Исследование Google Brain под названием «Big Self-Supervised Models are Strong Semi-Supervised Learners» переворачивает привычные подходы к полуавтоматическому обучению (semi-supervised learning) в области компьютерного зрения. Известный ИИ-исследователь и блогер Янник Килчер (Yannic Kilcher) подробно разбирает архитектуру SimCLRv2, демонстрируя, как комбинация самообучения, тонкой настройки и дистилляции позволяет превзойти классические модели с учителем. Главный вывод работы парадоксален: вопреки традиционным представлениям, увеличение масштаба нейросети при дефиците размеченных данных не ведет к переобучению, а, наоборот, резко повышает точность классификации.
🔄 Смена парадигмы: от совместных лоссов к трехэтапному конвейеру 0:00
В сфере машинного обучения разметка данных остается одной из самых дорогих и трудоемких операций. Представьте типичную ситуацию: компания собрала огромный массив изображений, но обладает бюджетом всего в 500 долларов для платформы Amazon Mechanical Turk. В итоге размеченной оказывается лишь малая часть датасета, например, 10%. В таких условиях инженеры вынуждены прибегать к полуавтоматическому обучению. В компьютерном зрении этот подход долгое время развивался иначе, чем в обработке естественного языка (NLP), где модели сначала обучаются на гигантских массивах текста вроде Википедии, а затем адаптируются под конкретную задачу.
Традиционные методы полуавтоматического обучения пытались решать проблему «в один присест». В рамках одного мини-батча объединялись размеченные и неразмеченные примеры, а функция потерь (loss function) балансировала между ними, используя, например, штрафы за несогласованность для ближайших соседей в пространстве признаков. Однако авторы рассматриваемой статьи предлагают принципиально иной, трехэтапный конвейер:
- Этап 1: Неконтролируемое (задачно-агностическое) предобучение на всем объеме данных.
- Этап 2: Тонкая настройка (fine-tuning) с учителем на имеющемся малом проценте размеченных примеров.
- Этап 3: Дистилляция знаний с использованием неразмеченного массива для закрепления и переноса опыта.
🧠 Этап 1: Контрастивное самообучение без разметки 5:26
На первом этапе алгоритм SimCLRv2 полностью игнорирует метки классов, даже если они доступны для части выборки. Обучение строится на базе контрастивной функции потерь (contrastive loss). Процесс устроен следующим образом: из исходного массива случайным образом формируется мини-батч изображений, после чего каждое из них подвергается двукратной аугментации. Модификация включает в себя случайное кадрирование (random crop), цветовую дисторсию (color distortion) и размытие по Гауссу (Gaussian blur).
В результате для каждого исходного кадра создаются две слегка измененные, но семантически идентичные версии. Задача нейросети — пропустить эти изображения через кодировщик и выдать векторные представления Z1 и Z2. Функция потерь заставляет векторы, полученные из одного и того же изображения, максимально сближаться в пространстве признаков, в то время как представления векторов абсолютно других картинок (Z3) безжалостно отталкиваются друг от друга.
Помимо базовой механики, в SimCLRv2 интегрированы дополнительные инженерные решения, такие как механизм импульсного кодировщика (momentum encoder) из архитектуры MoCo. Практика показывает, что полученные таким образом представления обладают огромной ценностью. Если поверх обученной без учителя сети зафиксировать простейший линейный классификатор, точность распознавания на ImageNet оказывается поразительно высокой. Модель учится понимать структуру объектов, просто анализируя, принадлежат ли фрагменты одному исходному кадру или разным.
⚙️ Этап 2: Обучение с учителем и хитрость с проекционной головой 10:48
Когда сеть научилась извлекать качественные признаки, наступает фаза классического обучения с учителем на ограниченном подмножестве данных. Базовой архитектурой здесь выступает стандартная ResNet-50 или ее увеличенные модификации. Однако ключевое технологическое отличие второй версии SimCLR от первой кроется в работе с так называемой проекционной головой (projection head).
В первой версии SimCLR многослойные перцептроны (MLP), сжимающие размерность признаков с 2048 до 256 для вычисления контрастивного лосса, полностью выбрасывались перед тонкой настройкой. В SimCLRv2 авторы используют трехслойную проекционную голову и экспериментально доказывают, что тонкую настройку эффективнее начинать не с самого выхода ResNet, а сохранив первый слой проекционной головы.
Янник Килчер иронично отмечает, что авторы делают из этого шага «событие планетарного масштаба». По мнению ведущего, здесь нет фундаментального прорыва: инженеры просто сделали базовую модель на один слой глубже и назвали это «новой функцией кодировщика». Тем не менее, эмпирические результаты подтверждают, что сохранение промежуточных слоев проекционной головы при fine-tuning существенно улучшает итоговые метрики.
🧪 Этап 3: Дистилляция знаний с помощью неразмещенного массива 13:43
Третий шаг конвейера — это дистилляция знаний (knowledge distillation) или самообучение (self-training). Классическая дистилляция применяется, когда необходимо перенести опыт огромной, тяжелой модели-«учителя» в компактную модель-«ученика» для последующего развертывания на мобильных устройствах. Вместо жестких меток классов («собака» или «кошка») учитель генерирует для изображений мягкое вероятностное распределение (например, 90% за один класс, 10% за другой). Эти «псевдометки» передают ученику тонкие нюансы и взаимосвязи между классами, которые невозможно уловить из обычной жесткой разметки.
В SimCLRv2 этот метод приобретает особую силу благодаря повторному использованию огромного массива неразмеченных данных. Алгоритм выглядит так:
- Обученная на предыдущих этапах модель замораживается и выступает в роли учителя.
- Весь массив неразмеченных данных пропускается через учителя для получения мягких предсказаний.
- Модель-ученик обучается воспроизводить эти предсказания на тех же неразмеченных данных.
Удивительно, но дистилляция работает превосходно, даже если ученик имеет тот же размер, что и учитель (процесс самодистилляции). По словам Янника Килчера, точные теоретические причины, почему дистилляция улучшает модели равного масштаба, до сих пор остаются загадкой для науки. Однако в данном сценарии прагматический выигрыш очевиден: ученик получает возможность «спросить» учителя обо всем неразмеченном датасете, за счет чего интегрирует в себя колоссальный объем фоновых знаний о структуре изображений. Исследования авторов доказывают, что проведение дистилляции исключительно на размеченной выборке дает гораздо более слабые результаты, чем задействование всего неразмеченного пула.
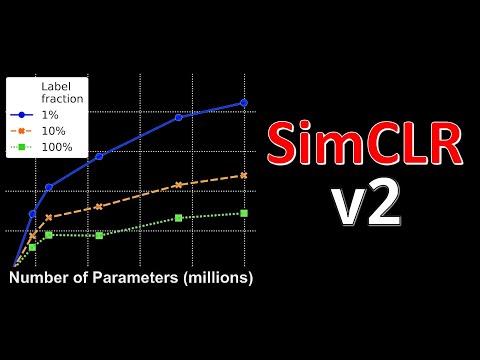
📈 Парадокс масштаба: почему гигантские модели не переобучаются 22:29
Экспериментальная часть исследования демонстрирует впечатляющие цифры. При наличии всего 1% размеченных данных ImageNet (что соответствует примерно 13 или менее изображениям на один класс) большая модель ResNet, обученная по трехэтапному конвейеру, вплотную приближается к результатам базовой supervised-модели, обучавшейся на 100% размеченного датасета. Если же алгоритму доступно 10% меток, SimCLRv2 уверенно обходит классический supervised-аналог, у которого были все 100% меток.
Главный теоретический посыл статьи вынесен в ее заголовок: крупные модели получают наибольшее преимущество именно тогда, когда тонкая настройка производится на экстремально малом количестве примеров. На grafikach зависимости относительного улучшения точности от числа параметров четко видно: чем меньше меток доступно инженерам, тем выше взлетает кривая эффективности при увеличении размера сети.
Янник Килчер подчеркивает, что данный феномен контринтуитивен. С точки зрения классической теории, огромная модель с сотнями миллионов параметров должна мгновенно переобучиться под скромную выборку из нескольких десятков картинок. Наблюдаемый обратный эффект ведущий объясняет через специфику предобучения:
- Когда меток очень мало, у нейросети математически остается крайне мало путей для выделения целевых признаков, а риск зафиксировать ложные корреляции возрастает.
- Гигантская модель на этапе самообучения без учителя (pre-training) успевает накопить колоссальное разнообразие универсальных признаков и паттернов, поскольку объем неразмеченных данных огромен.
- При последующей тонкой настройке на дефицитных метках у большой модели многократно возрастает шанс, что среди накопленного ею багажа абстракций уже есть именно тот идеальный признак, который необходим для решения задачи.
🎭 Ритуальные клятвы: критика разделов о социальном воздействии 34:19
В финале обзора Янник Килчер переходит к критике обязательного для современных научных публикаций раздела о «широком социальном воздействии» (Broader Impact Statement). Авторы работы пишут, что полуавтоматическое обучение способно повысить урожайность в сельском хозяйстве, спасти жизни людей благодаря улучшению диагностики в медицине, но одновременно несет риски создания опасных систем слежки и краткосрочной потери дохода для индустрии ручной разметки данных.
Ведущий откровенно высмеивает эти тезисы, задавая риторический вопрос: какая часть этого заявления реально отражает научную новизну конкретно этой статьи? По мнению Килчера, реальная связь здесь равна нулю. Данный фрагмент выглядит как стандартный шаблон, кочующий из работы в работу: если статья посвящена компьютерному зрению, в риски обязательно запишут дипфейки и тотальную слежку; если это обработка текста (NLP) — фейковые новости. Блогер выражает глубокое сомнение в том, что продвижение подобных искусственных и неконкретных регламентов действительно приносит пользу научному сообществу.




