Энергоэффективные вычисления: от CPUs к специализированным ускорителям 🚀 0:05
Современные вычислительные среды сталкиваются с жестким пределом энергопотребления из-за окончания эры масштабирования Деннарда (Dennard scaling) около 10 лет назад. Теперь увеличение количества транзисторов неизбежно ведет к росту энергопотребления, что заставляет инженеров искать пути повышения производительности через повышение энергоэффективности на операцию. В лекции Стэнфордского университета, посвященной аппаратной специализации в рамках курса CS149: Parallel Computing, рассматриваются подходы к переходу от универсальных процессоров (CPUs) к специализированным архитектурам.
Проблема неэффективности CPUs ⚡ 5:41
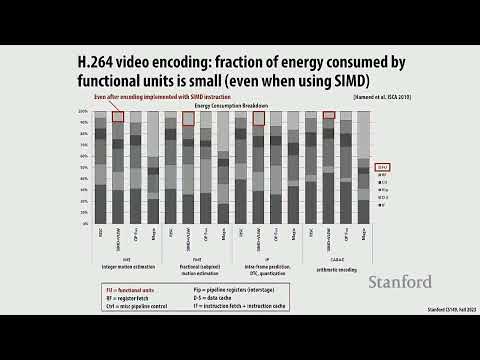
Основная проблема современных CPUs заключается в их фундаментальной неэффективности при выполнении инструкций. Согласно данным лекции, на непосредственно вычислительную операцию (например, multiply-add) тратится лишь около 6% энергии. Остальные ресурсы уходят на:
- Выборку инструкций и их декодирование.
- Контроль зависимостей между инструкциями.
- Поиск операндов и их перемещение из регистрового файла или кэшей.
- Контроль схемы и распределение тактового сигнала.
Применение SIMD (Single Instruction, Multiple Data) позволяет несколько улучшить эту ситуацию, амортизируя затраты на управление за счет выполнения одной операции над множеством данных. Однако, как отмечают лекторы, широкие SIMD-блоки сложно утилизировать: их пиковая производительность высока, но средняя — значительно ниже из-за невозможности заполнить все слоты.
Спектр вычислительных технологий 📉 21:13
Выбор архитектуры всегда представляет собой компромисс между энергоэффективностью и программируемостью.
- CPUs: Максимальная программируемость, но минимальная эффективность.
- GPUs: Хороши для параллельных вычислений, требуют написания кода на CUDA.
- DSPs (Digital Signal Processors): Высокая эффективность для конкретных задач (например, FFT) за счет комплексных инструкций, но крайне сложны в программировании (часто требуют ассемблера).
- Специализированные ускорители (ASICs): Дают прирост эффективности до 100-1000 раз, но требуют огромных затрат времени (около 18 месяцев на дизайн) и ресурсов.
- FPGAs (Field Programmable Gate Arrays): «Золотая середина», позволяющая перепрограммировать логические блоки, хотя работа с ними требует навыков аппаратного дизайнера.
Язык Spatial: Программирование ускорителей 💻 27:57
Для решения проблемы сложности разработки аппаратного обеспечения лектор представляет Spatial — доменно-специфичный язык программирования для дизайна ускорителей. В отличие от высокоуровневого синтеза (HLS) на базе C, который часто страдает от нагромождения прагм, Spatial позволяет performance-ориентированным программистам явно управлять:
- Параллелизмом: Независимым (map) и зависимым (pipeline parallelism).
- Локальностью и памятью: Программист сам определяет иерархию памяти (SRAM, DRAM), FIFOs и пересылку данных.
Streaming-модель и оптимизация внимания 🌊 54:26
Особое внимание уделяется «потоковой» (streaming) модели исполнения, которая позволяет достичь эффектов, схожих с FlashAttention, без необходимости написания сложных Fused-ядер. При kernel-по-ядерном подходе данные часто материализуются в промежуточных матрицах, что раздувает требования к памяти и пропускной способности. Потоковая модель через использование FIFOs позволяет соединять kernels в конвейер, где данные текут от одной операции к другой, не создавая полных промежуточных копий.




