Dreamer v2: прорыв в обучении агентов с помощью дискретных моделей мира 0:00
Янник Килчер (Yannic Kilcher) представил детальный разбор научной статьи о Dreamer v2 — алгоритме обучения с подкреплением, который демонстрирует выдающиеся результаты в играх на платформе Atari, используя модель мира с дискретными латентными состояниями. Исследователи из Google Brain, DeepMind и Университета Торонто смогли создать агента, который не только эффективно обучается на одной графической карте, но и превосходит многие предыдущие подходы, включая как безмодельные (model-free), так и модельные (model-based) алгоритмы. Главная инновация заключается в переходе от непрерывных латентных переменных к категориальным, что позволяет модели более точно описывать состояние среды.
🧠 Что такое модель мира и зачем она нужна? 2:13
Традиционное обучение с подкреплением в модели model-free предполагает, что агент напрямую взаимодействует со средой, получая вознаграждения и корректируя свои действия. Однако этот путь требует колоссального количества проб и ошибок. В отличие от него, модельный подход (model-based) сначала строит «представление» о том, как работает мир, а затем использует эту внутреннюю модель для обучения.
По мнению Килчера, основное преимущество такого подхода — возможность «мечтать» (dreaming): агент может планировать действия и обучаться не в реальности, а внутри построенной модели, что кратно ускоряет процесс. Алгоритм Dreamer v2 автоматизирует этот процесс в два этапа:
- Обучение модели мира: Агент анализирует прошлый опыт, чтобы предсказывать следующие изображения (кадры игры) и вознаграждения.
- Обучение агента (Reinforcement Learning): Используя модель, агент «воображает» различные игровые сценарии и оттачивает стратегию без обращения к реальной среде.
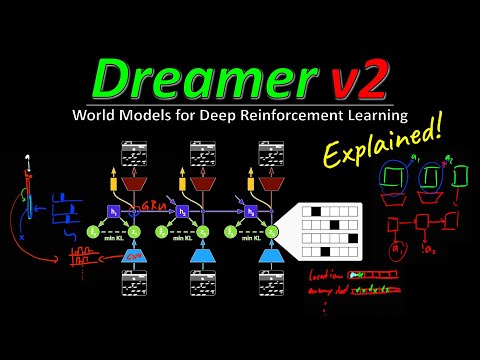
⚙️ Инновация: дискретные латентные состояния 3:19
Ключевым отличием Dreamer v2 от предшественников является структура латентного состояния. Если ранее исследователи использовали непрерывные переменные (гауссовы распределения), то в новой работе состояние моделируется как набор категориальных случайных величин.
- Структура данных: Агент оперирует 32 категориальными переменными, каждая из которых может принимать одно из 32 значений.
- Сжатие: Все входные изображения сжимаются в этот крайне компактный формат.
- Гипотеза: Янник Килчер предполагает, что такая высокая степень сжатия и дискретность заставляют модель фокусироваться на наиболее важных аспектах игры, например, на положении врагов или траектории их выстрелов.
Категориальные распределения, по мнению авторов статьи, лучше справляются с многомодальными ситуациями, где одно и то же действие может привести к разным последствиям.
⚖️ Сложности обучения и «баскет» гиперпараметров 39:10
Несмотря на эффективность, методология Dreamer v2 содержит огромное количество гиперпараметров. Килчер отмечает, что реализация алгоритма требует тщательной настройки:
- KL-балансировка: Важнейшая часть обучения, где модель должна найти компромисс между реконструкцией изображения и предсказанием будущих состояний без визуальных данных.
- Straight-through estimator: Техника, позволяющая пропускать градиент через операцию дискретного сэмплирования, что необходимо для оптимизации стохастических узлов.
- Графики обучения: Некоторые параметры (например, веса для прямого прохода градиентов) меняются в процессе тренировки по специальному расписанию.
📊 Результаты и критика 46:27
Dreamer v2 показывает впечатляющие результаты, достигая уровня профессиональных игроков в большинстве игр Atari. Однако Килчер выражает скепсис относительно универсальности алгоритма.
- Специфика Atari: Автор считает, что алгоритм «заточен» под структуру игр Atari, где изменение картинки почти всегда коррелирует с важным изменением состояния.
- Проблемы с визуальным шумом: Если в игре много изменений, не влияющих на прогресс (например, вспышки или фоновая анимация), модель может «запутаться», отдавая приоритет не тем объектам. Примером такого провала является игра Video Pinball.
- Оценка эффективности: Килчер отмечает спорность методик нормализации результатов, предлагая использовать «мировой рекорд человека» как более адекватный бенчмарк, чем усредненные показатели профессиональных геймеров.




