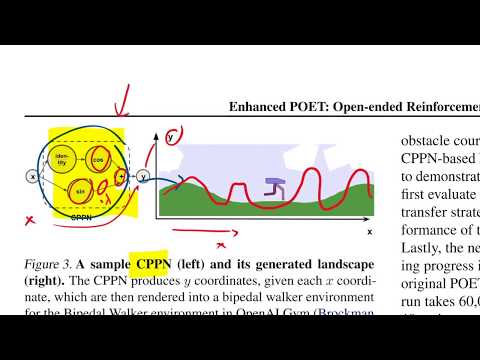
Язык как ключ к обучению: новый взгляд на исследование в Reinforcement Learning 0:01
Обучение агентов с подкреплением (Reinforcement Learning, RL) в средах с редкими наградами — одна из главных «головных болей» в машинном обучении. В таких условиях агент вынужден самостоятельно искать способы прогресса, часто сталкиваясь с тем, что простого случайного исследования недостаточно. Исследователи из Стэнфордского университета, Вашингтонского университета, Meta AI и Университетского колледжа Лондона предложили элегантное решение: использовать естественный язык как инструмент абстракции для внутренней мотивации агента. Янник Килчер в своем обзоре подробно разбирает, как именно добавление лингвистических описаний позволяет агентам более эффективно осваивать сложные долгосрочные задачи.
🧩 Проблема разреженных наград и внутренняя мотивация 1:09
В задачах с «разреженными» наградами агент редко получает сигнал о правильности своих действий. Для выживания и обучения ему необходима внутренняя мотивация — своего рода «любопытство», заставляющее исследовать окружающий мир.
Как отмечает Янник Килчер, основной вызов здесь заключается в том, чтобы отличить «осмысленное» исследование от бессмысленного.
- Косметическая новизна vs. Семантическая новизна: Состояния среды могут выглядеть по-разному (например, из-за процедурной генерации), но иметь одинаковый смысл. Агент, который просто «охотится» за новинкой, рискует зациклиться на случайных визуальных шумах.
- Роль языка: Язык помогает абстрагироваться от деталей и сфокусироваться на семантике. Фразы вроде «подобрать ключ» или «открыть дверь» описывают задачи, которые понятны и важны, в отличие от простого перемещения координат (x, y).
🛠 Методология: улучшение алгоритмов AMIGO и NovelD 8:26
Авторы не создают алгоритм с нуля, а показывают, как «усилить» уже существующие State-of-the-Art подходы — AMIGO и NovelD — с помощью языковых описаний.
Адаптация AMIGO (Adversarially Motivated Intrinsic Goals) 9:06
AMIGO использует архитектуру «учитель — ученик». Учитель ставит цели, а ученик пытается их достичь.
- Оригинальный метод: Учитель оперирует координатами, ставя цели вида «достигни точки (x, y)».
- Языковая версия: Теперь учитель предлагает цель в виде текстового описания (например, «состояние, где есть кристаллический жезл»).
- Grounding Network: Авторы добавили специальную сеть, которая проверяет, достижима ли предложенная цель в текущем состоянии, что помогает отсеивать невозможные задачи.
Адаптация NovelD (Novelty Driven) 23:02
NovelD вознаграждает агента за переход из состояния низкой новизны в состояние высокой новизны.
- Random Network Distillation (RND): Для оценки новизны состояния авторы используют случайную нейросеть. Агент пытается предсказать выход этой «замороженной» случайной сети. Большая ошибка прогноза означает, что состояние для агента ново.
- Интеграция языка: Авторы применили аналогичный подход к языковым описаниям, используя отдельную сеть для кодирования текста. Агент получает бонус, если описание текущего состояния «ново» с лингвистической точки зрения.
🔍 Критический анализ и выводы 31:51
Янник Килчер выражает определенный скепсис относительно чистоты эксперимента. По его мнению, успех метода во многом обусловлен тем, что в среду добавляется дополнительная качественная информация (человеческие описания), которой раньше не было.
- Преимущество данных: Языковые описания — это фактически «взгляд» на внутреннее состояние игрового движка, доступный агенту.
- Опора на оракулы: В текущей работе используется «оракул» (движок игры, выдающий описание). В реальности получить такие данные сложно.
- Перспективы: Килчер считает, что настоящим прорывом станет использование больших языковых моделей (LLM) для автоматического описания состояний, что позволит отказаться от предзаданных оракулов.
Несмотря на критику, ведущий признает: сама идея использовать язык для структурирования целей агента — это шаг к тому, как обучаются люди, постоянно обсуждая свои задачи и абстрактные концепции.