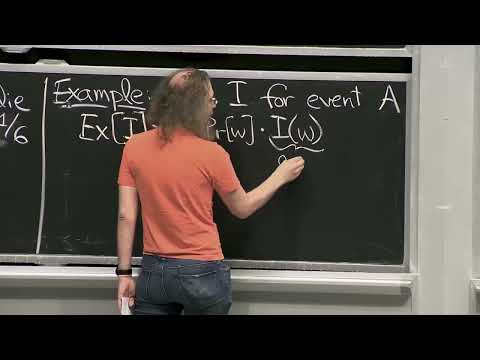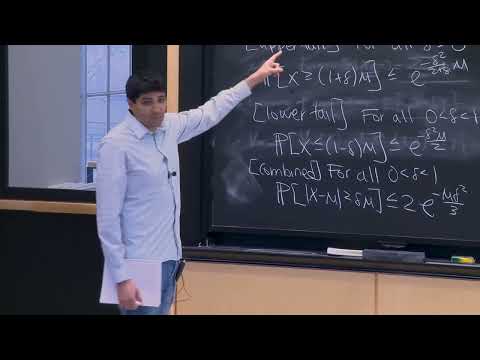
В рамках университетского курса по теории вероятностей и анализу рандомизированных алгоритмов концепция оценки «хвостов» распределений занимает центральное место. На лекции Института (MIT OpenCourseWare) было представлено подробное математическое обоснование одного из самых мощных инструментов современной прикладной математики — границы Чернова. Этот метод позволяет оценивать вероятность того, что сумма независимых случайных величин значительно отклонится от своего математического ожидания. Помимо чисто теоретического вывода, лектор уделил внимание историческому контексту открытия, педагогическим аспектам декомпозиции сложных доказательств, а также катастрофическим последствиям неверного применения этого математического аппарата в реальном мире, в частности, во время финансового кризиса 2008 года.
📊 Введение в границы хвостов распределений: от Маркова к Чебышёву 0:11
Концепция оценки границ хвостов (tail bounds) необходима для понимания того, насколько вероятно, что случайная величина окажется далеко от своего математического ожидания. Каждая из классических границ использует определенный объем информации о случайной величине для получения математического результата.
Неравенство Маркова — это базовый инструмент, требующий лишь знания того, что случайная величина является неотрицательной. На основе одного лишь этого факта оно позволяет ограничить вероятность того, что величина превысит свое математическое ожидание, например, в два раза.
Неравенство Чебышёва делает следующий шаг, подключая информацию о дисперсии случайной величины, которая служит мерой разброса значений вокруг среднего.
Граница Чернова представляет собой значительно более мощный и высокоточный инструмент. Её ключевое отличие заключается в том, что она опирается не просто на среднее значение или дисперсию, а на фундаментальное структурное свойство: исследуемая случайная величина должна представлять собой сумму взаимно независимых случайных величин. В процессе доказательства границы Чернова неявно используются не только первый (математическое ожидание) и второй (дисперсия) моменты случайной величины, а сразу все высшие моменты.
📐 Математическая формулировка неравенства Чернова 1:29
Классический, наиболее распространенный вариант границы Чернова формулируется для суммы взаимно независимых случайных величин. Важно подчеркнуть, что требование взаимной независимости (mutual independence) является критическим — простой попарной независимости (pairwise independence) недостаточно, и без соблюдения этого условия неравенство становится абсолютно неверным.
Для простоты изложения в рамках лекции рассматриваются бернуллиевские случайные величины $X_i$. Каждая такая величина с вероятностью $p_i$ принимает значение $1$, а в противном случае — $0$. Пусть случайная величина $X$ равна сумме всех $X_i$. Тогда её математическое ожидание обозначается как $\mu$ и рассчитывается по формуле:
$$\mu = E[X] = \sum p_i$$
Граница Чернова существует в нескольких модификациях («вкусах»). Первая модификация описывает так называемый «верхний хвост» (upper tail) — вероятность того, что случайная величина окажется значительно больше своего математического ожидания. Для любого параметра $\delta > 0$ вероятность превышения среднего значения в $(1 + \delta)$ раз оценивается следующим образом:
$$P(X \ge (1 + \delta)\mu) < \left( \frac{e^\delta}{(1 + \delta)^{1 + \delta}} \right)^\mu$$
Эта вероятность убывает экспоненциально, причем скорость убывания жестко зависит как от параметра $\delta$, так и от среднего значения $\mu$.
Интуитивно этот процесс можно понять на примере подбрасывания симметричной монеты, где вероятность выпадения орла составляет 50%. Если подбросить монету огромное количество раз, эмпирическое среднее число орлов будет стремительно приближаться к теоретическим 50%. Закон больших чисел гарантирует это сближение, однако граница Чернова дает гораздо более сильную количественную оценку. По мере роста числа подбрасываний $n$ пропорционально растет и среднее значение $\mu$. Следовательно, вероятность получить, к примеру, на 10% больше орлов, чем ожидалось, падает экспоненциально относительно $n$. В этом заключается принципиальное различие между границей Чернова и слабым законом больших чисел: первый гарантирует экспоненциально малой вероятности неудачи, тогда как второй дает лишь обратно-полиномиальное убывание.
Соответствующий «нижний хвост» (lower tail) описывает вероятность получить слишком малое количество успешных исходов. В данном контексте параметр $\delta$ имеет смысл выбирать строго в диапазоне между нулем и единицей. Вероятность того, что значение $X$ окажется меньше или равно $(1 - \delta)\mu$, также экспоненциально мала:
$$P(X \le (1 - \delta)\mu) < \left( \frac{e^{-\delta}}{(1 - \delta)^{1 - \delta}} \right)^\mu$$
Если точная зависимость от дельты не является критически важной для конкретной прикладной задачи, верхнюю и нижнюю границы можно объединить в одну универсальную формулу. Для любого $\delta \in (0, 1)$ вероятность отклонения $X$ от своего математического ожидания более чем на $\delta\mu$ подчиняется следующему неравенству:
$$P(|X - \mu| > \delta\mu) \le 2e^{-\frac{\mu\delta^2}{3}}$$
Существует целое семейство границ Чернова. Представленные выше варианты рассчитаны на бернуллиевские величины, однако существуют версии для более экзотических случайных величин — например, с ограниченными вторыми моментами. Единый методологический подход к доказательству применим ко многим вариантам, поэтому инженерам и математикам достаточно детально разобрать один классический случай, а при работе со специфическими распределениями просто брать готовую формулу из справочников. На вопрос аудитории о том, обязательно ли значение $\mu$ должно быть положительным, был дан утвердительный ответ для текущего контекста: поскольку все базовые величины $X_i$ неотрицательны, их сумма дает строго положительное среднее (случай с $\mu = 0$ тривиален). Если же случайные величины могут принимать отрицательные значения, формулу приходится сдвигать и масштабировать, что усложняет вид экспоненты.
🧠 Стратегия доказательства: экспоненциальный трюк и Марков 6:38
Данное математическое доказательство является одним из самых сложных в курсе дискретной математики MIT. Стратегически его можно разделить на высокоуровневую архитектуру связей и чисто технические, рутинные алгебраические вычисления.
Основная идея вывода во многом перекликается с приемом, использованным при доказательстве неравенства Чебышёва. Пусть имеется случайная величина $X$ и некоторый порог $A$ (который впоследствии будет заменен на $(1 + \delta)\mu$ или $(1 - \delta)\mu$). Нас интересует вероятность события, при котором $X \ge A$.
Утверждается, что для любого неотрицательного параметра $b \ge 0$ (значение $b = 0$ исключается как неинформативное) справедливо тождество:
$$P(X \ge A) = P(e^{bX} \ge e^{bA})$$
Этот шаг называют первым ключевым трюком доказательства. В неравенстве Чебышёва, где исходная случайная величина могла быть отрицательной, обе части возводились в квадрат, чтобы искусственно создать новую неотрицательную величину. В данном случае применяется возведение в степень. Поскольку экспоненциальная функция $e^y$ является строго монотонно возрастающей, множества точек, удовлетворяющих неравенствам $X \ge A$ и $e^{bX} \ge e^{bA}$, абсолютно идентичны. Это буквально одно и то же случайное событие.
На следующем этапе вводится новая вспомогательная случайная величина:
$$Y = e^{bX}$$
По самой своей конструкции экспоненциальная функция всегда принимает строго положительные значения, а значит, случайная величина $Y$ гарантированно является неотрицательной. К ней можно применить классическое неравенство Маркова. Подставляя $Y$ в формулу Маркова с пороговым значением $e^{bA}$, получаем:
$$P(Y \ge e^{bA}) \le \frac{E[Y]}{e^{bA}}$$
Поскольку события внутри вероятностей слева идентичны, мы производим обратную замену и переписываем левую часть через исходную переменную $X$:
$$P(X \ge A) \le \frac{E[e^{bX}]}{e^{bA}}$$
Этот изящный шаг позволяет свести задачу оценки вероятности хвоста к вычислению математического ожидания экспоненты от случайной величины.
🔗 Производящая функция моментов и её свойства 12:56
Величина $E[e^{bX}]$, возникшая в числителе правой части, имеет фундаментальное значение в теории вероятностей и называется производящей функцией моментов (moment generating function, MGF) случайной величины $X$. Математически она обозначается как $M_X(b)$:
$$M_X(b) = E[e^{bX}]$$
Важно понимать, что хотя функция строится на базе случайной величины $X$, после взятия математического ожидания сама случайность исчезает. Результат представляет собой детерминированную функцию от свободного параметра $b$.
Интуитивный смысл этого инструмента раскрывается через разложение экспоненты в ряд Тейлора. Запишем разложение для $e^{bX}$:
$$e^{bX} = 1 + bX + \frac{b^2X^2}{2!} + \frac{b^3X^3}{3!} + \dots$$
Применяя свойство линейности математического ожидания к этому бесконечному ряду, мы можем вынести константы наружу:
$$M_X(b) = \sum_{i=0}^{\infty} \frac{b^i}{i!} E[X^i]$$
Таким образом, коэффициентами при степенях параметра $b$ в разложении производящей функции являются моменты случайной величины $X$. При $i=0$ мы получаем тривиальную единицу. При $i=1$ коэффициент при $b$ равен первому моменту — математическому ожиданию $E[X]$. При $i=2$ мы получаем не дисперсию, а второй момент $E[X^2]$, и так далее для всех высших порядков. Из этой функции можно аналитически извлекать моменты любого порядка с помощью дифференцирования. Например, первый момент (математическое ожидание) извлекается путем взятия первой частичной производной по параметру $b$ и её последующего вычисления в точке $b=0$:
$$\left. \frac{\partial}{\partial b} M_X(b) \right|_{b=0} = E[X]$$
Для извлечения второго момента необходимо взять вторую производную и точно так же подставить $b=0$. Граница Чернова работает исключительно благодаря тому, что функция $M_X(b)$ аккумулирует в себе информацию обо всех моментах случайной величины одновременно.
Главная математическая теорема (Лемма 1), объясняющая, почему производящая функция моментов идеально сочетается с концепцией взаимной независимости, формулируется следующим образом: если случайная величина $X$ является суммой взаимно независимых величин $X_i$, то её производящая функция моментов равна произведению производящих функций моментов всех составляющих слагаемых:
$$M_X(b) = \prod_{i=1}^{n} M_{X_i}(b)$$
Доказательство Леммы 1 тривиально и следует напрямую из определений. Распишем экспоненту от суммы как произведение экспонент:
$$M_X(b) = E\left[ e^{b \sum X_i} \right] = E\left[ \prod_{i=1}^{n} e^{bX_i} \right]$$
Поскольку исходные величины $X_i$ взаимно независимы, функции от них (в данном случае — экспоненты $e^{bX_i}$) также являются взаимно независимыми случайными величинами. Для взаимно независимых величин математическое ожидание от их произведения строго равно произведению их индивидуальных математических ожиданий. Это позволяет вынести знак произведения за знак ожидания, завершая доказательство леммы.
🧮 Оценка бернуллиевских величин: Лемма 2 и Лемма 3 23:54
Для завершения доказательства границы Чернова необходимо получить конкретные количественные оценки для индивидуальных бернуллиевских слагаемых. С этой целью формулируется Лемма 2: для бернуллиевской случайной величины $X_i$ с вероятностью успеха $p_i$ её производящая функция моментов ограничена сверху экспоненциальной зависимостью:
$$M_{X_i}(b) \le e^{p_i(e^b - 1)}$$
Для доказательства этого факта используется классическое аналитическое неравенство:
$$1 + y \le e^y$$
Данное неравенство справедливо для всех действительных значений $y$ и легко проверяется методами элементарного математического анализа или простым построением графиков. Распишем математическое ожидание для $e^{bX_i}$ по определению, учитывая, что величина принимает лишь два значения: $0$ и $1$:
$$M_{X_i}(b) = p_i \cdot e^{b \cdot 1} + (1 - p_i) \cdot e^{b \cdot 0} = p_i e^b + 1 - p_i$$
Перегруппировав слагаемые, мы приводим выражение к виду $1 + p_i(e^b - 1)$. Теперь применим упомянутое выше неравенство, взяв в качестве переменной $y$ выражение $p_i(e^b - 1)$. В результате мы получаем искомую верхнюю оценку Леммы 2. Смысл перехода к такой оценке заключается в том, что в показателе экспоненты линейно выделяется параметр $p_i$. При перемножении таких функций для разных индексов $i$ (согласно Лемме 1) показатели степеней будут складываться, и в результирующей экспоненте естественным образом возникнет сумма $\sum p_i$, равная общему математическому ожиданию $\mu$.
Теперь мы готовы собрать все компоненты воедино для доказательства верхнего хвоста границы Чернова. Нам необходимо зафиксировать параметры. Порог $A$ выбирается исходя из условий задачи:
$$A = (1 + \delta)\mu$$
Вспомогательный параметр $b$ выбирается как натуральный логарифм от $(1 + \delta)$:
$$b = \ln(1 + \delta)$$
Если бы мы решали эту задачу с нуля, мы бы оставили параметр $b$ свободной переменной, провели вычисления, получили итоговую функцию, зависящую от $b$, а затем с помощью дифференцирования нашли бы точку минимума, дающую наилучшую (самую жесткую) верхнюю границу. Выбор $b = \ln(1 + \delta)$ является результатом этой оптимизации.
Подставим Лемму 1 и Лемму 2 в наше исходное неравенство, полученное с помощью трюка Маркова:
$$P(X \ge (1 + \delta)\mu) \le \frac{\prod_{i=1}^{n} e^{p_i(e^b - 1)}}{e^{Ab}} = \frac{e^{\sum p_i(e^b - 1)}}{e^{Ab}} = \frac{e^{\mu(e^b - 1)}}{e^{Ab}}$$
Подставляя вместо $b$ значение $\ln(1 + \delta)$, мы получаем, что $e^b = 1 + \delta$, следовательно, числитель превращается в $e^{\mu\delta}$. Знаменатель при этом принимает вид $(1 + \delta)^{(1 + \delta)\mu}$. Мы получили промежуточную функциональную форму границы Чернова:
$$P(X \ge (1 + \delta)\mu) \le \left( \frac{e^\delta}{(1 + \delta)^{1 + \delta}} \right)^\mu$$
Чтобы привести эту громоздкую алгебраическую конструкцию к чисто экспоненциальному виду, формулируется финальная Лемма 3, утверждающая, что полученная дробь не превышает значения $e^{-\frac{\mu\delta^2}{2 + \delta}}$.
Для доказательства Леммы 3 прологарифмируем обе части исходного выражения (без учета степени $\mu$). Логарифм левой части равен:
$$\ln \left( \frac{e^\delta}{(1 + \delta)^{1 + \delta}} \right) = \delta - (1 + \delta)\ln(1 + \delta)$$
Вынесем общий множитель $\mu$ за скобки. Нам потребуется аналитический факт из математического анализа: для всех положительных $x > 0$ справедливо неравенство:
$$\ln(1 + x) \ge \frac{x}{1 + \frac{x}{2}}$$
Данный факт проверяется разложением логарифма в ряд Тейлора: линейный член равен $x$, а знаменатель в правой части гарантирует, что мы получаем строгую нижнюю оценку, отсекая высшие члены ряда. Подставим это неравенство вместо логарифма в наше выражение, заменив переменную $x$ на $\delta$:
$$\delta - (1 + \delta) \frac{\delta}{1 + \frac{\delta}{2}} = \frac{\delta \left(1 + \frac{\delta}{2}\right) - (\delta + \delta^2)}{1 + \frac{\delta}{2}} = \frac{\delta + \frac{\delta^2}{2} - \delta - \delta^2}{1 + \frac{\delta}{2}} = \frac{-\frac{\delta^2}{2}}{1 + \frac{\delta}{2}} = -\frac{\delta^2}{2 + \delta}$$
Умножая полученный показатель на вынесенный ранее множитель $\mu$ и возвращаясь от логарифма к экспоненте, мы получаем окончательный вид верхней границы Чернова: $e^{-\frac{\mu\delta^2}{2 + \delta}}$.
🏫 Педагогика математики: почему модульные доказательства лучше 38:00
Структурирование столь сложного математического доказательства имеет важное методологическое и педагогическое значение. Начинающие математики часто совершают ошибку, пытаясь излагать доказательства абсолютно линейно — шаг за шагом от начала до конца. Профессор поделился личной историей из своей академической карьеры: его самая первая научная статья содержала непрерывное линейное доказательство длиною в 15 страниц. После прочтения его научный руководитель признался, что абсолютно не понял логику вывода. Из-за линейного стиля было невозможно сходу понять, являются ли взаимосвязи между отдельными частями текста ациклическими и корректными.
Рефакторинг доказательства и его разделение на независимые смысловые блоки — Лемму 1, Лемму 2 и Лемму 3 — позволяет лектору сразу дать аудитории целостный высокоуровневый чертеж (blueprint) всей архитектуры вывода. Читатель или слушатель сразу видит, в каких именно узлах системы сосредоточена содержательная идея (использование взаимной независимости, переход к экспоненте), а какие узлы являются чисто механическими, рутинными алгебраическими вычислениями. Из самой Леммы 3 невозможно извлечь глубоких концептуальных инсайтов о природе вероятности — это просто аккуратный алгебраический массаж формул методами математического анализа. Таким образом, модульный подход экономит когнитивный ресурс аудитории.
Более того, такая модульная структура значительно упрощает анализ математических допущений. Если перед исследователем встает задача адаптировать границу Чернова под другие, не бернуллиевские случайные величины, ему не нужно переписывать все доказательство целиком. Взглянув на модульную схему, легко обнаружить, что ни Лемма 1, ни трюк Маркова вообще не использовали тот факт, что величины являются бернуллиевскими. Единственным местом во всем часовом выводе, где этот факт критически потребовался, была Лемма 2. Следовательно, для адаптации формулы под новые типы распределений достаточно заменить лишь Лемму 2, аккуратно вычислив или ограничив сверху новую производящую функцию моментов, а вся остальная цепочка рассуждений останется неизменной.
Включение концепции производящей функции моментов в лекцию также преследовало важную педагогическую цель, несмотря на то, что чисто формально доказательство можно было провести и без явного упоминания этого термина. Можно было просто заявить, что правая часть равна математическому ожиданию $E[e^{bX}]$, и продолжить вычисления. Однако без введения MGF этот шаг выглядел бы для студентов как необъяснимая «черная магия». При доказательстве неравенства Чебышёва возведение в квадрат выглядело логичным, так как изначальная величина могла быть отрицательной. Но идея взять и возвести основание $e$ в степень случайной величины кажется абсолютно противоестественной, если не объяснить, что экспонента — это уникальный инструмент, бережно сохраняющий и структурирующий информацию обо всех моментах распределения. Дополнительно лектор сознательно связал этот материал с предыдущим крупным блоком курса — комбинаторикой и перечислением, где студенты детально изучали обычные производящие функции для подсчета объектов. Демонстрация того, что вероятностные и комбинаторные производные функции — это, по сути, разные диалекты одного и того же математического языка, помогает укрепить междисциплинарные связи в сознании учащихся.
📈 Реальный мир и крах независимости: финансовый кризис 2008 года 47:14
В качестве исторической справки было упомянуто, что это мощное неравенство было открыто выдающимся математиком Германом Черновым (Herman Chernoff), который долгое время работал в MIT. Недавно он отпраздновал свой 100-летний юбилей; его супруга также жива, и они официально считаются старейшей супружеской парой в штате Массачусетс.
Несмотря на колоссальную математическую элегантность, граница Чернова невероятно часто подвергается опасному и некорректному использованию в реальной жизни. Математический аппарат обещает инженерам и аналитикам потрясающие результаты: если слабый закон больших чисел требует повторить случайный эксперимент огромное количество раз (например, $10^{30}$ раз) для снижения вероятности ошибки до уровня $10^{-30}$, то граница Чернова за счет экспоненциального затухания утверждает, что для достижения аналогичной надежности алгоритма достаточно сделать лишь порядка $\ln(10^{30})$ повторений. Случайные величины при определенных условиях концентрируются вокруг своего среднего с невероятно высокой скоростью. Однако люди склонны напрочь забывать о базовом фундаменте, на котором стоит вся эта конструкция: жестком требовании полной взаимной независимости случайных событий.
Ярчайшим примером такого слепого и ошибочного математического моделирования стал мировой финансовый кризис 2008 года. Лектор поделился деталями своего личного бэкграунда: он родился в семье потомственных компьютерных ученых (и отец, и мать, и все родственники были специалистами в Computer Science). Из чувства юношеского протеста он категорически не хотел идти в эту сферу и в студенческие годы активно пробовал себя в альтернативных направлениях, успев до кризиса поработать на Wall Street в сфере количественных финансов (quantitative finance). В тот период финансовая индустрия была увлечена созданием и торговлей сложными деривативами, ключевое место среди которых занимали обеспеченные долговые обязательства — CMO (collateralized mortgage obligations, разновидность облигаций, обеспеченных пулом ипотек).
Механика этого финансового продукта выглядела следующим образом:
- Банки выдают людям кредиты (ипотеку) на покупку жилья.
- Каждый кредит несет в себе риск дефолта — вероятности того, что заемщик в силу жизненных обстоятельств не сможет выплачивать долг.
- Для заемщиков с великолепной кредитной историей этот риск минимален, однако банки начали массово выдавать рискованные кредиты людям с низким кредитным рейтингом (субстандартная ипотека, subprime mortgages).
- Такие кредиты позволяли собирать с заемщиков повышенные проценты, однако держать их на балансе банка было слишком рискованно.
Чтобы избавиться от рисков, финансовые инженеры придумали объединять тысячи таких рискованных субстандартных ипотек в единые пулы, создавая на их основе новые синтетические ценные бумаги. Логика создателей опиралась на математическую иллюзию: да, каждая отдельная ипотека имеет высокий риск дефолта (например, 10%). Но если мы объединим их вместе, то, согласно логике границы Чернова, общее число дефолтов должно жестко сконцентрироваться вокруг своего математического ожидания.
Для продажи этих пулов инвесторам была создана каскадная структура выплат, разделенная на уровни — транши (tranches), работающая по принципу водопада. Убытки от первых дефолтов заемщиков полностью принимал на себя самый нижний, «мусорный» транш. Инвесторы, купившие самый верхний, старший транш (senior tranche), должны были начать нести потери только в том случае, если в пуле одновременно зафиксируют дефолт огромная доля заемщиков — например, более 40%.
Финансовые аналитики и рейтинговые агентства задались вопросом: какова вероятность того, что монета с 10%-й вероятностью выпадения орла при тысяче бросков покажет более 40% орлов? Подставив эти параметры в формулу верхнего хвоста границы Чернова, они получили астрономически малое число, близкое к нулю. На основе этих расчетов рейтинговые агентства со спокойной совестью присвоили старшим траншам CMO наивысший рейтинг надежности — AAA, приравняв их по безопасности к казначейским облигациям США. Это позволило пенсионным фондам и инвестиционным компаниям, скованным жесткими законодательными рамками по ограничению рисков, массово скупать эти активы миллиардными тиражами.
Катастрофическая ошибка заключалась в том, что дефолты по ипотекам не имели абсолютно ничего общего с независимыми подбрасываниями монет. В реальной экономике причины, заставляющие человека объявить себя банкротом (макроэкономический спад, рост безработицы, падение цен на недвижимость), носят масштабный системный характер. Как только экономическая ситуация ухудшилась, сработал эффект домино: дефолты начали происходить лавинообразно и одновременно по всей стране, полностью уничтожив допущение о независимости. Математическая модель, построенная на неверном фундаменте, полностью разрушилась, что привело к коллапсу финансового рынка. В реальной жизни зависимости между случайными величинами представляют собой сложнейшую структуру, изучению которой посвящаются отдельные университетские курсы.