В рамках специализации AI for Good от DeepLearning.AI рассматривается критически важный этап разработки технологических решений — создание базовой линии (baseline). В новом практическом занятии основное внимание уделяется проблеме пропусков в данных сенсоров качества воздуха и тому, почему простые статистические методы иногда оказываются эффективнее сложных нейросетей на начальном этапе.
📊 Зачем нужна базовая линия в проектах AI for Good? 0:15
Установление простого базового решения перед переходом к машинному обучению (AI) преследует три ключевые цели:
- Скорость и стоимость: Если простой метод достигает поставленных целей, проект можно завершить быстрее и дешевле .
- Интерпретируемость: Результаты элементарных алгоритмов проще объяснить стейкхолдерам и конечным пользователям .
- Количественная оценка: Базовая линия необходима, чтобы точно измерить относительное улучшение производительности при внедрении сложной модели .
В данном сценарии анализируются данные о загрязнении воздуха частицами PM 2.5 (мелкодисперсная пыль). Для восстановления пропущенных значений тестируются два классических подхода:
- Last Observation Carried Forward (LOCF): использование последнего успешно записанного измерения для заполнения всех последующих пустых ячеек .
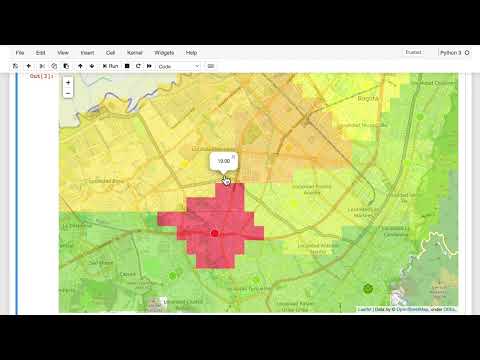
- Nearest Neighbor (Ближайший сосед): использование текущего значения с ближайшего работающего датчика .
🛠 Обзор инструментов и данных лабораторной работы 1:03
Работа ведется в среде Jupyter Notebook. В обучающем видео подчеркивается важность документации данных:
- Data Sheets: Специальные файлы в папке проекта, которые содержат информацию о том, зачем собирался датасет, кто проводил аннотацию и какие именно параметры включены в выборку .
- Файл
utils.py: Содержит вспомогательный код, скрытый от пользователя, чтобы не загромождать основной ноутбук лишними деталями реализации .
Для начала работы необходимо выполнить импорт пакетов и загрузить основной датасет. После чтения данных выполняется важный шаг предобработки — перевод названий столбцов с испанского на английский для удобства интерпретации . Также загружается отдельный набор данных с географическими координатами (широта и долгота) всех сенсорных станций для расчета расстояний между ними .
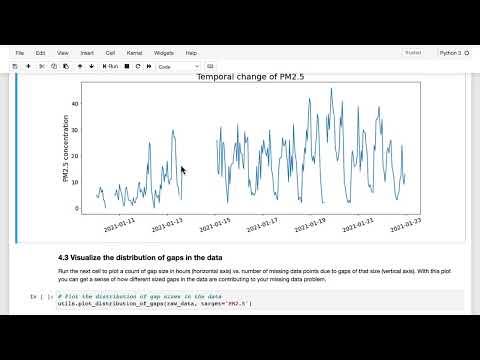
📉 Анализ пробелов: от часов до месяцев 3:09
При визуализации пропущенных данных обнаруживается неоднородность «провалов» в графиках. Исследователи выделяют два типа проблем:
- Краткосрочные сбои: Пропуски длительностью в 1–2 часа.
- Долгосрочные поломки: Датчики могут выходить из строя на недели и даже месяцы.
Анализ гистограммы размеров пропусков для PM 2.5 показал интересную статистику:
- В данных присутствует около 700 случаев отсутствия данных всего на один час .
- Самый крупный разрыв в данных составил около 3600 часов (примерно пять месяцев) .
- Хотя мелких пропусков количественно больше, основная масса отсутствующих данных создается именно крупными временными «дырами» .
🧪 Сравнение методов заполнения пропусков 5:51
При симуляции выпадения сенсора методы показывают себя по-разному. Метод «последнего измерения» превращает график в плоскую линию, повторяя старое значение . Метод «ближайшего соседа» подтягивает динамические данные с другой точки .
Ключевые выводы тестирования:
- При увеличении окна пропуска (продолжительности сбоя) точность метода последнего измерения стремительно падает, так как состояние атмосферы меняется .
- Метод ближайшего соседа дает вариативные результаты, но его точность не деградирует с течением времени . Именно он был выбран в качестве финальной базовой линии для дальнейшего сравнения с ИИ.
📏 Оценка точности и метрика MAE 8:08
Для оценки эффективности используется метрика MAE (Mean Absolute Error — средняя абсолютная ошибка). Выбор пал на неё из-за интуитивности: значение ошибки выражается в тех же единицах, что и измеряемый параметр.
- Для PM 2.5 единицы измерения — микрограммы на кубический метр (мкг/м³) .
- В ходе симуляции средняя ошибка метода ближайшего соседа составила 8 мкг/м³ .
Этот результат ставит перед разработчиками серьезный вызов. Поскольку ВОЗ и другие организации рекомендуют ограничивать среднегодовой уровень PM 2.5 значением в 12 мкг/м³, ошибка в 8 единиц является критической . Она создает риск ложноположительных или ложноотрицательных оценок безопасности воздуха. Эта цифра (8 мкг/м³) становится «планкой», которую должна превзойти нейронная сеть в следующем модуле обучения .