В своём видеообзоре популярный исследователь искусственного интеллекта Янник Килчер (Yannic Kilcher) подробно разбирает научную работу «Deep Ensembles: A Loss Landscape Perspective» авторов Станислава Форта и Баладжи Лакшминараянана. В центре внимания этого исследования находится ландшафт потерь нейросетей и фундаментальный вопрос: почему ансамбли глубоких моделей показывают столь выдающиеся результаты на практике. Анализ доказывает, что секрет эффективности глубоких ансамблей кроется в их способности находить качественно разные, но одинаково точные решения за счёт случайной инициализации.
🧩 Что такое Deep Ensembles и почему они работают 0:00
В задачах классификации у нас есть набор данных, где каждый элемент обладает определёнными признаками, на основе которых модель должна предсказать метку класса. Когда мы обучаем одну глубокую нейросеть, мы настраиваем её параметры (веса) через множество слоёв. Однако концепция ансамблирования предлагает иной подход: вместо одной модели мы берём один и тот же датасет и обучаем на нём несколько независимых нейросетей. При тестировании новые данные пропускаются через все эти модели, а их финальные предсказания усредняются. По словам Янника Килчера, такой подход практически всегда даёт более точный результат, чем использование одиночной сети.
Долгое время альтернативой ансамблям считались байесовские нейросети, которые теоретически призваны описывать полное распределение возможных решений. На практике же из-за вычислительной сложности исследователям приходится использовать аппроксимации, чаще всего многомерное распределение Гаусса. Согласно гипотезе авторов статьи, которую разделяет и Килчер, такие байесовские методы способны зафиксировать лишь одну «моду» или один пик на ландшафте потерь. Они отлично понимают геометрию вокруг этого конкретного пика, но ничего не знают о других возможных решениях.
В противовес им, глубокие ансамбли (Deep Ensembles) работают принципиально иначе:
- Каждый член ансамбля инициализируется случайным образом в совершенно разных точках пространства весов.
- В процессе градиентного спуска модели оптимизируются независимо и в итоге приходят к разным локальным минимумам.
- За счёт этого ансамбль успешно покрывает различные функциональные моды ландшафта, что обеспечивает превосходную генерализацию и устойчивость к неопределённости.
Для проверки своих идей авторы провели серию экспериментов на популярных датасетах CIFAR-10, CIFAR-100 и ImageNet. В качестве архитектур использовались небольшие и средние свёрточные сети (CNN), а также более крупная сеть Resnet-20, показавшая точность около 90% на CIFAR-10. Янник Килчер призывает с долей скепсиса относиться к результатам совсем маленьких сетей с точностью около 64%, поскольку физика процессов в недообученных моделях может качественно отличаться. Однако он соглашается, что подтверждение эффектов на Resnet делает выводы исследования весьма убедительными. Килчер также подчёркивает ценность подобной «объяснительной» работы, которая помогает понять внутренние механизмы ИИ, не требуя при этом гигантских вычислительных ресурсов, доступных только ИТ-гигантам.
📉 Траектория обучения и загадка пространства весов 11:45
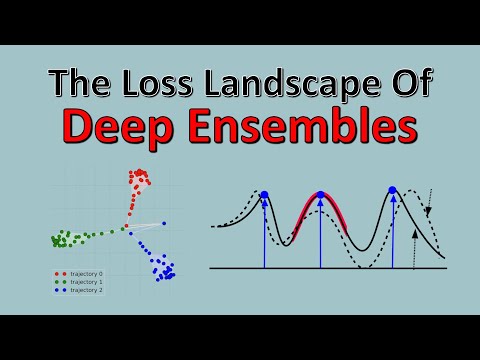
Исследование ландшафта потерь начинается с анализа траектории обучения одиночной нейросети. Мы берём случайную инициализацию в пространстве весов и запускаем градиентный спуск, который приводит нас к первому локальному минимуму. Затем мы повторяем этот процесс из другой случайной точки и получаем второй минимум. Поскольку функция потерь нейросетей не является выпуклой, эти минимумы находятся в разных местах пространства весов, но работают примерно с одинаковой точностью. Авторы задаются вопросом: описывают ли эти разные минимумы одну и ту же функцию, или это фундаментально разные решения, которые просто случайно дают похожую точность?
Для ответа на этот вопрос исследователи измерили косинусное сходство весов между чекпоинтами (срезами весов) на разных эпохах одной траектории обучения. Выяснились следующие особенности процесса оптимизации:
- На самых ранних этапах обучения веса модели начинают стремительно отдаляться от начальной случайной инициализации.
- Существует короткий переходный период, когда модель хаотично «блуждает» по ландшафту, не имея сильного сходства ни со стартом, ни с финишем.
- После этого короткого этапа нейросеть попадает в конкретную «долину» (бассейн притяжения), и все последующие чекпоинты становятся очень похожими на финальную обученную модель.
На основе этого Янник Килчер формулирует гипотезу: в начале обучения модель совершает несколько крупных шагов в случайных направлениях за счёт шума оптимизации. Но как только она падает в одну из многочисленных «выпуклых» ям на ландшафте потерь, её судьба предопределена. Дальнейшее обучение — это лишь микрооптимизация параметров внутри этой конкретной долины, из которой сеть уже не выберется.
📊 Несогласие в предсказаниях: данные не одинаково сложны 16:35
Среди специалистов популярно интуитивное мнение, что в любом датасете есть условно «лёгкие» примеры и «тяжёлые» примеры, которые принципиально сложно классифицировать. Казалось бы, если две модели достигают 90% точности, они должны безошибочно определять одни и те же 90% картинок и спотыкаться на оставшихся сложных 10%. Эксперименты из данной статьи полностью опровергают это заблуждение.
Исследователи измерили показатель «несогласия предсказаний» (disagreement of predictions) между моделями. Результаты оказались поразительными:
- Чекпоинты внутри одной и той же траектории обучения быстро приходят к согласию и выдают практически идентичные ответы на валидационной выборке после фиксации в долине притяжения.
- Однако, если мы возьмём две абсолютно одинаковые архитектуры, обученные на одном и том же датасете с одинаковой функцией потерь, но запущенные из разных начальных случайных точек, они покажут сильное несогласие.
- Для небольшой CNN, имеющей базовую точность 65%, независимые решения расходятся во мнениях относительно целых 25% меток на валидационном наборе данных.
Таким образом, как отмечает Килчер, никакой «врождённой сложности» у объектов датасета нет. Одна модель из-за своей инициализации может легко классифицировать подмножество А и ошибаться на подмножестве Б, а её точная копия с другими стартовыми весами сделает всё с точностью до наоборот. Визуализация предсказаний с помощью алгоритма t-SNE наглядно подтверждает этот феномен: в самом начале оптимизации разные запуски мгновенно разлетаются в противоположные стороны высокомерного пространства, после чего лишь совершают небольшие колебания внутри своих локальных зон.
🗺️ Ландшафт потерь: геометрия независимых оптимумов 30:15
Чтобы наглядно продемонстрировать устройство геометрии нейросетей, авторы построили карты ландшафта потерь в 2D-проекции. Для создания такой плоскости использовались три реперные точки: начало координат в пространстве весов (абсолютный нуль) и два финальных оптимума, полученных в результате двух независимых запусков обучения. Для каждого пикселя на получившейся полусфере была рассчитана линейная комбинация векторов весов, и для получившейся конфигурации нейросети замерялась итоговая точность.
Эта визуализация выявила чёткую структуру:
- На карте отчётливо видны две глубокие обособленные долины, в которых находятся наши оптимумы.
- Даже если инициализировать модели очень близко друг к другу в плоской начальной области ландшафта, минимальный сдвиг влево или вправо заставляет одну модель скатиться в левый бассейн притяжения, а другую — в правый.
- Между этими долинами пролегает высокая стена из зон с огромными потерями и низкой точностью. Ни одна модель в здравом уме никогда не пересечёт этот барьер в процессе стандартного обучения.
Далее исследователи сравнили глубокие ансамбли с четырьмя популярными методами локального поиска решений, которые стартуют из уже готового оптимума:
- Случайное сэмплирование подпространств (random subspace sampling) — смещение весов из финальной точки в случайных направлениях.
- Подпространство дропаута (dropout subspace) — применение дропаута с разной вероятностью к обученной сети.
- Диагональное гауссово подпространство (diagonal Gaussian subspace) — создание гауссовой аппроксимации вокруг минимума и взятие сэмплов параметров.
- Низкоранговое подпространство (low-rank subspace) — аппроксимация локальной структуры в режиме низкого ранга.
Как показал t-SNE анализ, все эти четыре метода (включая классические байесовские подходы) на карте ландшафта выглядят как узкая «розовая полоса» вокруг одного единственного минимума. Они способны детально изучить кривизну внутри одной долины, но вес пространства слишком велик, и локальные возмущения физически не могут перебросить модель через высокопотериевую стену в соседнюю долину. Янник Килчер резюмирует: единственный надёжный способ выбраться из локальной ловушки и найти альтернативную моду — это полная перезагрузка весов и обучение с нуля.
📈 Дилемма разнообразия и точности 35:56
Для оценки качества различных подходов авторы ввели так называемые графики «разнообразия против точности» (diversity versus accuracy). По оси ординат откладывалось функциональное разнообразие моделей (доля изменённых предсказаний по сравнению с базовым оптимумом), а по оси абсцисс — их точность на валидационной выборке.
Эксперименты выявили закономерность для локальных методов возмущения: чем сильнее мы модифицируем веса базовой модели (пытаясь сделать её разнообразнее), тем стремительнее она начинает взбираться вверх по склону ландшафта потерь. В итоге точность катастрофически падает, стремясь к нулю, как только разнообразие достигает максимума.
Однако независимые оптимумы, полученные через Deep Ensembles (на графиках они отмечены красными звёздами), полностью ломают этот тренд:
- Они обладают максимально возможным уровнем функционального разнообразия, так как предсказывают разные вещи на сложных объектах.
- При этом они сохраняют идеальную базовую точность, оставаясь на самом дне своих долин потерь.
- На более сложных задачах, таких как CIFAR-100 или ImageNet, этот разрыв становится ещё более выраженным, подчёркивая превосходство независимого обучения.
В финальной части статьи демонстрируется, что независимые ансамбли обладают колоссальной устойчивостью к искажениям данных (out-of-distribution robustness). Модели тестировали на зашумлённых и повреждённых изображениях. Одиночные сети быстро теряли точность при увеличении уровня порчи картинок, а локальные гауссовы методы давали лишь незначительный прирост. В то же время ансамбли всего из двух или пяти независимо инициализированных моделей совершали колоссальный скачок в точности, эффективно компенсируя ошибки друг друга. Янник Килчер делает вывод, что глубокие ансамбли из случайных инициализаций побеждают байесовские аппроксимации именно за счёт объединения сил принципиально разных, уникальных математических функций, нашедших свои собственные паттерны в хаосе данных.




