Microsoft продолжает лидировать в гонке за создание всё более масштабных языковых моделей, представив Turing-NLG — модель с 17 миллиардами параметров. В свежем обзоре Янник Кильхер анализирует не только архитектурные особенности этой новинки, но и технологический прорыв, стоящий за её обучением — библиотеку DeepSpeed и оптимизатор ZeRO. Несмотря на внушительные цифры, автор видео скептически относится к идее, что простое увеличение количества параметров является единственным путем к пониманию языка.
🚀 Turing-NLG: Масштаб имеет значение? 0:00
Turing-NLG от Microsoft — это языковая модель, построенная на архитектуре Transformer, которая на момент выхода достигла показателя в 17 миллиардов параметров. По словам Янника Кильхера, индустрия ИИ движется по пути постоянного увеличения вычислительных мощностей и объемов данных для тренировки подобных систем.
Основные характеристики и возможности модели:
- Архитектура: Все современные модели такого класса, включая Bert и GPT-2, используют трансформеры, и Turing-NLG не стала исключением.
- Zero-shot QA: Система способна отвечать на вопросы, даже не получая контекста, опираясь исключительно на закономерности, выявленные в процессе обучения. Например, модель способна самостоятельно определить дату завершения Второй мировой войны.
- Генерация ответов: В отличие от классических систем поиска ответов, которые просто выделяют фрагмент текста, Turing-NLG формулирует полноценные связные предложения.
Янник Кильхер выражает сомнение относительно того, насколько эти способности свидетельствуют о реальном понимании языка. Существует риск, что при таком количестве параметров модель просто начинает воспроизводить данные, на которых проходила обучение, запоминая их наизусть.
⚙️ Оптимизатор ZeRO и библиотека DeepSpeed 4:32
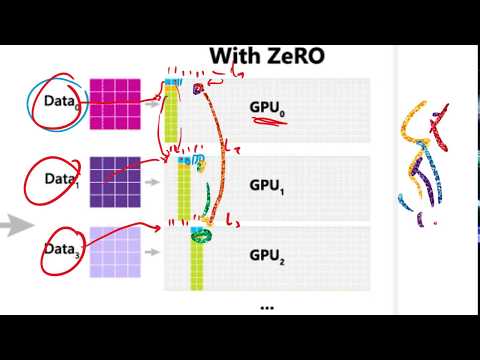
Главным техническим достижением, позволившим обучить столь массивную модель, Кильхер называет оптимизатор ZeRO, входящий в состав библиотеки DeepSpeed от Microsoft. Он подчеркивает, что без этой разработки обучение Turing-NLG было бы практически невыполнимой задачей.
Традиционные методы параллелизации вычислений сталкиваются с серьезными ограничениями, когда модель перестает помещаться в память одного устройства или даже одной машины.
Проблемы классических подходов
- Параллелизм данных: Подразумевает дублирование модели на нескольких GPU, где каждая видеокарта обрабатывает свою часть данных, после чего результаты синхронизируются. Это эффективно, пока модель помещается в память одного устройства.
- Параллелизм модели: При очень больших моделях их части распределяются по разным машинам. Однако это создает огромные задержки, так как пока одна часть модели работает, остальные простаивают, ожидая передачи промежуточных данных по сети.
Как работает ZeRO
По мнению Кильхера, ZeRO — это выдающееся инженерное решение, которое объединяет преимущества обоих подходов, минимизируя простои. Основная логика работы заключается в динамическом управлении памятью:
- Разделение: Параметры модели, градиенты и параметры оптимизатора распределяются между доступными GPU.
- Динамическая коммуникация: Вместо хранения всей модели на каждом устройстве, компоненты пересылаются между узлами только в тот момент, когда они нужны для вычислений.
- Очистка: Сразу после выполнения вычислений на конкретном слое, временные данные удаляются, чтобы освободить место для следующих операций.
- Агрегация: В процессе обратного распространения ошибки градиенты собираются с разных машин, что позволяет обновлять параметры модели с учетом всех данных, обработанных параллельно.
💡 Итоги и перспективы 20:05
Янник Кильхер отмечает, что инструменты вроде DeepSpeed и ZeRO предназначены исключительно для «крупных игроков», работающих с моделями уровня 100 миллиардов параметров и выше, и вряд ли будут полезны среднему пользователю Google Colab.
Однако он делает важное предупреждение: по его мнению, развитие ИИ не должно сводиться только к «накачке» параметров. Он полагает, что индустрии ещё предстоит совершить качественный прорыв в архитектуре моделей для достижения настоящего понимания языка.




