Метод Self-Supervised Learning (самообучающееся обучение) долгое время опирался на использование «негативных примеров» для предотвращения коллапса нейросетей, однако исследователи из DeepMind и Имперского колледжа Лондона предложили подход, который переворачивает эту парадигму. В видео Янник Кильхер (Yannic Kilcher) подробно разбирает статью о BYOL (Bootstrap Your Own Latent) — алгоритме, который умудряется обучаться архитектуре ResNet-50 без использования контрастивных пар, полагаясь лишь на итеративное предсказание собственных представлений данных.
🧠 Суть BYOL: Обучение представлений без меток 1:10
Понятие «Representation Learning» (обучение представлений) является фундаментальным для современной компьютерной мощи. Янник Кильхер объясняет, что задача состоит в обучении нейросети (обычно ResNet-50) преобразовывать входное изображение в компактный вектор (H) . Этот вектор должен содержать достаточно семантической информации, чтобы на его основе можно было легко решить множество прикладных задач с помощью простого линейного классификатора или тонкой настройки (fine-tuning) на малом наборе данных .
В классическом обучении с учителем (supervised) сеть учится предсказывать метки классов (например, в ImageNet), но self-supervised подход позволяет использовать огромные массивы неразмеченных данных . До появления BYOL доминировала логика контрастивного обучения (Contrastive Learning):
- Позитивные пары: Две разные версии одного и того же изображения (полученные через аугментацию) должны иметь схожие векторы представлений.
- Негативные пары: Представления разных изображений должны максимально отдаляться друг от друга в векторном пространстве .
Янник Кильхер отмечает, что негативные примеры считались критически важными . Без них сеть могла бы легко «обмануть» систему, выдавая константный вектор (например, всегда ноль) для любого входа — это называется тривиальным решением или коллапсом . BYOL же утверждает, что негативные примеры не обязательны.
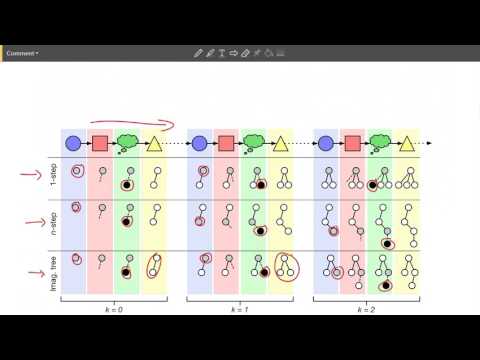
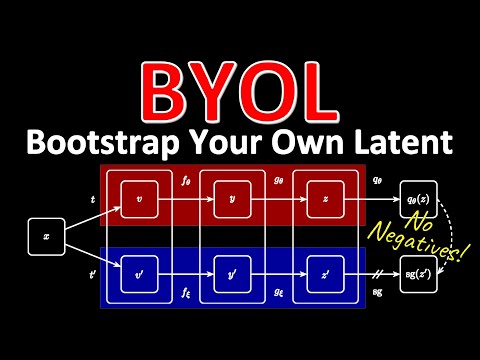
🛠 Архитектура: Онлайн-сеть против Целевой сети 11:02
BYOL использует две взаимодействующие нейронные сети: онлайн-сеть (online) и целевую сеть (target). Процесс обработки данных выглядит следующим образом:
- Двойная аугментация: Одно изображение подается на вход в двух вариантах. К ним применяются случайные трансформации: кроппинг, изменение цвета, повороты .
- Эволюция параметров: Онлайн-сеть обучается градиентным спуском. Параметры целевой сети не обучаются напрямую, а являются «экспоненциальным скользящим средним» (EMA) от параметров онлайн-сети .
- Предсказание: Вместо того чтобы просто сравнивать векторы двух сетей, в онлайн-сети добавляется специальный блок — «предиктор» (Q). Он пытается предсказать выход целевой сети .
Янник Кильхер называет этот механизм «умным самообманом»: предиктор должен угадать, как выглядит представление того же изображения, но под другим углом и обработанное чуть более «старой» версией той же сети . Это заставляет систему игнорировать шум трансформаций и фокусироваться на инвариантной семантике объекта .
🧪 Загадка отсутствия коллапса и результаты 21:42
Самым интригующим моментом для экспертного сообщества стал вопрос: почему BYOL не схлопывается в константу? Янник Кильхер признается, что точного теоретического ответа пока нет, и называет это «магией» . По его мнению, ключевую роль играет динамика обучения: сеть обновляется настолько маленькими шагами, что ей «проще» найти содержательное представление, чем сразу упасть в локальный минимум константного решения .
Результаты BYOL впечатляют:
- Алгоритм обходит предыдущие self-supervised методы (например, SimCLR) по точности .
- При увеличении количества параметров архитектуры результаты вплотную приближаются к классическому обучению с учителем (supervised baseline) .
- Метод гораздо устойчивее к уменьшению размера батча (batch size), тогда как контрастивные методы резко теряют в качестве при малых выборках .
Янник Кильхер подчеркивает, что избавление от негативных примеров упрощает жизнь разработчикам, так как отпадает необходимость в сложных техниках их подбора (hard negative mining) .
🤨 Критика DeepMind: Закрытость и «Broader Impact» 28:47
Несмотря на научную значимость, Янник Кильхер подвергает жесткой критике подход DeepMind к публикации материалов.
Проблема воспроизводимости: DeepMind не открыла исходный код BYOL, ограничившись «псевдокодом» в приложении к статье . Янник Кильхер считает это плохой практикой: «В их коде наверняка есть 50 миллиардов хаков... вы не сможете это воспроизвести без оригинального кода». Он вспоминает случай с псевдокодом MuZero, который содержал ошибки и был практически неработоспособен .
Формальные отчеты об этике: Особое возмущение автора вызвал раздел «Broader Impact Statement» (заявление о широком влиянии). Спикер зачитывает его, высмеивая канцеляризмы. По мнению Кильхера, текст настолько пустой и шаблонный, что его можно скопировать в любую статью по ИИ, заменив лишь название метода . Он отмечает, что такие разделы стали бесполезной формальностью, навязанной научными конференциями .
🚀 Будущее и ограничения 30:26
В финале обсуждения Янник Кильхер указывает на главную ахиллесову пяту BYOL — зависимость от экспертно подобранных аугментаций . Сейчас метод работает блестяще для компьютерного зрения, потому что мы знаем, что «вертикальный флип» или «кроп» не меняют суть кошки на фото. Однако для других типов данных (звук, текст, графы) подобрать такие трансформации крайне сложно. Автоматизация поиска аугментаций — это следующий необходимый шаг для развития этой технологии .