Implicit MLE: Как обучать нейросети с «необучаемыми» дискретными слоями 🧠 0:00
В современном глубоком обучении часто возникают задачи, где нейронная сеть должна использовать результаты дискретных алгоритмов — например, поиск кратчайшего пути на графе или решение задач целочисленного программирования. Основная проблема заключается в том, что такие операции «непрозрачны» для классического метода обратного распространения ошибки (backpropagation), так как они недифференцируемы. В видео, посвященном статье «Implicit MLE: Backpropagating Through Discrete Exponential Family Distributions» от Матиаса Снайперда, Паскаля Минервини и Луки Франчески, ведущий Янник Кильчер разбирает подход, позволяющий «прокинуть» градиенты через эти дискретные узкие места,.
🧩 Проблема дискретных операций в нейросетях 8:46
Когда нейронная сеть включает в себя дискретный «черный ящик» (например, алгоритм Дейкстры), возникает разрыв в цепочке вычислений.
- Классический подход: Попытка использовать прямой градиент через дискретную операцию не работает, так как производная от дискретной функции либо равна нулю, либо не определена.
- Straight-Through Estimator (STE): Известный «трюк», при котором в прямом проходе выполняется дискретная операция, а в обратном градиент просто «пробрасывается» через нее, как если бы операции не было. Однако, по словам Кильчера, STE работает не всегда и часто бывает нестабильным.
💡 Framework Implicit MLE: Суть решения 6:36
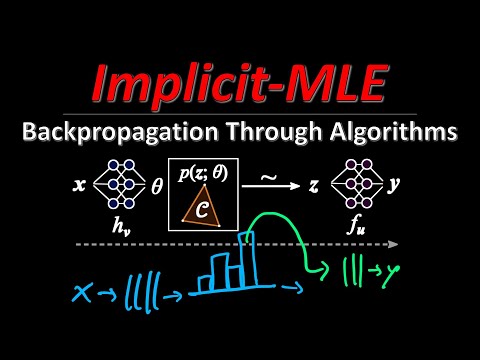
Авторы статьи предлагают новый подход — Implicit Maximum Likelihood Estimation (IMLE). Идея заключается в том, чтобы рассматривать дискретный алгоритм как распределение из семейства экспоненциальных распределений.
- Формулировка задачи: Проблема кодируется как максимизация скалярного произведения между вектором решения $z$ и вектором весов $\theta$ (который является выходом первой части сети, например, описанием графа).
- Целевое распределение: Вместо того чтобы пытаться дифференцировать сам алгоритм, авторы предлагают создать «целевое распределение» ($q$), которое в ожидании дает меньшую ошибку (loss), чем текущее распределение ($p$).
- Использование градиентного спуска: С помощью одного шага градиентного спуска внутри самого алгоритма они определяют, как нужно изменить «определение проблемы» ($\theta$), чтобы минимизировать итоговую ошибку.
🛠 Метод «Perturb and Map» 39:28
Так как точное вычисление градиентов для таких распределений — задача, требующая колоссальных ресурсов (иногда классифицируемая как #P-hard), авторы используют аппроксимацию:
- Perturb and Map: Чтобы оценить «среднее» (mean) распределения, алгоритм вносит случайный шум (распределение Гамбеля) в параметры $\theta$ и многократно решает задачу оптимизации.
- Аппроксимация градиента: Разница между результатами при разных возмущениях позволяет получить суррогатный градиент.
По мнению Кильчера, подбор правильного уровня шума здесь критически важен: слишком маленький шум не дает информации для обновления, слишком большой — делает поведение системы хаотичным.
📈 Результаты и применение 58:18
Янник Кильчер отмечает, что реализация довольно проста для интеграции в стандартные фреймворки (PyTorch, TensorFlow). В экспериментах метод Implicit MLE показывает себя эффективнее стандартного Straight-Through Estimator, обеспечивая более стабильное обучение в задачах, где дискретная оптимизация является частью конвейера.




