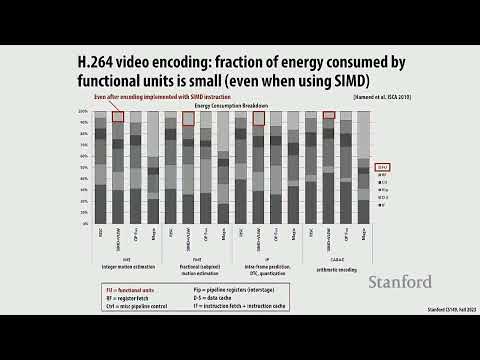
Короткий вводный абзац перед промежуточным экзаменом в Стэнфордском университете в рамках престижного курса CS149 по параллельным вычислениям превратился в глубокий аналитический разбор архитектурных компромиссов. Преподаватель вместе со студентами детально разобрал ключевые концепции эффективного программирования, начиная от мелкогранулярных блокировок и заканчивая тонкостями планирования потоков в графических чипах. На примерах из реальной практики ИТ-гигантов участники дискуссии наглядно продемонстрировали, почему бездумное масштабирование систем без учета локальности данных и пропускной способности шины неизбежно ведет к финансовому и техническому фиаско.
🚀 Обзор главных тем курса и подготовка к экзамену 0:05
Лекция предваряет промежуточный срез знаний и фокусируется на фундаментальных темах первой половины курса. Ключевой упор делается на понимание многоядерных архитектур и общих тактик оптимизации параллельных программ. Большая часть этих навыков, по словам преподавателя, приобретается студентами на практике в ходе выполнения лабораторных работ, где им приходится самостоятельно выявлять дисбаланс рабочей нагрузки (workload imbalance) и бороться с плохой производительностью процессорного кэша посредством изменения порядка циклов.
В список критически важных тем для текущего контроля вошли:
- Базовые принципы программирования на GPU и основы модели CUDA.
- Организация потоков внутри блоков (thread blocks).
- Логика работы протокола когерентности кэша MSI.
- Ослабленная консистентность памяти (relaxed memory consistency).
Преподаватель отдельно выделил тему глубоких нейронных сетей, пояснив, что ключевой вывод из нее — колоссальная важность локальности кэша и блочного форматирования (blocking). Однако подробный разбор специализированного аппаратного обеспечения будет отложен до финального экзамена.
Задачи на мелкогранулярные блокировки (fine-grained locking) на промежуточном экзамене будут носить упрощенный характер — например, на базе связанных списков. Более сложные структуры данных, такие как хэш-таблицы, графы и деревья, студенты будут детально прорабатывать позже.
🔒 Развеивая мифы о Lock-Free программировании: CAS и спекулятивные вычисления 4:03
До текущего момента синхронизация в рамках курса осуществлялась преимущественно через взаимные исключения (mutual exclusion) с помощью классических блокировок (locks). Взаимное исключение гарантирует, что определенный участок кода в конкретный момент времени может исполняться только одним потоком, принудительно останавливая всех остальных воркеров. Альтернативой выступают атомарные операции типа «чтение-модификация-запись» (read-modify-write). К ним относится и примитив Compare-and-Swap (CAS), работающий по принципу «чтение-сравнение-запись». Инструкция CAS проверяет значение переменной по указанному адресу: если оно совпадает с ожидаемым, происходит перезапись новым значением, в противном случае данные остаются неизменными.
На базе CAS можно реализовать атомарную операцию поиска минимума (atomic min) без использования стандартных блокировок. В традиционной модели программист захватывает лок, читает значение из памяти, сравнивает его, обновляет при необходимости и освобождает замок. В парадигме lock-free (без блокировки потоков) взаимное исключение для всей операции вычисления минимума не применяется. Несколько потоков могут параллельно считывать одно и то же значение из памяти и одновременно проверять свои условия.
Логика lock-free программирования строится на предикатах. Алгоритм проверяет, остается ли верным исходное условие, на основе которого поток пришел к своему итоговому результату, в момент непосредственной записи этого результата обратно в память. Процесс выглядит следующим образом:
- Поток считывает старое значение из памяти.
- Выполняются необходимые математические вычисления (например, расчет минимума).
- Вызывается атомарная инструкция CAS, которая сверяет текущее состояние памяти со старым значением. Если за время вычислений никто другой не обновил ячейку, запись признается успешной.
В основе концепции lock-free лежит спекулятивный подход. Потоки работают параллельно в надежде, что конфликта за данные не возникнет, и проверяют эту гипотезу в самый последний момент перед фиксацией изменений. По мнению лектора, ключевое ментальное различие заключается в том, что lock-free вычисления лишь создают видимость результатов взаимного исключения, не навязывая его физически на этапе расчетов.
Однако у спекуляций есть своя цена. Если проверка CAS проваливается из-за того, что другой поток успел обновить ячейку памяти, текущему потоку приходится заходить на новый круг выполнения цикла while. Вся проделанная им работа попросту выбрасывается. Преподаватель предупреждает, что если вместо простого вычисления минимума будет выполняться дорогостоящая функция (например, возведение в степень), накладные расходы от впустую потраченных ресурсов могут стать критическими.
Отвечая на вопрос студентов о рисках голодания (starvation) потоков при lock-free подходе, лектор пояснил, что сама по себе эта модель ортогональна понятию справедливости (fairness) распределения ресурсов. Без внедрения специальных алгоритмов (вроде экспоненциальной задержки — exponential backoff) риски вечной борьбы за ресурс одинаковы как для lock-free, так и для классических атомарных блокировок.
🚌 Накладные расходы атомарных примитивов на уровне системной шины 13:28
Специфика аппаратной реализации атомарных операций CAS напрямую связана с протоколами когерентности кэша. Даже если операция сравнения в CAS оказывается неудачной и фактического обновления данных в памяти не происходит, вызов этой инструкции все равно инициирует дорогую транзакцию записи на системной шине — BusRdX (Bus Read Exclusive).
В архитектурах без встроенной аппаратной поддержки когерентности для реализации атомарности инженерам пришлось бы создавать сложную логику изоляции конкретного адреса памяти на время транзакции. В когерентных же системах процессор, отправляя запрос BusRdX, помещает строку данных в свой кэш. Логика протокола гарантирует, что ни один другой процессор не сможет «вырвать» эту кэш-строку до тех пор, пока текущее ядро не завершит цикл сравнения и потенциальной записи. Без такой жесткой фиксации на уровне железа система мгновенно свалилась бы в состояние живой блокировки (live lock), когда несколько ядер бесконечно запрашивали бы друг у друга одну и ту же строку по шине, не успевая выполнить саму инструкцию записи.
📊 Эволюция распределенных данных: от MapReduce к Spark и обратно на серверы 16:04
Рассматривая распределенные параллельные вычисления, лектор обратился к истории появления модели MapReduce, разработанной инженерами Google в начале 2000-х годов. На тот момент перед компанией стояла задача обрабатывать колоссальные объемы текстовых данных (например, поисковые логи Apache или весь индекс веб-страниц), распределенные по тысячам серверов в рамках файловой системы GFS и базы данных Bigtable.
Интерфейс MapReduce подкупал своей лаконичностью и состоял всего из двух ключевых функций, вдохновленных функциональным программированием:
- Map: Применяет заданную функцию к каждой строке распределенного файла непосредственно на той машине, где эти данные физически хранятся. На выходе генерируется пара «ключ-значение».
- Reduce: Принимает уникальный ключ и список всех ассоциированных с ним значений, после чего выполняет финальную агрегацию (например, подсчет количества совпадений).
Главной инновацией и одновременно «узким горлышком» MapReduce стал жестко зашитый в API этап перераспределения данных — тасовка (shuffle или group by key). Все сгенерированные функциями Map пары с одинаковыми ключами физически перемещались по сети и группировались в отдельные файлы на распределенной дисковой системе. Транспортом для обмена данными выступала сама параллельная файловая система.
Позже создатели фреймворка Spark назвали такой подход неэффективным и предложили осуществлять все операции группировки и трансформации данных непосредственно в оперативной памяти (in-memory), расширив набор операторов.
В контексте распределенных систем преподаватель призвал студентов разделять понятия задержки (latency) и пропускной способности (bandwidth). В условиях массивного параллелизма задержки отдельных дисковых операций можно эффективно скрывать: пока система ожидает данные для текущего ключа, потоки могут параллельно обрабатывать или загружать информацию для следующего. Настоящей проблемой становится именно пропускная способность шины и дисков, когда терабайты данных вынужденно мигрируют туда и обратно между фазами вычислений.
Очарование массивным параллелизмом часто заставляет разработчиков забывать о локальности данных. Лектор привел в пример известное исследование, авторы которого наглядно продемонстрировали, что одно ядро обычного ноутбука может превзойти по производительности кластер из 5000 узлов Spark при обработке датасета объемом 500 гигабайт. Весь этот массив данных сегодня легко помещается в оперативную память одного сервера. По состоянию на 2023 год аренда мощного облачного инстанса AWS с 512 ГБ ОЗУ обходилась всего в 3 доллара в час. Для абсолютного большинства бизнес-задач гораздо разумнее купить одну или несколько крупных машин и максимально задействовать локальность памяти, нежели инвестировать в сложнейшую отказоустойчивую инфраструктуру на тысячи мелких узлов.
Ярким подтверждением этого тезиса стал официальный блог-пост команды инженеров Amazon Prime Video. Изначально они построили свою систему обработки видеостриминга на базе модных бессерверных микросервисов AWS Lambda. Однако из-за колоссальных накладных расходов на сетевые коммуникации между тысячами крошечных контейнеров команда приняла решение вернуться к классической архитектуре на базе нескольких крупных монолитных серверов. Результат оказался ошеломляющим: при сохранении прежнего уровня производительности затраты на инфраструктуру снизились в 10 раз (10x lower cost). Каждые лишние сетевые коммуникации в любой системе неизбежно оборачиваются финансовыми потерями.
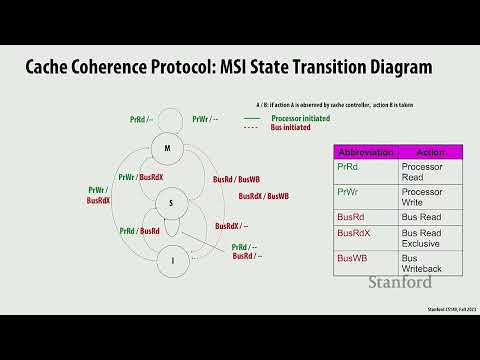
🔄 Живой практикум: пошаговая симуляция протокола когерентности MSI 30:24
Для демонстрации работы классического трехсостоятельного протокола когерентности кэша MSI преподаватель провел интерактивный эксперимент, пригласив двух студентов к доске в качестве живых моделей «Кэша 0» и «Кэша 1».
В рамках протокола MSI каждая строка кэша может находиться в одном из трех состояний:
- Invalid (I): Данные невалидны или отсутствуют.
- Shared (S): Данные доступны только для чтения, аналогичные копии могут быть у других ядер.
- Modified (M): Данные изменены локальным ядром, копия в оперативной памяти устарела, другие ядра не имеют доступа к строке.
Симуляция последовательного выполнения команд процессорами наглядно показала внутреннюю кухню когерентности:
- Процессор 0 запрашивает чтение (load) переменной X. Кэш 0 отправляет запрос по шине и переводит строку в состояние Shared (S).
- Процессор 0 снова читает X. Никаких сообщений по шине не отправляется. Состояние Shared гарантирует, что никто другой не изменил данные, и локальное чтение абсолютно бесплатно.
- Процессор 0 выполняет запись (store) в X. Кэш 0 уведомляет систему о намерении совершить запись, переводит строку из состояния S в Modified (M) и обновляет значение до «1». При этом в оперативной памяти значение X все еще остается старым — «0».
- Процессор 0 повторно пишет в X (значение «2»). Никакого трафика по шине снова нет, так как Кэш 0 уже обладает монопольным правом на модификацию строки.
- Процессор 1 инициирует запись в X. Кэш 0 фиксирует этот запрос, принудительно сбрасывает (flush) измененное значение «2» обратно в оперативную память и переводит свою строку в состояние Invalid (I). Процессор 1 считывает актуальные данные из памяти и обновляет их до «3», переводя свой кэш в состояние Modified.
В ходе игры один из студентов принудительно перевел свой кэш в Invalid вместо сохранения состояния Shared. Лектор подчеркнул, что с точки зрения корректности когерентности система отработала без ошибок, но возникла архитектурная неэффективность. Память была вынуждена совершать лишние циклы чтения-записи, хотя строка могла оставаться доступной для последующего быстрого чтения.
Любое изменение локального состояния кэша обязано сопровождаться широковещательным сигналом («криком») по системной шине. Информационные структуры других ядер должны вовремя корректировать свои состояния, чтобы не допустить чтения устаревших данных.
🧠 Оптимизация MESI и физическая природа кэш-строк 45:28
В современных процессорах от Intel и AMD базовый протокол MSI расширен до пяти состояний (включая MSF или MOSI). Ближайшей его эволюцией является протокол MESI, куда добавлено четвертое состояние — Exclusive (E).
Преимущество состояния Exclusive раскрывается в повсеместном сценарии «сначала прочитал, потом записал». В классическом MSI при первом чтении строка всегда становится Shared. Когда поток решает совершить запись, он обязан инициировать транзакцию по шине, чтобы объявить о своем намерении другим ядрам. Протокол MESI работает умнее: если при первом чтении ячейки процессор видит, что ни у кого больше этой строки нет, он маркирует ее как Exclusive (чистая копия, уникальная для данного ядра). Если впоследствии это же ядро решает записать туда данные, оно беззвучно переводит статус строки из E в M. Никаких сигналов по шине не отправляется, что колоссально экономит общую пропускную способность системы. Переход из Shared обратно в Exclusive невозможен без принудительной инвалидации всех остальных участников.
Преподаватель акцентировал внимание на важном аппаратном нюансе: когерентность всегда оперирует целыми строками кэша (cache lines), а не отдельными переменными. Если строка содержит обновленную переменную X, при ее сбросе (flush) в память отправляется вся строка целиком. Когерентность работает обособленно для каждого адреса строки, и разные адреса никак не влияют на логику состояний друг друга. Единственное исключение — ситуации, когда загрузка новой переменной Y вызывает физическое вытеснение (eviction) старой строки X из переполненного локального кэша, что заставляет строку X досрочно сбросить данные в память и уйти в Invalid.
⏱️ Разница между когерентностью и консистентностью памяти 55:11
В рамках курса студентам необходимо жестко разграничивать понятия когерентности и консистентности.
- Когерентность: Определяет логику работы системы с операциями над одним и тем же адресом памяти.
- Консистентность (согласованность): Задает правила упорядочивания эффектов от операций над разными адресами памяти. Это абсолютно ортогональные концепции.
В рамках одного изолированного потока современные суперскалярные процессоры и компиляторы могут выполнять инструкции out-of-order (не по порядку) для оптимизации скорости. Однако семантика программы гарантирует, что конечный результат всегда будет строго соответствовать исходному программному порядку (program order). Ослабленная консистентность памяти (relaxed consistency) становится видимой исключительно тогда, когда один процессор начинает наблюдать за операциями записи, производимыми другим процессором. Например, при допущении reordering-эффектов типа «запись-запись» (write-write) стороннее ядро может увидеть изменение переменной Y раньше, чем переменной X, хотя в коде первого потока их инициализация шла в обратном порядке.
🧮 Параллельные примитивы: концепция сегментированного сканирования 1:01:42
В блоке функционального параллельного мышления лектор кратко разобрал математическую суть операции сегментированного сканирования (segmented scan). По сути, это выполнение независимых локальных операций сканирования (например, расчета эксклюзивной суммы) над последовательностью, состоящей из нескольких подпоследовательностей (сегментов).
Пример работы эксклюзивной суммы над двумя сегментами (длиной в 3 и 5 элементов):
Исходный массив: [1, 2, 3] [4, 4, 7, 7, 8]
Результат скана: [0, 1, 3] [0, 4, 8, 15, 22]
Описанный в лекционных материалах алгоритм позволяет рассчитывать подобные сегментированные цепочки с параллельной сложностью порядка $O(n)$, где $n$ — суммарная длина всех имеющихся подпоследовательностей. Для успешной сдачи экзамена студентам не требуется заучивать детальный код реализации примитива на низком уровне, однако они должны уметь использовать сегментированный скан в качестве готового строительного блока при проектировании сложных алгоритмов высокого уровня.
🏎️ Глубокое погружение в CUDA: логика планировщика и природа SIMD 1:03:52
Архитектура CUDA представляет собой систему массового группового запуска задач (bulk launch system). Ее концепция во многом перекликается со встроенной системой задач, которую студенты реализовывали во второй лабораторной работе (например, ISPC). Команда на запуск ядра CUDA содержит два ключевых параметра: количество независимых блоков потоков ($n$) и число параллельных потоков внутри каждого блока ($T$).
Каждый потоковый мультипроцессор (SM) на кристалле графического процессора обладает жестко лимитированным набором аппаратных ресурсов — контекстов выполнения (execution contexts) для потоков и фиксированным объемом быстрой разделяемой памяти (shared memory). Планировщик GPU распределяет блоки на основе их ресурсных аппетитов.
В качестве примера была рассмотрена конфигурация, где программе требуется 128 потоков на блок и чуть более 512 байт разделяемой памяти. Если аппаратный SM поддерживает контексты для 384 потоков, то с точки зрения вычислительных мест на чип могли бы одновременно зайти 3 блока ($384 / 128 = 3$). Однако, если суммарный объем shared memory физически ограничивает одновременное размещение более двух блоков, планировщик сможет запустить на данном SM только 2 блока. В данном сценарии именно разделяемая память выступает главным ограничивающим фактором (bottleneck) для утилизации чипа.
Аппаратный планировщик NVIDIA всегда стремится распределять блоки по разным ядрам (SM) равномерно (например, Block 0 на SM 0, Block 1 на SM 1), вместо того чтобы максимально плотно забивать потоками один вычислительный узел. Если распределить два тяжелых блока по 128 потоков на один SM со слабой 32-битной векторной шириной, потоки будут вынуждены постоянно конкурировать за одни и те же локальные исполнительные устройства (ALU), в то время как соседние мультипроцессоры будут простаивать. Как только один блок завершает свою работу, планировщик мгновенно заполняет освободившийся ресурсный контекст следующим блоком из общей очереди.
Внутри каждого блока потоки нарезаются планировщиком на фиксированные группы по 32 штуки — так называемые варпы (warps). Варп — это базовая неделимая единица SIMD-выполнения на GPU. Все 32 потока внутри варпа синхронно выполняют одну и ту же инструкцию на линиях ALU в один и тот же такт частоты.
Преподаватель выделил фундаментальное архитектурное различие между векторным выполнением на CPU и GPU:
- На CPU (SIMD): Ответственность за генерацию векторных инструкций заданной ширины (например, 64-wide в ISPC) целиком лежит на компиляторе. Архитектура жестко привязана к ширине регистра.
- На GPU (SIMT): Компилятор генерирует обычный последовательный скалярный код для абстрактного потока. Задача объединения этих потоков в физические 32-wide векторы полностью переложена на аппаратную часть графического чипа. Благодаря этому NVIDIA сохраняет за собой право в будущих поколениях GPU менять физическую ширину аппаратных ALU, сохраняя полную бинарную совместимость старого софта.
Более того, современные графические процессоры научились аппаратно перегруппировывать потоки прямо на лету (rearrange), чтобы частично восстанавливать SIMD-когерентность при сильной дивергенции (расхождении) потоков внутри условных операторов if-else. Конкретные алгоритмы этой динамической оптимизации, по словам лектора, являются строжайшей коммерческой тайной корпорации и не раскрываются в официальной документации.