В новом видео на своем канале Янник Килчер (Yannic Kilcher) подробно разбирает научную работу «Manifold Mixup: Better Representations by Interpolating Hidden States». Предложенный авторами метод является элегантным регуляризатором для нейронных сетей, который не только улучшает обобщающую способность моделей, но и делает их скрытые представления более структурированными и плоскими.
🌀 Проблема «извилистых» границ и избыточной уверенности 0:29
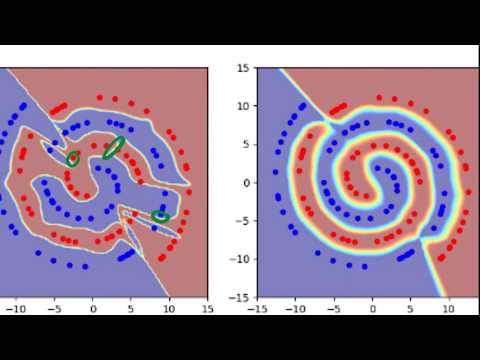
Стандартные нейронные сети, обучаемые методом контролируемого обучения (supervised learning), часто страдают от нескольких фундаментальных проблем, которые Янник Килчер наглядно демонстрирует на примере классической задачи со спиралями.
Основные недостатки обычных моделей:
- Нестабильные границы принятия решений: Вместо плавных линий нейросеть выстраивает «извилистые» и нерегулярные границы между классами.
- Избыточная уверенность (Overconfidence): В зонах, где тренировочные данные отсутствуют (например, в зазорах между витками спирали), модель все равно выдает предсказания с высокой степенью уверенности, вместо того чтобы сигнализировать о неопределенности.
- Близость границ к данным: Зачастую разделяющая поверхность проходит неоправданно близко к точкам обучающей выборки. Это происходит потому, что у нейросетей, в отличие от метода опорных векторов (SVM), нет встроенного стимула максимизировать зазор (margin) между классами.
Янник Килчер подчеркивает, что нейросети по своей сути работают как логистическая регрессия и не имеют механизмов, заставляющих их отодвигать границы подальше от данных.
🧬 Механика Manifold Mixup: как это работает 8:40
Суть метода Manifold Mixup заключается в интерполяции (смешивании) не только входных данных, но и их скрытых представлений (hidden states) на промежуточных слоях нейросети.
Процесс обучения выглядит следующим образом:
- Выбор слоев: Для каждого мини-батча случайным образом выбирается слой (включая входной), на котором будет происходить смешивание.
- Смешивание активаций: Берутся два разных мини-батча данных. Проводится прямой проход до выбранного слоя, после чего их скрытые представления линейно комбинируются с использованием коэффициента $\lambda$ (лямбда), который выбирается случайно в диапазоне от 0 до 1.
- Смешивание меток: Метки классов (labels) для полученного «смешанного» объекта также комбинируются в той же пропорции $\lambda$. Например, если мы смешали «кота» и «собаку» в пропорции 50/50, модель должна предсказать именно такой вектор вероятностей.
- Дальнейшее обучение: Смешанный сигнал проходит через оставшиеся слои сети, и ошибка вычисляется относительно смешанных меток.
По словам Янника Килчера, все операции в этом процессе дифференцируемы, что позволяет без проблем использовать метод обратного распространения ошибки через всю цепочку.
📊 Результаты: «сплющивание» представлений и SVD 6:03
Применение Manifold Mixup радикально меняет внутреннюю структуру модели. Янник отмечает три ключевых изменения:
- Гладкость границ: Решающие границы становятся намного более ровными, а зоны низкой уверенности (где модель «сомневается») — значительно шире, что лучше соответствует человеческой интуиции.
- Концентрация классов: В скрытом пространстве точки одного класса начинают группироваться теснее, а случайно выбранные точки (не из обучающей выборки) оказываются в центре, в зоне неопределенности.
- Снижение размерности (Flattening): Анализ сингулярных чисел (SVD) скрытых слоев показывает, что Manifold Mixup подавляет малые сингулярные значения. Это означает, что данные в скрытых слоях распределяются вдоль меньшего количества направлений, становясь более «плоскими».
Янник поясняет это на аналогии: если мы заставляем модель выдавать линейный результат для любой линейной комбинации точек, то оптимальным состоянием для сети будет «вытягивание» представлений в линию или плоскость.
🧐 Критика и теоретические аспекты 13:12
Авторы статьи приводят теоретические доказательства того, что при достаточно большом размере скрытых слоев минимизация функции потерь с Manifold Mixup приводит к тому, что модель становится линейной функцией от входа.
Однако Янник Килчер высказывает определенный скепсис по поводу применения этого метода к самым нижним слоям нейросети:
«Идея о том, что это можно применять к любому слою, кажется мне немного сомнительной (shady). Мы знаем, что входные многообразия (manifolds) данных обычно очень запутаны, а не линейны или плоски. Нейросеть должна распутывать их постепенно».
По мнению Килчера, принудительное «сплющивание» представлений на ранних этапах может противоречить естественной логике работы сверточных или глубоких сетей, хотя эмпирические результаты и подтверждают эффективность метода.
🛡️ Устойчивость к атакам и обобщение 19:12
Помимо улучшения точности на стандартных датасетах, таких как CIFAR-10 и CIFAR-100, Manifold Mixup значительно повышает устойчивость моделей к адверсариальным атакам.
Суть защиты в следующем:
- В обычной сети граница класса может находиться очень близко к реальной точке данных.
- Злоумышленник может добавить к изображению крошечный, невидимый глазу шум, который «перетолкнет» точку через эту границу.
- Поскольку Manifold Mixup отодвигает границы принятия решений далеко от обучающих примеров, адверсариальному шуму приходится быть гораздо более значительным, чтобы изменить предсказание модели.
В завершение Янник Килчер отмечает, что метод крайне прост в реализации и уже доступен во многих библиотеках. Он рекомендует разработчикам рассмотреть возможность его добавления в свой код для повышения надежности нейросетей.




