В течение последнего десятилетия ImageNet служил главным мерилом успеха в области компьютерного зрения, а ежегодное снижение частоты ошибок на этом датасете стало символом триумфа глубокого обучения. Однако исследователи Бенджамин Рехт, Ребекка Ролофс, Людвиг Шмидт и Вайшал Шанкар задались критическим вопросом: отражают ли эти цифры реальный прогресс в обобщении знаний или нейросети просто «зазубрили» конкретный тестовый набор данных?
📉 Испытание на прочность: создание ImageNet v2 0:00
На протяжении почти 10 лет сообщество ИИ обучало модели на ImageNet — гигантском архиве из 1,5 миллионов изображений, распределенных по 1000 классов. Янник Кильчер отмечает, что с 2012 года, когда AlexNet совершил революцию, показатели ошибок практически сокращались вдвое ежегодно. Но такая фиксация на одном и том же тестовом наборе порождает подозрения в «мета-переобучении» — ситуации, когда инженеры подбирают гиперпараметры и архитектуры специально под конкретные данные, теряя способность к работе с новыми примерами.
Чтобы проверить эту гипотезу, авторы исследования создали новый тестовый набор, названный ImageNet v2. Процесс сбора данных был выстроен максимально идентично оригинальному протоколу ImageNet:
- Источник: база данных Flickr.
- Иерархия: использование WordNet для классификации (например, «животное» -> «собака» -> «терьер»).
- Валидация: привлечение работников платформы Mechanical Turk для подтверждения наличия объекта нужного класса на фото.
Аналогичный эксперимент был проведен и для более простого датасета CIFAR-10.
🧪 Гипотеза против реальности 2:38
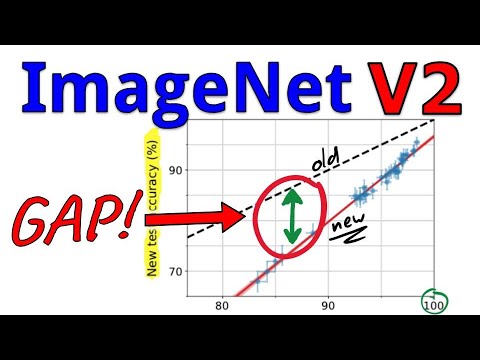
Основная гипотеза исследователей заключалась в том, что по мере улучшения результатов на оригинальном ImageNet (v1), разрыв с новым набором (v2) будет расти. Кильчер поясняет: если бы имело место классическое переобучение, графики точности моделей на v2 со временем начали бы отклоняться вниз или выходить на плато, пока точность на v1 продолжает расти.
Однако реальность оказалась иной:
- Линейная зависимость: результаты всех моделей на обоих датасетах ложатся на одну прямую.
- Сохранение рангов: лучшая модель на v1 остается лучшей и на v2. По словам Кильчера, порядок моделей практически неизменен.
- Падение точности: абсолютно все модели показывают результат на v2 значительно хуже (на 10–15% ниже), чем на v1.
Самым удивительным открытием стало то, что более точные модели испытывают меньший относительный спад при переходе на v2. Это противоречит идее переобучения: получается, что чем лучше нейросеть справляется с основным тестом, тем лучше она обобщает знания на новые данные.
🧩 В поисках причин: три типа разрывов в точности 9:13
Авторы предложили аналитическую модель, объясняющую разницу в результатах через три компонента:
- Generalization gap (Разрыв обобщения): разница между обучающей и тестовой выборкой из одного распределения. Исследователи исключили это как главную причину, так как доверительные интервалы (95%) дают разброс лишь в ±1%.
- Adaptivity gap (Адаптивный разрыв): то самое переобучение под тестовый сет из-за многократных попыток. Эта версия также была отвергнута из-за линейного характера графиков.
- Distribution gap (Разрыв распределения): различия в самих данных между старым и новым набором. Именно здесь, по мнению авторов, кроется разгадка.
🤖 Роль человеческого фактора и Mechanical Turk 12:14
Ключевой переменной оказалась «частота выбора» (selection frequency). Когда человеку на Mechanical Turk показывают сетку изображений и просят выбрать «терьеров», некоторые картинки выбирают все (частота 1.0), а некоторые — лишь часть людей.
Янник Кильчер объясняет, как это влияет на сложность датасета:
- Если выбирать изображения, которые получили 100% подтверждение от людей («топ-изображения»), точность моделей на v2 становится даже выше, чем на оригинале.
- Если пытаться в точности повторить порог сложности оригинала (Matched Frequency), модели всё равно проседают.
По мнению ведущего, даже при строгом соблюдении протокола 10-летней давности, современные условия сбора (другой контингент на Mechanical Turk, изменения в самом Flickr) создают «сдвиг распределения», который делает новые данные объективно более сложными для классификации.
🧮 Математическая модель сложности 20:09
Для объяснения феномена авторы ввели формальную модель, где каждое изображение имеет параметр сложности ($\tau$), а каждая модель — уровень навыка. Вероятность правильного ответа описывается как функция от разности навыка и сложности.
При использовании пробит-шкалирования (Probit scaling) выяснилось, что связь между точностью на v1 и v2 описывается строго линейной функцией. Это подтверждает, что разница вызвана не плохой архитектурой нейросетей, а фундаментальными свойствами данных.
💡 Рекомендации для будущего 23:33
Янник Кильчер с иронией отмечает предложение авторов использовать «Super Holdout» — секретный набор данных, который создается в начале карьеры и извлекается только в самом конце для финальной проверки модели.
В качестве дополнительного доказательства авторы провели эксперимент: они добавили часть данных из v2 в обучающую выборку. Несмотря на это, точность на оставшейся части v2 выросла лишь на мизерную величину, что подтверждает устойчивость выявленного «разрыва распределения».