В лекции из серии курса MIT OpenCourseWare исследовательница Сэра Бири представляет глубокий анализ архитектур нейронных сетей, специализированных на обработке последовательностей и управлении памятью. Рассматривая эволюцию подходов от ранних пространственно-временных сверток до рекуррентных моделей и современных трансформеров, лектор раскрывает фундаментальные математические ограничения каждого метода. Главный фокус материала направлен на баланс между вычислительной эффективностью моделей и их способностью удерживать долгосрочный контекст.
🕒 Мотивация моделирования последовательностей и времени 0:13
При анализе статических изображений современные алгоритмы компьютерного зрения способны добиваться высоких результатов, однако они полностью слепы к динамике изменений во времени. Если продемонстрировать человеку или нейросети один изолированный кадр из видео, на котором запечатлен класс детского сада с играющими детьми, телевизором и красным стулом, система сможет успешно распознать объекты и ответить на базовые вопросы об их атрибутах. Тем не менее, без временного сигнала невозможно предсказать, что произойдет в следующий момент, поскольку для этого требуется понимание контекста и намерений участников сцены.
В качестве иллюстрации приводится видеозапись безобидного розыгрыша: мальчик внезапно вытягивает стул из-под садящейся девочки. До определенного момента зрителю кажется, что девочка просто сядет на стул, но изменение пространственно-временных связей заставляет полностью пересмотреть прогноз — становится очевидно, что она упадет. Подобный детальный анализ сцен, включающий оценку намерений и причинно-следственных связей, требует перехода к моделированию полноценных последовательностей.
Под последовательностями в машинном обучении понимаются самые разные типы данных:
- Видеозаписи, представляющие собой упорядоченные во времени кадры (например, съемка итальянской городской площади).
- Языковые конструкции, где фраза вроде «Вечерняя прогулка по городской площади» является последовательностью слов.
- Аудиосигналы, фиксирующие звуковые колебания в хронологическом порядке.
🧊 Пространственно-временные свертки и их ограничения 5:00
Исторически первым и интуитивно понятным способом работы с видео стало расширение классических сверточных нейронных сетей (CNN) в пространственно-временное измерение. В такой конфигурации видео трансформируется в четырехмерный тензор, где к двум пространственным координатам и трем цветовым каналам (RGB) добавляется четвертая ось — время. Визуализировать структуру этого пространственно-временного куба можно с помощью двухмерных срезов.
Сэра Бири демонстрирует, как горизонтальный пиксельный срез через весь массив кадров преобразуется в изображение с характерными полосами, отражающими траектории и скорость движения проходящих мимо людей. Похожий принцип фиксации времени использовался на Олимпийских играх еще до эпохи глубокого обучения: фотофиниш на линии горизонтального пикселя позволял линейно развернуть финишную черту во времени и определить победителя гонки с точностью до миллисекунды.
Для обработки таких данных применяются одномерные или многомерные свертки по временной оси, работающие в рамках фиксированного окна. Модель скользит этим окном вдоль временной шкалы, что позволяет подавать на вход данные произвольной длины. Такой подход эффективен для статических камер, непрерывно транслирующих происходящее в помещении, или для анализа трехмерных томограмм (МРТ) и гиперспектральных спутниковых снимков, содержащих до 384 спектральных диапазонов.
Однако у временных сверток есть критический недостаток: по мере удлинения последовательности сеть стремительно теряет информацию о событиях в ее начале. Лектор иллюстрирует это на примере своего кота Фрэнка, которого она называет «самым красивым котом в мире». Если снимать видео, перемещаясь по дому, фиксированное окно свертки в определенный момент перестанет захватывать кадры из начала съемки. В результате модель, увидев рыжее животное на улице, может ошибочно классифицировать его как тигра, потеряв контекст того, что изначально съемка велась внутри дома, где тигры не водятся. Для решения этой проблемы необходим выделенный блок памяти, способный сохранять глобальный контекст.
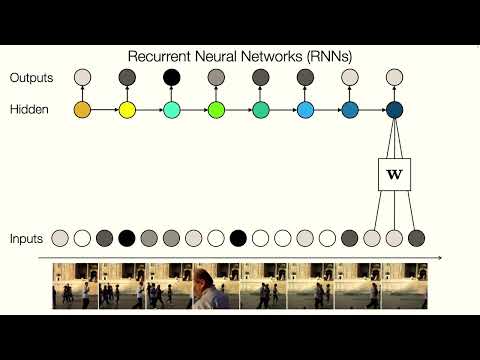
🔁 Рекуррентные нейронные сети (RNN) и скрытые состояния 10:48
В отличие от трансформеров или CNN ранних поколений, которые опираются на фиксированные окна контекста, рекуррентные нейронные сети (RNN) теоретически способны работать с бесконечным временным горизонтом. Это достигается за счет внедрения концепции скрытого состояния (hidden unit), которое передается от одного шага к другому. На каждом временном этапе сеть принимает текущий входной сигнал и скрытое состояние из прошлого шага, формируя новое представление памяти и выдавая прогноз.
Математически этот процесс описывается рекуррентной функцией $f$, вычисляющей следующее скрытое состояние на основе предыдущего состояния и текущих данных. Примечательно, что параметры функции $f$ остаются неизменными (общими) для всех шагов во времени. Аналогично, общая функция $g$ отображает скрытое состояние в итоговое предсказание на каждом шаге.
Из-за наличия обратной связи архитектура RNN нарушает привычную для нейросетей структуру направленного ациклического графа (DAG) — в ней образуется цикл. Чтобы сделать граф ациклическим для конкретных расчетов, его структуру «разворачивают» (unroll) во времени. В простейшем линейном исполнении вычисления выглядят следующим образом:
- Текущее скрытое состояние вычисляется как нелинейная функция (например, тангенс или сигмоида) от суммы предыдущего скрытого состояния, умноженного на весовую матрицу $W$, и текущего входа, умноженного на матрицу $U$, с добавлением вектора смещения.
- Выходной сигнал формируется путем умножения скрытого состояния на матрицу $V$ с добавлением собственного смещения.
Если бы матрица рекуррентных связей $W$ была равна нулю, модель превратилась бы в стандартный многослойный перцептрон (MLP) или одномерную свертку. Роль скрытого состояния заключается в долгосрочном удержании наиболее релевантной исторической информации, а матрица $W$ в процессе обучения настраивается так, чтобы определять, какие именно данные критически важно сохранить. Архитектуру можно делать глубокой, наслаивая множество скрытых рекуррентных уровней друг на друга.
📈 Обратное распространение ошибки во времени (BPTT) 16:08
Отвечая на вопрос из аудитории о том, до какого момента нужно разворачивать сеть и где находится точка остановки, Сэра Бири шутит, цитируя Базза Лайтера: «К бесконечности и далее!». В чистом виде у модели нет встроенного понимания конца последовательности: вычисления прекращаются, когда иссякает поток входных данных. На практике файлы видео или аудио имеют конечную длину, но в непрерывных задачах (например, при ежедневной фиксации температуры) алгоритм может работать бесконечно. Лектор поясняет, что теоретически сеть все же удерживает глубокую историю, так как предыдущее состояние вобрало в себя информацию из позапрошлого, и так далее до самого начала.
Главной проблемой долгое время оставалась невозможность применить стандартный метод обратного распространения ошибки из-за наличия циклов в графе. Решением стал алгоритм обратного распространения ошибки во времени (Backpropagation Through Time, BPTT). Инженерный трюк заключается в выборе фиксированного временного окна для обучения, в рамках которого граф разворачивается, превращаясь в классический DAG. Градиенты рассчитываются по цепочке от конечной точки окна назад до нулевого элемента последовательности.
Этот подход накладывает ограничения на обучение:
- Длина окна развертки становится гиперпараметром, который исследователи вынуждены подбирать вручную или на основе экспертных знаний.
- Хотя на этапе инференса сеть способна принимать длинные последовательности, обучение на усеченном окне де-факто приучает модель игнорировать слишком далекие временные связи.
- При расчете градиентов для общей матрицы $W$, присутствующей на каждом шаге развернутого графа, применяется правило ветвления: градиенты со всех временных этапов суммируются.
В современных фреймворках, таких как PyTorch, этот процесс автоматизирован. Главное требование к разработчику — передавать переменные по ссылке и избегать глубокого копирования объектов (deep copy), чтобы ссылки на общие параметры не терялись в памяти.
📉 Проблема затухающих градиентов и архитектура LSTM 27:29
Стремление расширить окно BPTT до бесконечности сталкивается с аппаратными и математическими барьерами: объем требуемой памяти растет линейно вместе с длиной последовательности $T$. Если рассмотреть математику рекуррентного шага в упрощенном виде (без нелинейных функций и смещений), то для первого шага скрытое состояние равно $h_1 = W h_0 + U x_1$, для второго — $h_2 = W^2 h_0 + W U x_1 + U x_2$, а для $n$-го шага весовая матрица возводится в $n$-ю степень: $W^n$.
Такая квадратичная и экспоненциальная зависимость порождает опасный математический эффект:
- Если собственные значения матрицы $W$ хотя бы немного меньше единицы, при возведении в большую степень они устремляются к нулю, вызывая затухание градиентов.
- Если значения весов больше единицы, они экспоненциально растут, приводя к взрыву градиентов и полной нестабильности обучения.
Применение спектральной нормы для нормализации весов помогает справиться со взрывом градиентов, но не решает проблему их затухания, поскольку малые значения все равно превращаются в ноль. В итоге старая информация безвозвратно стирается из памяти RNN.
Для преодоления этого кризиса была создана архитектура долгой краткосрочной памяти (Long Short-Term Memory, LSTM). Ее ключевая идея кардинально меняет логику работы с контекстом: по умолчанию сеть настроена так, чтобы ничего не забывать. LSTM использует принцип тождественного отображения (identity function) для сохранения информации, заставляя алгоритм целенаправленно обучаться тому, что именно нужно стереть. Этот подход Сэра Бири сравнивает с механизмом сборки мусора (garbage collection) в программировании. По своей вычислительной мощности LSTM также является Тьюринг-полной системой и концептуально близка к классической машине Тьюринга с ее бесконечной лентой для записи и чтения данных.
🎛️ Анатомия ячейки LSTM 36:22
Внутри каждого шага LSTM разворачивается сложная система управления потоками данных, регулируемая специальными контроллерами (гейтами). Центральным элементом архитектуры становится состояние ячейки (cell state, $C_t$), выполняющее роль той самой Тьюринг-ленты.
Процесс обработки информации разделен на несколько этапов:
- Фильтрация прошлого (Forget Gate): Функция $f_t$ принимает скрытое состояние предыдущего шага и новые входные данные, после чего пропускает их через сигмоиду. Значения сигмоиды строго ограничены диапазоном от 0 до 1, где 0 означает «полностью стереть», а 1 — «сохранить без изменений».
- Выбор новой информации (Input Gate): Гейт $i_t$ определяет, какие именно индексы в состоянии ячейки подлежат обновлению, а блок $\tilde{C}_t$ генерирует новые значения для записи.
- Мультипликативное обновление: Предыдущее состояние ячейки поэлементно умножается на коэффициент забывания $f_t$, после чего к нему добавляется новая порция данных.
Благодаря замене последовательного умножения матриц весов на поэлементное мультипликативное обновление с использованием гейтов, инженерам удалось устранить проблему затухания градиентов. Этот механизм работает аналогично остаточным связям (skip connections) в архитектуре ResNet, позволяя информации беспрепятственно течь сквозь сотни временных шагов. На заключительном этапе выходной гейт $o_t$ решает, какая часть обновленного состояния ячейки будет передана в следующее скрытое состояние $h_t$. По мнению лектора, этот финальный шаг по своей логике напоминает проекцию значений (values) в механизме внимания современных трансформеров.
🤖 Авторегрессионные модели и генеративный ИИ 42:41
Параллельно с рекуррентными сетями на сцену вышел новый класс подходов — авторегрессионные модели, ставшие фундаментом для современного генеративного искусственного интеллекта и больших языковых моделей вроде ChatGPT. Концепция авторегрессии проста: модель принимает начало последовательности, предсказывает один следующий элемент, затем добавляет этот предсказанный элемент к исходному входу и генерирует следующий шаг.
В процессе обучения сеть анализирует массивы текстов, тренируясь угадывать каждое последующее слово. Сэра Бири демонстрирует это на примере фразы «Бесцветные зеленые идеи спят...», где модель должна выдать слово «яростно». Стоит отметить, что хотя стандартная RNN тоже может предсказывать следующее слово, она не содержит в себе автоматического внешнего цикла, который принудительно возвращал бы ее собственный выход на вход следующего шага. На математическом уровне авторегрессия раскладывает совместное вероятностное распределение последовательности на произведение условных вероятностей, где появление каждого нового слова зависит от абсолютно всех предшествующих токенов.
Для предсказания используется функция Softmax, которая превращает выходные сигналы сети в дискретное распределение вероятностей, фактически превращая генерацию в задачу многоклассовой классификации. Однако здесь возникает серьезная проблема масштаба:
- Если формировать словарь на уровне целых слов английского языка, размерность финального вектора (параметр $K$) составит около 100 000 классов. Для сравнения, в биологической базе данных iNaturalist, где лектор ведет исследования, насчитывается около 450 000 видов живых организмов. Классификация такого масштаба требует колоссальных объемов данных и крайне нестабильна при обучении.
- Если перейти на посимвольный уровень, размер словаря сократится до 26 классов (для английского алфавита). Однако цепочки станут слишком длинными, а процесс генерации начнет быстро деградировать из-за случайных орфографических ошибок, которые уведут модель в сторону от смысла текста.
Оптимальным компромиссом (sweet spot), который используется в современных LLM, стало токенизация по байтовым парам (Byte Pair Encoding, BPE), кодирующая наиболее часто встречающиеся пары символов и слогов.
🔄 Обучение и методы генерации текста 52:03
Чтобы продемонстрировать практическое применение связки различных архитектур, лектор приводит пример мультимодальной задачи «молекула в текст». Модели подается на вход структура молекулы кофеина, которую графовая нейросеть (GNN) преобразует в векторное представление. Затем этот вектор служит начальным условием для LSTM, пошагово генерирующей текстовое описание: «мягкий стимулятор, улучшающий когнические способности». В этой схеме критически важно введение специального стоп-токена (end character), сигнализирующего системе о завершении генерации.
Обучение таких систем сопряжено с риском накопления ошибок. Если модель ошиблась на втором слове последовательности, все ее последующие предсказания потеряют смысл, а штраф за кросс-энтропию окажется избыточным. Для борьбы с этим применяется метод принудительного обучения (teacher forcing): во время тренировки, независимо от того, насколько ошибочный токен выдала сеть, на вход следующего шага принудительно подается истинное (ground-truth) слово из обучающей выборки.
На этапе тестирования и инференса модель оказывается предоставлена сама себе и начинает последовательно сэмплировать слова из предсказанного распределения. Достаточно одной мелкой ошибки, чтобы генерация ушла по ложному пути. Так, вместо исходного слова «мягкий» модель может выдать «сильный стимулятор», что кардинально меняет медицинский смысл фразы.
Для минимизации таких сбоев применяется алгоритм лучевого поиска (beam search):
- Вместо выбора одного самого вероятного слова модель удерживает в памяти топ-$K$ наиболее перспективных вариантов на каждом шаге.
- Алгоритм выстраивает дерево возможных путей генерации.
- В конце вычисляется совокупная вероятность всей фразы для каждой ветви, и выбирается траектория с наивысшим итоговым баллом уверенности.
Подобные гибридные подходы на базе глубоких сетей и LSTM-компонентов удерживали лидерство в индустрии примерно до 2015 года, применяясь в задачах визуального вопросно-ответного моделирования (VQA) и аннотирования изображений, пока их не вытеснили трансформеры.
🧠 Внимание вместо памяти: Эволюция контекстных окон 58:41
Развивая тему контекста, Сэра Бири делится еще одной личной историей о своем коте Фрэнке. Будучи ответственным натуралистом, она выпускает кота на балкон только под строгим присмотром, чтобы тот не охотился на птиц, но алгоритмы фиксации должны безошибочно узнавать питомца в любых условиях. Вместо того чтобы заставлять сеть последовательно проталкивать сжатую память через длинную рекуррентную цепочку, инженеры пришли к идее предоставить каждому временному шагу собственный блок памяти с возможностью напрямую обращаться к любой исторической точке. Это легло в основу временных сверток, сетей памяти (Memory Networks) и механизмов внимания в трансформерах.
Лектор наглядно сопоставляет три ключевых подхода:
- Рекурренция: Веса зафиксированы и разделены во времени, данные передаются строго последовательно через циклическую связь.
- Свертка: Веса зафиксированы и разделены во времени, но обзор ограничен рамками жесткого временного окна.
- Внимание (Attention): Веса рассчитываются динамически как функция от самих входных данных, обеспечивая беспрецедентную гибкость.
Историческая публикация «Attention is All You Need» провозгласила манифест: классическая последовательная память больше не нужна, достаточно одного лишь внимания. Однако за гибкость приходится платить вычислительной сложностью. Механизм self-attention требует сопоставления каждого элемента последовательности с каждым, что создает квадратичную зависимость $O(n^2)$ от длины контекста $n$. Это приводит к колоссальному потреблению видеопамяти при работе с длинными текстами.
В последние годы исследовательское сообщество сфокусировалось на снижении этой сложности до линейной $O(n)$ или квазилинейной $O(n \log n)$. Среди ярких решений выделяются архитектуры Reformer (использует локальное хэширование), а также Performers и Linformers (опираются на низкоранговую матричную аппроксимацию). На практике эти методы оптимизации часто приводят к незначительному падению качества работы моделей. Как иронично замечает лектор, индустрия часто выбирает самый простой путь — вместо оптимизации алгоритмов разработчики просто создают новые графические процессоры с увеличенным объемом памяти, такие как NVIDIA H100. Другими методами расширения контекста стали сегментная рекурренция (Transformer XL), локально-глобальное маскирование (Longformers), а также архитектуры RETRO (Retrieval-Enhanced Transformers), которые заменяют раздувание контекста интеграцией легковесной языковой модели с внешней базой данных объемом в триллион токенов, что позволяет радикально снизить уровень галлюцинаций ИИ.
Развитие контекстных окон коммерческих моделей наглядно демонстрирует технологический скачок:
- Модель BERT — 512 токенов.
- GPT-2 — 1024 токена.
- GPT-3 — 2048 токенов.
- GPT-4 — базовое окно в 8000 токенов с расширением до 32 000.
- Модели от Anthropic — до 100 000 токенов (около 75 000 слов), что сопоставимо с объемом двух-трех художественных книг.
📊 Когда действительно нужен длинный контекст? 1:07:36
Несмотря на впечатляющие цифры, Сэра Бири призывает к прагматизму: покупку дорогостоящих ускорителей уровня H100 могут позволить себе далеко не все исследовательские группы, поэтому вопросы энергоэффективности, скорости обучения и доступности моделей остаются критическими. В качестве важного теоретического подкрепления лектор ссылается на исследование группы Джитендры Малика (Jitendra Malik), опубликованное примерно за два года до текущей лекции, в котором авторы задались вопросом: когда видеомоделям действительно необходим долгосрочный контекст?
Ученые ввели понятие «минимального детального набора» (minimum certificate set) — минимального количества кадров, достаточного для безошибочного распознавания действия на видео. Результаты анализа существующих бенчмарков оказались неожиданными: для подавляющего большинства популярных тестов распознавания видеопотока модели требовалось всего от одной до две секунды контекста. Разработка тяжеловесных сетей, способных анализировать трехчасовые фильмы, не приносила дивидендов просто потому, что сами тестовые задания оценивали короткие бытовые действия длительностью в пару секунд. Чтобы преодолеть этот застой, исследователи представили новый бенчмарк EgoSchema. По мнению лектора, этот прецедент демонстрирует важный мета-вывод: метрики и бенчмарки напрямую управляют вектором развития науки; если в тестах есть слепые зоны, исследователи тратят ресурсы на оптимизацию параметров, которые не дают реального прогресса.
В финале лекции Сэра Бири предлагает оригинальный взгляд на дуализм архитектур через концепцию быстрой и медленной памяти:
- Быстая память: Активации слоев внутри замороженной нейросети при прохождении единичного кадра или токена. Они отражают мгновенную статистику конкретного объекта.
- Медленная память: Веса и параметры ($\theta$) самой сети, извлекаемые в процессе длительного обучения на гигантских датасетах. Веса кодируют в себе глобальную статистику всего распределения данных.
Эту логику можно инвертировать. Существуют концепции гиперсетей (Hypernets), которые генерируют веса для других сетей на основе входного сигнала, превращая сами веса в быструю память. С другой стороны, подходы на основе общих кодовых книг (Codebooks) обучают непосредственно тензоры активаций с помощью обратного распространения ошибки, трансформируя активации в медленную память всей системы.



