В рамках курса CS336, организованного для студентов в Стэнфордском университете, подробно разбираются архитектурные подходы к масштабированию систем машинного обучения. Когда современные языковые модели перестают помещаться в память одного графического ускорителя, инженерам приходится превращать весь дата-центр в единый суперкомпьютер. В этом материале на основе лекции Stanford Online рассматриваются фундаментальные стратегии параллелизации вычислений, их ограничения и реальные кейсы применения ИТ-гигантами.
🌐 Переход к распределенным вычислениям и иерархия железа 0:04
Масштабирование современных нейросетей упирается в два ключевых ресурса: вычислительную мощность (Flops) и доступную память (Memory). Поскольку суперэкспоненциальный рост производительности одиночных GPU не успевает за увеличением числа параметров LLM, единственным выходом здесь и сейчас становится многомашинный параллелизм. Полноценной вычислительной единицей в современной индустрии искусственного интеллекта становится не отдельный чип, а инфраструктура всего дата-центра.
Эффективность распределенного обучения напрямую зависит от понимания аппаратной иерархии:
- Внутри одного сервера (ноды): Обычно установлено до 8 графических процессоров, соединенных сверхбыстрыми внутренними интерфейсами (такими как NVLink и NVSwitch).
- Между серверами: Коммуникация осуществляется через сетевые интерфейсы, например HDR InfiniBand.
Скорость передачи данных между машинами примерно в 8 раз ниже, чем внутри одного физического шасси. Как отмечает лектор, порог в 256 объединенных GPU является критической точкой, после которой сетевые задержки начинают существенно влиять на производительность, требуя сложных многоуровневых коммутаторов. В противовес этому, компания Google в своих чипах TPU использует концепцию тороидальной решетки (toroidal mesh). В такой архитектуре каждый чип общается только со своими непосредственными соседями, что накладывает ограничения на топологию связей, но позволяет эффективно и дешево масштабировать систему для определенных типов коллективных операций.
🔄 Примитивы коллективных коммуникаций 4:53
Для синхронизации данных между сотнями ускорителей используются стандартные операции распределенного программирования. К ним относятся:
- All-Reduce: Сбор фрагментов данных со всех машин, выполнение математической операции (например, суммирования градиентов) и копирование полного результата обратно на каждое устройство.
- Broadcast: Копирование данных с одного ведущего узла на все остальные.
- Reduce: Суммирование данных со всех машин и отправка результата на один выделенный сервер.
- All-Gather: Сбор уникальных блоков данных со всех участников и формирование полной копии массива на каждом GPU.
- Reduce-Scatter: Операция, при которой элементы суммируются, но итоговые части распределяются по разным машинам.
Преподаватель обращает внимание на важнейшую эквивалентность в режиме ограниченной пропускной способности сети: операция All-Reduce по своей стоимости и объёму передаваемых данных идентична последовательному выполнению Reduce-Scatter и All-Gather. Этот математический факт лежит в основе большинства современных оптимизаций памяти, поскольку позволяет разделять этапы коммуникации и внедрять между ними полезные вычисления.
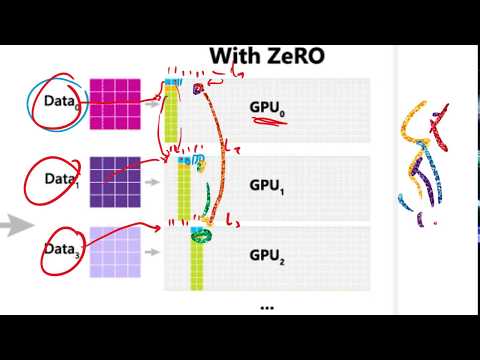
📉 Параллелизм по данным и протокол ZeRO 12:29
Классический параллелизм по данным (Data Parallelism, DP) устроен концептуально просто: модель полностью копируется на все GPU, а глобальный пакет данных (batch) делится на части. Каждое устройство считает градиенты на своей порции данных, после чего они синхронизируются через All-Reduce. Этот подход отлично масштабирует вычисления, но катастрофически неэффективен с точки зрения памяти: каждый GPU обязан хранить дубликаты всех весов и состояний оптимизатора.
В реальности ситуация с памятью выглядит намного хуже, чем кажется на первый взгляд. Для обучения в режиме BF16 на один параметр модели требуется не 2 байта, а порядка 16 байт:
- Параметры (веса): 2 байта в формате BF16.
- Градиенты: 2 байта в формате BF16.
- Состояния оптимизатора Adam: 4 байта для мастер-весов (для точного аккумулирования), 4 байта для оценки первого момента (исторические градиенты) и 4 байта для оценки второго момента (дисперсия градиентов).
В результате веса оптимизатора полностью доминируют в потреблении памяти. Чтобы решить эту проблему, был разработан протокол ZeRO (Zero Overhead Redundancy), предлагающий три стадии секционирования (sharding):
- ZeRO Stage 1 (Секционирование состояний оптимизатора): Память Adam разделяется между всеми GPU. Устройство считает градиенты для всего графа, но обновляет только свою $1/M$ часть параметров, после чего новые веса рассылаются остальным через All-Gather. Это дает огромную экономию памяти практически бесплатно.
- ZeRO Stage 2 (Секционирование градиентов): Градиенты не аккумулируются в полный вектор. Как только в процессе обратного прохода (backward pass) вычисляется градиент конкретного слоя, он немедленно отправляется на ответственный за него GPU и удаляется из локальной памяти остальных.
- ZeRO Stage 3 (Секционирование параметров / FSDP): Полный вектор весов не хранится нигде. На forward и backward проходах веса конкретного слоя запрашиваются по сети через All-Gather непосредственно перед вычислением, а затем сразу же стираются из памяти.
По словам лектора, технология Fully Sharded Data Parallel (FSDP), являющаяся воплощением ZeRO Stage 3, работает удивительно эффективно благодаря перекрытию (overlapping) вычислений и сетевых запросов. Пока GPU выполняет матричное умножение для текущего слоя, в фоновом режиме идет предварительная загрузка (prefetching) весов для следующего шага, что сводит простои к минимуму.
Тем не менее, у параллелизма по данным есть жесткое ограничение: размер глобального пакета (batch size) является конечным ресурсом. Нельзя масштабировать обучение DP бесконечно, так как размер микропакета на один GPU не может быть меньше одного примера, а чрезмерное раздувание глобального пакета ведет к резкому снижению эффективности оптимизации («критический размер пакета», исследованный OpenAI). К тому же, ZeRO не решает проблему памяти активаций.
🏗️ Модельный параллелизм: конвейеры и тензоры 45:05
Когда модель физически невозможно уместить на устройствах стандартными методами, инженеры переходят к модельному параллелизму (Model Parallelism), при котором по сети пересылаются не веса, а активации. Существует два базовых измерения для «нарезки» нейросети: по глубине (слоям) и по ширине (матрицам).
Конвейерный параллелизм (Pipeline Parallelism)
Нейросеть режется по границам слоев, и разные GPU отвечают за разные этапы обработки. Очевидная проблема наивной реализации — гигантские простои оборудования (так называемый «пузырь конвейера», pipeline bubble), когда последующие GPU бездействуют в ожидании результатов от предыдущих. Для борьбы с этим пакет делят на микропакеты, накладывая вычисления друг на друга.
По оценке преподавателя, конвейерный параллелизм — это «кошмар с точки зрения реализации». Он требует глубокого вмешательства в механизмы автоматического дифференцирования. В индустрии ходят истории о том, что в ведущих ИИ-лабораториях логику работы распределенного конвейера могут до конца понимать всего один-два человека. Тем не менее, он незаменим для медленных сетевых каналов (между стойками серверов), так как передает лишь пограничные активации. Продвинутые подходы, такие как «zero-bubble pipelining» или DualPipe, убирают простои за счет хитрой перегруппировки вычислений: слоты пассивного ожидания заполняются расчетом градиентов по весам ($W$), который не имеет строгих последовательных зависимостей.
Тензорный параллелизм (Tensor Parallelism)
Этот метод разделяет вычисления внутри самих матричных умножений (MatMul). Большие матрицы весов (например, в слоях MLP) разрезаются по столбцам или строкам между несколькими GPU. При прямом проходе устройства получают одинаковые входные данные, параллельно умножают их на свои субматрицы, а затем объединяют результаты через All-Reduce.
Тензорный параллелизм требует синхронизации на каждом слое, что делает его критически зависимым от пропускной способности сети. Преподаватель озвучил жесткое эмпирическое правило: тензорный параллелизм должен применяться строго внутри одного физического узла (ноды) — до 8 GPU. Статистика показывает, что масштабирование тензорного параллелизма до 16 GPU вне быстрой шины ведет к падению пропускной способности на 42%, а до 32 устройств — на катастрофические 65%. При этом ключевой плюс метода — он вообще не расходует ресурс глобального пакета данных.
🎞️ Параллелизм активаций и последовательностей 1:02:13
Память, занимаемая активациями (промежуточными результатами слоев), носит динамический характер: она непрерывно растет во время прямого прохода, достигает пика в начале обратного прохода и спадает по мере вычисления градиентов. Для гигантских контекстов и моделей активации становятся главным барьером, который не могут полностью устранить ни тензорный, ни конвейерный методы.
Полная формула расчета памяти активаций на один слой выглядит следующим образом:
$$sbh \times \left(34 + \frac{5as}{h}\right)$$
где $s$ — длина последовательности, $b$ — размер микропакета, $h$ — скрытая размерность, $a$ — число голов внимания.
Даже при максимальном тензорном параллелизме в формуле остается «неприкосновенный остаток» вида $sbh \times 10$. Это память, расходуемая на поэлементные (pointwise) операции: LayerNorm, Dropout и входные структуры. Они не задействуют матричные умножения, поэтому классический тензорный параллелизм их игнорирует. Решением становится последовательный параллелизм (Sequence Parallelism) — данные в этих операциях разрезаются вдоль оси длины последовательности ($s$), распределяясь по GPU, а для сборки используются комбинации Reduce-Scatter и All-Gather. Для радикального сжатия оставшейся квадратичной части применяется метод FlashAttention и выборочный пересчет (recomputation) активаций на лету.
🛠️ Гибридные стратегии и реальный опыт индустрии 1:11:19
На практике ни один метод не применяется в одиночку — инженеры создают 3D, 4D или даже 5D-схемы параллелизма, комбинируя подходы в строгой последовательности. Лектор сформулировал универсальный алгоритм настройки распределенного обучения:
- Тензорный параллелизм (TP): Включается в первую очередь внутри одной ноды (до 8 GPU), чтобы ужать базовые матрицы и уместить модель в физическую память.
- Контекстный параллелизм (CP) / Ring Attention: Добавляется при работе со сверхдлинными текстами для распределения вычислений механизма внимания по кольцевой схеме.
- ZeRO-3 (FSDP) или Конвейерный параллелизм (PP): Разворачивается поверх предыдущих уровней межмашинных соединений для окончательного распределения слоев по стойкам дата-центра.
- Параллелизм по данным (DP): Заполняет все оставшиеся доступные GPU для максимизации суммарной вычислительной мощности (Flops). Если результирующий микропакет слишком мал, применяется аккумулирование градиентов (gradient accumulation) для искусственного снижения частоты сетевых синхронизаций.
Анализ современных открытых моделей подтверждает эти правила. Например, модель OLMo 7B обучалась на чистом FSDP. Архитектура DeepSeek V3 задействует 16-уровневый конвейерный параллелизм и 64-уровневый экспертный параллелизм (разновидность тензорного метода для Mixture-of-Experts моделей, требующая сложной маршрутизации токенов).
Технический отчет Llama 3 от компании Meta наглядно демонстрирует суровые реалии масштабной инженерии. Для обучения использовалась иерархическая схема: TP=8, PP и DP. На огромном масштабе оборудование начинает регулярно сбоить: в процессе обучения Llama 3 было зафиксировано 148 внеплановых прерываний только из-за поломок GPU (что составило около 30% от всех остановок). Помимо явных отказов, как делятся специалисты, огромную опасность представляют скрытые аппаратные ошибки (silent data corruption), когда чип продолжает работать, но выдает искаженные данные, незаметно уничтожая результаты многодневных вычислений. В свою очередь, Google при обучении Gemma 2 на базе своих TPU смог отказаться от сложного конвейерного параллелизма, полностью полагаясь на комбинацию ZeRO-3 и модельного параллелизма, что стало возможным благодаря быстрой тороидальной сети распределения данных.