, предложив отказаться от субъективной оценки в пользу строгих метрик. В рамках совместного курса с DeepLearning.AI эксперт продемонстрировал, как разработчики могут перейти от интуитивного программирования к эмпирическому анализу с помощью специализированных инструментов. Основной акцент был сделан на автоматизации оценки работы агентов и оптимизации промптов для ИИ-судей.
🛠️ От «интуитивного кода» к доказательной инженерии: философия Thrive Coding 0:00
Разработка приложений на базе искусственного интеллекта часто сталкивается с проблемой поверхностного тестирования. По словам Амана Хана, многие инженеры до сих пор практикуют так называемый vibe coding (интуитивное программирование), когда готовность системы к релизу оценивается субъективным ощущением «вроде бы работает нормально». Для иллюстрации этой проблемы спикер продемонстрировал изображение, созданное нейросетью Imagen от Google, на котором запечатлён встревоженный разработчик, отправляющий агента в продакшен без должной проверки.
В качестве альтернативы Хан предлагает концепцию thrive coding (доказательная инженерия) — подход, при котором ИИ-система создаётся на основе эмпирических данных и непрерывного мониторинга метрик прямо на экране разработчика. Спикер иронично заметил, что «интуитивное программирование осталось на прошлой неделе». Переход к доказательной инженерии базируется на трёх ключевых принципах:
- Смена парадигмы с субъективной оценки («выглядит неплохо») на эмпирические метрики.
- Масштабирование тестовых данных: система, успешно прошедшая проверку на 5–10 строках кода, может дать сбой, когда завтра на неё придут 100 реальных пользователей.
- Обеспечение стабильности и воспроизводимости результатов вместо хаотичных проверок.
🧭 Анатомия ИИ-агента: маршрутизаторы, навыки и память 3:32
Чтобы понять принципы тестирования, необходимо разобрать внутреннюю структуру современного ИИ-агента. В качестве сквозного примера Хан выбрал гипотетического ИИ-ассистента для планирования путешествий. Любой подобный агент состоит из трёх базовых элементов: интерфейса ввода, блока логических рассуждений и механизма вызова внешних инструментов. С технической точки зрения архитектура ИИ-агента разделяется на следующие компоненты:
- Маршрутизатор (Router) — логический центр, который анализирует запрос пользователя и определяет, какие действия необходимо предпринять. Например, если клиент просит «забронировать билет до Сан-Франциско», маршрутизатор должен понять, хватает ли ему данных или нужно задать уточняющий вопрос о дате вылета.
- Навыки (Skills) или ветви исполнения — цепочки логики, отвечающие за конструирование и выполнение конкретных API-вызовов. Хан привёл пример сложного навыка RAG (генерации с привлечением знаний), который под капотом объединяет три операции: векторизацию запроса, поиск в векторной базе данных и передачу контекста в модель.
- Состояние памяти (Memory state) — общая область данных, содержащая историю диалога и контекст, к которой имеют доступ все элементы системы.
При оценке эффективности этих компонентов применяются разные подходы. Работу маршрутизатора можно проверять по эталонным меткам (ground truth), определяя, правильный ли набор навыков выделила модель для решения задачи. Эффективность памяти оценивается через метрику сходимости (convergence) — количество шагов, которое требуется агенту для достижения цели. По мнению Хана, критически важно избегать рекурсивных циклов, когда агент бесконечно запрашивает у пользователя одну и ту же информацию, критически снижая скорость ответа и ухудшая пользовательский опыт.
💻 Практический воркшоп: трассировка и сбор данных в Phoenix 8:32
В практической части выступления Аман Хан продемонстрировал процесс создания и развёртывания агента для анализа коммерческих данных. Для демонстрации использовался интерактивный ноутбук, доступный по ссылке bit.ly/riseaiv, содержащий реальные таблицы продаж маркетплейса с информацией о номерах магазинов, SKU, классах продуктов и объёмах отгрузок. Визуализация данных осуществлялась через Phoenix — специализированный инструмент с открытым исходным кодом, разрабатываемый компанией Arise.
Процесс подготовки системы к оценке состоит из нескольких этапов:
- Инициализация конечной точки коллектора Phoenix и настройка API-ключей для проекта.
- Инструментация приложения — создание логов вызовов для отслеживания промежуточных атрибутов. Спикер сравнил этот процесс с работой платформы DataDog, но адаптированной под специфику ИИ.
- Тестирование базовой модели с помощью простого запроса на генерацию шутки для верификации отправки токенов, задержек и таймингов в интерфейс Phoenix.
Для выполнения аналитических задач агенту были предоставлены три инструмента: генератор SQL-запросов из естественного языка, модуль интерпретации данных и блок визуализации (построения графиков). Инструменты регистрировались в коде с помощью декораторов.
В ходе тестового запуска агенту передали комплексный запрос: «У каких магазинов были самые высокие продажи в ноябре 2021 года? Выведи визуализацию». Модель успешно сгенерировала SQL-запрос и извлекла данные о продажах, однако на этапе построения графика произошёл сбой: в интерфейс вернулась текстовая заглушка something.png вместо реального изображения. Хан подчеркнул, что использование Phoenix позволяет детально разложить этот процесс по шагам (spans) и зафиксировать ошибку, что практически невозможно сделать при обычном ручном тестировании сложных систем.
⚖️ Автоматизация оценки: ИИ в роли судьи (LLM as a Judge) 16:18
Поскольку ручной аудит тысяч диалогов невозможен при масштабировании, разработчики используют методологию «ИИ в роли судьи» (LLM as a Judge), когда одна модель проверяет корректность работы другой. Для этого данные о вызовах инструментов экспортируются из Phoenix в формат DataFrame.
Для проведения экспертизы Хан использовал библиотеку LLM classify и специализированный шаблон промпта, оценивающий соответствие выбранного инструмента запросу пользователя. Спикер дал важную рекомендацию по проектированию ИИ-судей:
«ИИ-модели склонны галлюцинировать цифрами, поэтому вместо выставления баллов (например, от 1 до 5) необходимо использовать жестко зафиксированные текстовые категории — так называемые rails. В нашем случае это были метки "correct" (правильно) и "incorrect" (неправильно) с обязательным требованием текстового обоснования вердикта».
После загрузки результатов оценки обратно в Phoenix система показала, что агент выполнил вызовы инструментов с точностью 80%. Изучив проблемные сессии, ИИ-судья корректно идентифицировал ту самую ошибку с генерацией несуществующего графика, указав в обосновании, что пользователь просил визуализацию, но агент её не предоставил.
🚀 Оптимизация промптов: четыре метода повышения точности ИИ-судей 19:47
В заключительной части доклада Аман Хан разобрал проблему повышения качества работы самих ИИ-судей. Опираясь на практические наработки руководителя отдела по связям с разработчиками Arise по имени Джон, спикер выделил четыре популярные техники оптимизации промптов, эффективность которых должна подтверждаться исключительно цифрами, а не громкими названиями.
Для тестирования методик в Phoenix был загружен эталонный набор данных (golden dataset), созданный на базе реальных логов и дополненный синтетическими примерами от ChatGPT. Базовый промпт ИИ-судьи без оптимизации показал скромную точность в 68% относительно предустановленных экспертных меток.
Эксперимент по оптимизации включал следующие подходы:
- Градиентная оптимизация промптов (Gradient prompt optimization) — метод настройки функции потерь промпта с использованием эмбеддингов, наиболее эффективный для длинных и сложных текстовых инструкций.
- Few-shot prompting — включение нескольких эталонных примеров выполнения задачи непосредственно в тело запроса. Этот подход увеличивает контекстное окно, но добавляет системе детерминизма. На тестовом датасете данная техника показала резкий скачок точности — с 68% до 84%.
- Мета-промптинг (Meta prompting) — привлечение сторонней языковой модели в роли «эксперта по промпт-инжинирингу». Модель анализирует базовый запрос, примеры ошибок и генерирует новую, более строгую инструкцию для ИИ-судьи. Внедрение мета-промпта позволило поднять точность тестирования до 88%.
- Использование библиотеки DSPy (алгоритм Mipro) — подход, заимствующий методы классического машинного обучения для автоматического подбора формулировок через компиляцию и итерационный поиск. В ходе демонстрации оптимизированный с помощью DSPy промпт показал высокую скорость выполнения операций, однако качественная точность ИИ-судьи практически не изменилась по сравнению с предыдущим шагом.
Резюмируя выступление, Хан подчеркнул, что по мере усложнения ИИ-агентов детальная трассировка и автоматизированная оценка становятся единственным способом контролировать поведение систем в продакшене.