За пределами iid: понимание условной энтропии и сжатия данных 📊 0:05
Лекция 8 курса Stanford EE274 посвящена фундаментальному переходу в теории сжатия данных: от работы с независимыми и одинаково распределенными (iid) данными к анализу сложных, зависимых последовательностей. Ведущий курса объясняет, почему классические методы сжатия, основанные на iid-предположениях, перестают быть оптимальными в реальном мире, где каждый последующий символ зависит от предыдущего контекста. В центре внимания — концепции условной энтропии, марковских цепей и энтропийной скорости (entropy rate), которые позволяют создавать более эффективные алгоритмы сжатия для текста, изображений и видео.
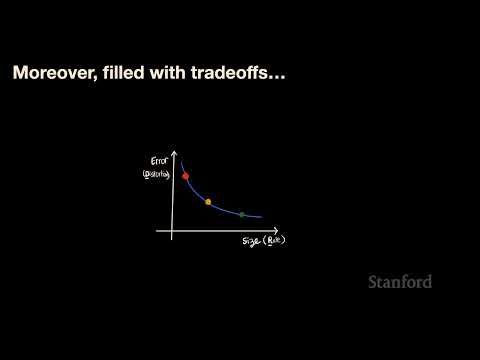
🧩 Итоги «турне» по энтропийным кодировщикам 0:33
Прежде чем углубиться в теорию, лектор подвел краткие итоги по изученным ранее методам сжатия, которые преобразуют данные на основе известного распределения вероятностей в битовый поток:
- Кодирование Хаффмана (Huffman coding): Самый быстрый метод, оптимален для отдельных символов, но при работе с блоками требует экспоненциального роста сложности для приближения к энтропии.
- Арифметическое кодирование (Arithmetic coding): Обеспечивает эффективность, близкую к энтропии, работая с данными как с единым блоком за линейное время. Основной минус — необходимость дорогостоящих операций деления.
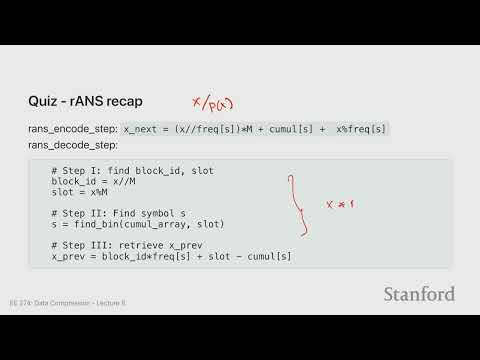
- ANS (Asymmetric Numeral Systems): Современная альтернатива, сочетающая скорость Хаффмана и эффективность арифметического кодирования. rANS и tANS стали крайне популярны благодаря эффективной реализации на современных CPU.
📉 Почему iid-предположение — это риск? 18:09
Попытка сжать литературное произведение, например, «Собаку Баскервилей» Артура Конан Дойля, демонстрирует ограничения теории, основанной на iid. Несмотря на теоретическую оптимальность энтропии, такие алгоритмы, как gzip и bzip2, показывают гораздо лучшие результаты, чем сжатие на основе эмпирической энтропии букв.
Причина кроется в том, что данные в реальном мире не являются независимыми:
- Структура языка: После буквы «Q» с очень высокой вероятностью идет «U». Заглавные буквы чаще встречаются в начале предложений.
- Пространственная корреляция: В изображениях соседние пиксели часто имеют схожие цвета, образуя однородные области (например, небо).
- Временная зависимость: В видео соседние кадры часто почти идентичны из-за медленного движения.
Лектор подчеркивает, что iid-модель предполагает независимость символов, тогда как в реальности распределение меняется от символа к символу в зависимости от прошлого.
⛓️ Марковские процессы и стационарность 25:14
Для моделирования реальных данных вводятся понятия случайных процессов с произвольными зависимостями:
- Стационарный процесс: Процесс, вероятностные характеристики которого (среднее, дисперсия, энтропия) инвариантны во времени. Где бы мы ни находились в последовательности — в начале или в миллионной позиции — распределение остается прежним.
- Марковский процесс: Процесс, где будущее состояние зависит только от текущего (состояние $n$ зависит только от $n-1$). Использование более глубокого прошлого не дает дополнительной информации для прогноза.
- Марковские источники $k$-го порядка: Обобщение, где текущий символ зависит от $k$ предыдущих.
Интересный практический прием: если данные имеют тренд (например, времена прибытия автобусов), их можно преобразовать в стационарный процесс, просто вычислив разницу между соседними значениями (т.н. delta coding).
⚖️ Условная энтропия и информация 49:28
Лектор вводит ключевое понятие условной энтропии $H(U|V)$ — меры неопределенности в переменной $U$, если нам уже известно значение $V$.
- Наличие знаний (условий) в среднем никогда не вредит сжатию — оно либо уменьшает неопределенность, либо оставляет её на прежнем уровне.
- Цепное правило энтропии: $H(U, V) = H(U) + H(V|U)$. Это означает, что для эффективного сжатия пары переменных мы можем сначала сжать $U$, а затем сжать $V$, используя знание $U$.
🏁 Энтропийная скорость: предел сжатия
Для стационарных процессов вводится понятие энтропийной скорости (entropy rate). Это среднее количество бит на символ, необходимое для сжатия при стремлении размера блока к бесконечности.
Лектор приводит классический эксперимент Клода Шеннона по оценке энтропии английского языка:
- iid-модель (0-й порядок): 4.76 бит на букву.
- 1-й порядок (учет предыдущей буквы): 4.03 бит на букву.
- 4-й порядок: 2.8 бит на букву.
- Человеческое предсказание: 1.3 бит на букву.
- Современные LLM: Показывают результаты еще ниже, становясь более сильными предикторами, чем человек.
Именно энтропийная скорость, согласно теореме Шеннона-Макмиллана-Бреймана, определяет фундаментальный предел сжатия для стационарных источников.