Основы сжатия данных: от энтропии до эффективных систем 0:05
В современном мире объем генерируемых данных растет в геометрической прогрессии, достигая десятков зеттабайт, что делает задачу их хранения и передачи критически важной. Курс Stanford EE274, который ведут профессор Цачи Вайссман и лекторы Шамбхам и Пулкит, посвящен фундаментальным аспектам теории сжатия данных. Основная идея курса заключается в том, что сжатие — это не просто «правой кнопкой мыши в ZIP», а процесс лаконичного представления информации, где допустимо отбрасывать второстепенное, сохраняя при этом суть сообщения.
📊 Масштабы данных и проблема их объема 1:36
Для понимания масштабов роста данных лекторы предложили проследить иерархию единиц измерения: от мегабайта (объем несжатого фото с телефона) до зеттабайта (21 ноль после единицы). С 2010 по 2023 год мир перешел от 2 до 64 зеттабайт данных.
Ключевые проблемы, связанные с этим ростом:
- Хранение: Компании тратят миллионы долларов на управление петабайтами данных в таких сервисах, как AWS S3 или Google Storage.
- Передача: Видеоконтент занимает около 50% интернет-трафика. Во время пандемии Netflix был вынужден оптимизировать алгоритмы сжатия по требованию регуляторов ЕС, чтобы предотвратить перегрузку сетей.
- Ограниченность: Существуют фундаментальные математические пределы того, насколько сильно можно сжать данные, известные как энтропия.
🔄 Компромиссы сжатия: скорость vs качество 11:01
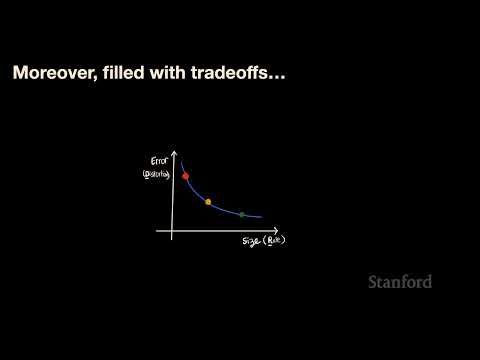
Сжатие всегда связано с поиском баланса между размером файла и допустимой потерей качества, что описывается «кривой скорость-искажение» (rate-distortion curve).
Примеры trade-offs в реальной жизни:
- Аудио: При сжатии музыкального файла с 5 МБ до 2,5 МБ часть слушателей не заметит разницы, однако дальнейшее уменьшение размера приводит к слышимым частотным искажениям, делая звук «резким» и неприятным.
- Видео: Стриминговые сервисы типа Spotify и Netflix позволяют пользователям выбирать между «высоким качеством» и «экономией данных», фактически предлагая перемещаться по упомянутой кривой.
По словам лекторов, выбор конкретных параметров сжатия — это дизайнерское решение, зависящее от области применения: от биомедицинских сенсоров, где жизненно важно передать сигнал без задержки, до систем управления версиями вроде GitHub, где сжатие объектов происходит незаметно в фоновом режиме.
🧠 Связь с машинным обучением 9:50
Между сжатием и современными моделями машинного обучения (LLM) существует двусторонняя связь. С одной стороны, ML используется для улучшения алгоритмов сжатия. С другой — методы сжатия, такие как квантование моделей (quantization), критически важны для запуска нейросетей (например, Llama) на пользовательских устройствах. Пулкит подчеркнул: хороший компрессор по сути является хорошим предсказателем, и наоборот.
📉 Основы сжатия без потерь (Lossless) 35:52
Первая половина курса сосредоточена на сжатии без потерь. Базовая концепция — использование кодов переменной длины: мы присваиваем более короткие последовательности бит тем символам, которые встречаются чаще.
Математический подход к оценке эффективности кода:
- Биты на символ: Мера того, сколько бит в среднем расходуется на один символ входных данных.
- Оптимизация: Даже если распределение вероятностей символов кажется похожим, фиксированный код (например, 2 бита на символ) проигрывает кодам с переменной длиной.
Лектор Шамбхам отметил, что, несмотря на сложность, эти основы позволяют доказать теоремы о невозможности сжатия данных лучше определенного предела, даже если у вас есть «бесконечные вычислительные мощности», что является одним из фундаментальных достижений теории информации.