В Стэнфордском университете стартовал курс EE274, посвященный теории и практике сжатия данных. В первой лекции преподаватели Пулькит (Pulkit) и Шубхам (Shubham) под руководством профессора Цзиньсиня Цзу (Tsachy Weissman) представили обзор индустрии и заложили математический фундамент безвозвратного сжатия информационных потоков.
📈 Эра зеттабайтов: почему сжатие данных критично сегодня 1:05
Мир переживает фазу экспоненциального роста объемов данных. Пулькит продемонстрировал масштаб проблемы через иерархию единиц измерения :
- 1 МБ: размер одной фотографии без потерь на смартфоне .
- 1 ГБ: несколько минут видео в формате 4K .
- 1 ТБ: стандартный объем диска современного ноутбука.
- 1 ПБ (петабайт): масштаб облачных хранилищ (AWS S3, Google Cloud). Meta генерирует более 1 ПБ данных для обработки ежедневно .
- 1 ЭБ (экзабайт): примерный объем данных, передаваемых через интернет каждые сутки .
- 1 ЗБ (зеттабайт): единица с 21 нулем. К 2025 году прогнозируется достижение отметки в 180 зеттабайтов .
По словам лектора, сжатие необходимо не только для экономии места (хранение в покое), но и для обеспечения передачи данных (движение данных). В 2021 году видеоконтент составил около 50% всего интернет-трафика . Во время пандемии COVID-19 европейские регуляторы официально просили Netflix снизить битрейт вещания, так как сетевая инфраструктура не справлялась с нагрузкой .
🛠 Где применяется сжатие: от GitHub до биомедицины 8:14
Сжатие — это не только архивация файлов в ZIP. Пулькит выделил несколько неочевидных сфер:
- Разработка ПО: При выполнении команды
git pullсистема в фоновом режиме выполняетcompressing objects. Без сжатия версионный контроль был бы невозможен из-за избыточности копий . - Машинное обучение (ML): Существует двусторонняя связь. ML используется для улучшения алгоритмов сжатия, а сжатие (квантование моделей, таких как Llama) позволяет запускать тяжелые нейросети на локальных устройствах .
- Медицина: В нейропротезировании (например, глазные протезы) сбор и передача данных ЭЭГ требуют экстремального сжатия. Без него устройство могло бы перегреться и повредить ткани из-за объема вычислений и мощности передатчика .
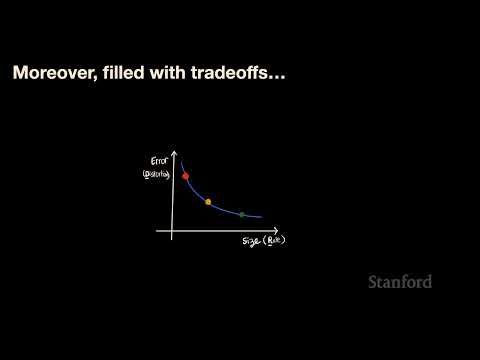
⚖️ Компромисс между качеством и размером (Lossy Compression) 11:01
Центральная концепция курса — поиск баланса на кривой «скорость–искажение» (Rate-Distortion curve) . Лектор провел эксперимент с аудиозаписью:
- Оригинал (5 МБ): Чистый звук.
- Сжатие до 2.5 МБ: Мнения аудитории разделились. Одни не заметили разницы, другие отметили падение качества .
- Сжатие до 1.2 МБ: Звук стал «пронзительным и неприятным», частоты исказились .
Аналогичный пример был приведен для изображений. Оригинальную картинку (585 КБ) удалось сжать в 500 раз (до 1.3 КБ) . Хотя ключевые черты персонажа остались узнаваемыми, появились «артефакты звона» (ringing artifacts) — визуальные искажения, которые студенты будут изучать позже в контексте алгоритмов JPEG и BPG.
🎓 Теоретический фундамент и «магическое число» 22:15
Пулькит подчеркнул, что сжатие — это «чистейшая форма обработки информации» . Он развеял миф о «бесконечном сжатии»:
- Предел энтропии: Нельзя сжимать файл в цикле (ZIP от ZIP) до нуля байт. Существует жесткий математический предел .
- Информационная теория: Клод Шеннон (Claude Shannon) определил основы цифрового века. Курс опирается на его доказательства того, что некоторые уровни сжатия физически недостижимы .
🧬 Введение в Lossless (сжатие без потерь) 35:52
Во второй половине лекции Шубхам перешел к математике. Для понимания курса достаточно знать базовую теорию вероятностей: случайные величины, математическое ожидание и совместное распределение .
Фиксированная длина против переменной 43:33
Если у нас есть алфавит из четырех символов {A, B, C, D}, стандартный подход (например, ASCII) использует 8 бит на символ. Однако для 4 вариантов достаточно 2 бит (00, 01, 10, 11) . При 1 миллионе символов это сокращает файл с 1 МБ до 250 КБ.
Если распределение вероятностей символов неравномерно, можно использовать коды переменной длины . Ключевое правило: часто встречающимся символам — короткие коды, редким — длинные .
Пример расчета 58:07
Для распределения: A (0.49), B (0.49), C (0.01), D (0.01) предложен код:
- A: 0 (1 бит)
- B: 10 (2 бита)
- C: 110 (3 бита)
- D: 111 (3 бита)
Средняя длина кода рассчитывается как сумма произведений вероятностей на длины : $(0.49 \times 1) + (0.49 \times 2) + (0.01 \times 3) + (0.01 \times 3) = 1.53$ бита на символ.
Это значительно лучше фиксированных 2 бит, но Шубхам утверждает, что предел для этого распределения еще ниже — всего 1.14 бита на символ . Лектор подытожил, что результаты Шеннона позволяют доказать невозможность сжатия данных эффективнее этого предела даже с использованием бесконечных вычислительных мощностей или интеллекта калибра Альберта Эйнштейна .




