В рамках курса MIT OpenCourseWare профессор Филлип Изола представляет вводную лекцию, посвященную базовым принципам генеративных моделей и генеративного искусственного интеллекта. В материале подробно рассматривается математический аппарат теории вероятностей, лежащий в основе современных нейросетей, а также фундаментальные подходы к созданию синтетических данных. Автор сопоставляет ключевые современные архитектуры — авторегрессионные модели, диффуссионные модели и генеративно-состязательные сети (GAN), объясняя их внутреннюю взаимосвязь.
🔄 Обратная сторона репрезентативного обучения 0:12
Генеративные модели, получившие в последнее время широкую известность под общим названием «генеративный ИИ» (Generative AI), стали одной из главных технологических тем 2023 и 2024 годов. По мнению Филлипа Изолы, этот предмет вполне можно преподавать и без упоминания глубокого обучения, однако именно в сфере Deep Learning сейчас происходит основной массив важных инноваций. Профессор предлагает рассматривать генеративное моделирование как процесс, обратный репрезентативному обучению (representation learning). Если в предыдущие недели курса студенты изучали переход от сложных данных к низкоразмерным векторным представлениям (эмбеддингам), то теперь векторные представления служат отправной точкой для воссоздания данных.
Изучение генеративного ИИ в рамках академического курса рассчитано на три лекции. В текущем занятии рассматриваются фундаментальные принципы, диффузионные модели и сети GAN. На следующей лекции планируется подробный разбор вариационных автокодировщиков (VAE), способных объединять оба направления, а также условных моделей (conditional models). Наконец, завершающая лекция трилогии будет полностью посвящена практическому применению этих инструментов для решения реальных задач. Профессор Изола не скрывает своего личного отношения к теме, отмечая, что хотя его любимым направлением долгое время оставалось репрезентативное обучение, генеративное моделирование вызывает у него еще больший профессиональный интерес. По его мнению, генеративные модели находятся в самом сердце концепции искусственного интеллекта, что наглядно подтверждается текущей технологической революцией.
📊 Вероятностная математика и нейросети 2:35
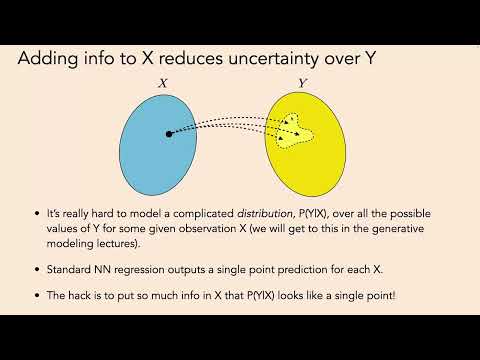
Для полноценного освоения генеративных архитектур требуется изменить привычный взгляд на работу нейронных сетей и обратиться к аппарату теории вероятностей. Ранее в рамках курса нейросети рассматривались преимущественно как классические математические функции, выполняющие детерминированное отображение из входного пространства в выходное. Такое отображение может быть типа «многие к одному» или «один к одному», но оно исключает ситуацию «один ко многим», когда одному входу соответствуют несколько вариантов выхода. В качестве примера классической функции профессор приводит стандартный классификатор изображений. На вход подается тензор размерности $N \times M \times C$ (где $C$ — количество цветовых каналов), а на выходе формируется конкретное целое число, обозначающее предсказанный класс.
Однако для генерации данных детерминированного подхода недостаточно. В генеративном контексте нейросеть рассматривается как отображение из входного пространства $X$ не в конкретный объект $Y$, а в пространство вероятностных распределений над объектами $Y$. По мнению Изолы, практически любые классические задачи машинного обучения можно переосмыслить с этой точки зрения.
В качестве примеров такого переосмысления автор называет:
- Задачу классификации (софтмакс-регрессию), где сеть предсказывает категориальное распределение вероятностей по всем доступным классам, отображая результат на симплекс.
- Бинарную классификацию, где распределение вероятностей между двумя классами можно визуализировать в виде отрезка (линейного симплекса).
- Обычную регрессию с минимизацией среднеквадратичной ошибки (L2-loss), которую математически можно представить как вывод Гауссова распределения, где сеть предсказывает математическое ожидание (среднее значение).
Профессор напоминает о концепции из лекции «Руководство хакера», согласно которой неопределенность выходных данных можно снизить, если подавать на вход больше контекстуальной информации. Но если у исследователя нет возможности расширить входные данные, ему приходится искать способы моделирования сложных, многомодальных выходных распределений напрямую.
🎲 Случайные величины и скрытые переменные 11:50
В теории генеративного моделирования случайные величины могут быть дискретными или непрерывными. Распределение дисктетной случайной величины описывается функцией вероятностной массы (probability mass function), где значения строго ограничены диапазоном от 0 до 1, а их сумма по всему пространству событий равна единице. Непрерывные величины описываются функцией плотности вероятности, которая интегрируется к единице, хотя плотность в конкретной точке может уходить в бесконечность. Отвечая на вопрос из аудитории о физическом смысле плотности в непрерывном пространстве, профессор поясняет, что вероятность строго определяется через интегралы по интервалам, но на практике математические тонкости теории меры часто опускают, интуитивно воспринимая плотность как относительную вероятность реализации значения.
Существует два основных способа репрезентации распределений нейросетями: сеть может либо выдавать готовые параметры распределения, либо непосредственно генерировать выборку (сэмплы) из него. Чтобы превратить стандартную детерминированную нейросеть в генератор, способный выдавать разнообразные результаты, её работу связывают со случайными величинами. Вводя в систему случайный вектор — метафорические «игральные кости» — разработчик получает разные исходы при каждом новом запуске.
Профессор Изола подчеркивает, что называть эти случайные величины «шумом» не совсем корректно, поскольку это может ввести в заблуждение. Этот шум не является бессмысленным компонентом, от которого нужно избавиться. Скрытые переменные (latent variables) фактически кодируют и предопределяют все характеристики будущего объекта, которые не были заданы явной командой пользователя.
В качестве примера с генерацией птицы скрытые переменные определяют:
- Видовую принадлежность и окрас оперения птицы.
- Угол поворота ее тела и ракурс съемки.
- Размер птицы в кадре и элементы фона.
Исторически схожие подходы развивались не только в статистике, но и в компьютерной графике, где они известны как процедурная генерация (procedural graphics) для создания карт, ландшафтов или текстур в играх. Изола демонстрирует это на примере интерактивного создания русла реки с помощью подбрасывания монеты в аудитории. Каждый бросок определяет, повернет ли русло реки влево или вправо на 10 градусов, формируя в итоге уникальный извилистый маршрут. Добавляя другие типы распределений, можно гибко настраивать параметры сцены: Гауссова случайная величина может задавать яркость травы, а равномерное распределение — количество деревьев на карте.
🎯 Прямой и косвенный подходы к обучению 23:45
В машинном обучении сформировались два принципиально разных подхода к построению генеративных алгоритмов: прямой и косвенный. При прямом подходе алгоритм сразу обучается функции, которая трансформирует входной шум в реалистичные объекты данных. В профессиональной литературе такие модели иногда называют неявными (implicit generative models), поскольку сама процедура генерации неявно задает итоговое сложное распределение. Модель тренируют на большом массиве реальных примеров с целью заставить её выдавать новые объекты, статистически неотличимые от обучающей выборки. Процесс эксплуатации такой модели вместо привычного термина «тестирование» называют фазой сэмплинга или инференса.
Косвенный подход, являющийся более классическим с точки зрения математической статистики, устроен иначе. Вместо генерации объектов модель учится оценивать их правдоподобие, формируя функцию оценки (scoring function). Эта функция присваивает высокие скалярные значения тем конфигурациям пространства, где плотность реальных данных высока, и низкие значения — аномалиям. Сэмплинг в косвенном подходе перестает быть одношаговым: для извлечения новых данных исследователям приходится использовать специальные поисковые алгоритмы оптимизации или стохастические методы, такие как марковские цепи Монте-Карло (MCMC) и выборка с отклонением (rejection sampling).
📈 Максимальное правдоподобие и проблема «картотечного шкафа» 29:11
Основная задача генеративного моделирования — создание синтетических объектов, которые отражают важные статистические свойства и реалистичные параметры исходных данных. Общепринятым стандартом для этого в машинном обучении стала максимизация функции правдоподобия. С математической точки зрения цель заключается в минимизации расхождения Кульбака — Лейблера (KL-divergence) между истинным, но неизвестным нам природным распределением данных $p_{data}$ и распределением нашей модели $p_\theta$. Путем математических преобразований исходная формула очищается от константной части, что позволяет перейти к максимизации логарифма правдоподобия модели на конечной обучающей выборке.
В ходе лекции профессор Изола разбирает важную проблему переобучения, иллюстрируя ее мысленным экспериментом под названием «картотечный шкаф» (filing cabinet). Представим модель, которая при обучении просто сохраняет каждый поступивший объект в отдельный файл внутри шкафа. В фазе сэмплинга этот алгоритм случайным образом выбирает один из ящиков и достает точную копию тренировочного примера. Подобная модель, по мнению аудитории, абсолютно бесполезна, поскольку она не способна создавать новые объекты, хотя формально максимизирует правдоподобие на обучающей выборке.
Следствиями переобучения в генеративном моделировании становятся:
- Формирование изолированных пиков (функций Дирака) вокруг точек обучающей выборки при избыточной емкости нейросети.
- Присвоение нулевой вероятности любым новым тестовым примерам, которые незначительно отличаются от тренировочных данных.
- Полное отсутствие генерализации, что эквивалентно провалу тестирования в классическом обучении с учителем.
Для предотвращения эффекта запоминания исследователям необходимо жестко контролировать емкость архитектуры или применять методы регуляризации. Качество генеративной модели оценивается по величине правдоподобия, которое она способна показать на отложенной валидационной или тестовой выборке.
⚡ Энергетические модели и контрастивная дивергенция 44:30
Энергетические модели (Energy-based models, EBM) представляют собой альтернативное развитие косвенного подхода. Их ключевое отличие заключается в том, что функция оценки выдает ненормализованную вероятность. Любое распределение из широкого класса функций можно выразить через распределение Больцмана, где вероятность пропорциональна экспоненте от отрицательной энергии объекта, деленной на нормализующую константу $Z$. Главный недостаток чистых вероятностных моделей заключается в необходимости вычисления интеграла по всему бесконечному пространству данных для нормализации распределения, что в большинстве практических задач является вычислительно неразрешимой проблемой.
Энергетические модели успешно обходят это ограничение, поскольку для принятия решений или генерации методом MCMC нормализующая константа не требуется — достаточно знать лишь соотношение энергий. Отношение экспонент двух энергий в точности равно отношению их истинных вероятностей, так как константы $Z$ взаимно уничтожаются.
Для обучения энергетической модели используется градиентный алгоритм контрастивной дивергенции (contrastive divergence). Если просто минимизировать энергию в точках обучающей выборки, система быстро придет к ошибочному решению, устремив показатели энергии к минус бесконечности по всему пространству. Математический трюк контрастивной дивергенции состоит в разделении градиента логарифма правдоподобия на два слагаемых.
Эти слагаемые представляют собой:
- Положительную фазу (positive term), которая уменьшает энергию (повышает вероятность) в точках реальной обучающей выборки.
- Отрицательную фазу (negative term), которая увеличивает энергию в точках, где сама модель на текущий момент ошибочно ожидает высокую вероятность.
Математический вывод градиента нормализующей константы $Z$ показывает, что этот сложный интеграл сводится к обычному математическому ожиданию градиента энергии по распределению модели. Это позволяет аппроксимировать интеграл через сэмплы, генерируемые самой моделью на каждом шаге обучения.
🔄 Авторегрессионные и диффузионные модели 59:19
Переходя к обзору популярных глубоких генеративных архитектур, профессор Изола выделяет общую стратегию: сведение сложнейшей задачи моделирования многомерного структурированного объекта к последовательности простых шагов. Первым примером служат авторегрессионные модели, работающие по принципу предсказания следующего токена на основе всего предыдущего контекста. Обучение происходит в режиме стандартного обучения с учителем как задача классификации, где каждый следующий элемент выбирается через софтмакс-регрессию.
Математическая легитимность авторегрессионного подхода базируется на цепном правиле теории вероятностей (chain rule of probability), согласно которому совместная вероятность вектора признаков распадается на произведение условных вероятностей его элементов. Профессор Изола однозначно классифицирует авторегрессионный подход как плотностную (density) модель, поскольку перемножение всех локальных условных вероятностей позволяет аналитически вычислить точную итоговую вероятность всего сгенерированного объекта.
Диффузионные модели (diffusion models) используют иную логику. Их авторы заметили, что превратить случайный шум в структурированное изображение крайне трудно, а вот превратить структуру в шум — тривиальная задача. В рамках прямого процесса к исходному изображению на каждом временном шаге последовательно добавляется небольшой объем Гауссова шума с заданным коэффициентом масштабирования.
Идея диффузионного подхода строится на следующих этапах:
- Создание обучающей выборки путем искусственного зашумления качественных исходных картинок.
- Обучение нейросети-денойзера, которая принимает на вход зашумленный объект и шаг времени $t$, пытаясь предсказать исходное состояние.
- Развертывание процесса в обратную сторону в фазе сэмплинга, когда генерация начинается со случайного Гауссова вектора, который сеть шаг за шагом очищает от шума.
Главным недостатком классических диффузионных моделей остается низкая скорость работы — на заре технологии для генерации одного кадра требовалось последовательно выполнить около 1000 шагов денойзинга.
⚔️ Генеративно-состязательные сети (GAN) 1:17:34
Третьим фундаментальным классом глубоких моделей являются генеративно-состязательные сети (Generative Adversarial Networks, GAN). Архитектура GAN представляет собой прямой метод сэмплинга и реализует математическую модель антагонистической игры с нулевой суммой между двумя нейросетями. Первая сеть — генератор ($G$) — принимает на вход вектор случайного шума из простого распределения и преобразует его в синтетический объект данных. Вторая сеть — дискриминатор ($D$) — обучается как бинарный софтмакс-классификатор, задача которого заключается в том, чтобы отличить настоящие примеры из обучающей выборки от искусственных подделок, созданных генератором.
Профессор Изола предлагает метафору студента и учителя для лучшего понимания динамики GAN. Дискриминатор выступает строгим преподавателем, который указывает на ошибки в работах ученика-генератора. Получая обратную связь в виде градиентов от дискриминатора, генератор корректирует свои веса, чтобы создавать все более правдоподобные текстуры. Настоящая состязательность, по словам исследователя, позволяет достичь точки равновесия, когда подделки становятся неотличимыми от оригиналов.