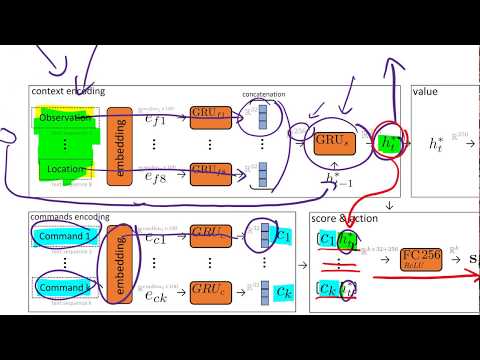
Алгоритм POET, разработанный исследовательской лабораторией Uber AI Labs, предлагает принципиально новый взгляд на обучение с подкреплением через концепцию «открытого» исследования (open-ended learning). В своем подробном видеообзоре независимый ИИ-исследователь Янник Кильхер (Yannic Kilcher) детально разбирает архитектуру этой системы на примере классической робототехнической задачи двуногого шагохода (Bipedal Walker). Ключевая идея авторов работы заключается в отказе от традиционной целенаправленной оптимизации в пользу непрерывной параллельной генерации как самих обучающих сред, так и их решений.
🤖 Анатомия робота и ловушка локальных минимумов 0:00
Экспериментальной базой для демонстрации возможностей алгоритма POET стала популярная задача управления двуногим роботом-шагоходом (Bipedal Walker). Суть симуляции заключается в том, чтобы заставить небольшого схематичного агента продвинуться как можно дальше в правую сторону, преодолевая разнообразные препятствия. Данный кейс традиционно считается сложной проблемой для классического обучения с подкреплением (Reinforcement Learning).
Конструкция виртуального робота обладает фиксированным набором характеристик:
- Исполнительные механизмы: робот имеет две ноги и в общей сложности четыре регулируемых сустава. Управление осуществляется путем подачи определенного крутящего момента (torque) на каждый из этих четырех суставов.
- Сенсорная система: в качестве органов чувств агент использует лидар, состоящий из 16 лучей, направленных под разными углами для сканирования рельефа. Также на стопах робота установлены датчики давления для фиксации контакта с поверхностью, а в корпусе — гироскоп, определяющий угол наклона «головы» относительно земли.
Система поощрения и штрафов в симуляции строго формализована. Робот получает катастрофический штраф в -100 баллов, если он падает (то есть касается земли головой). В процессе движения его текущая награда рассчитывается по формуле, где ключевым фактором является пройденное расстояние по оси X, умноженное на коэффициент 130.
Из этой суммы вычитаются штрафы за нестабильность корпуса (изменение угла наклона) и за избыточное усилие, прикладываемое к суставам. Если агент успешно добирается до финальной точки трассы, его итоговый счет превышает 230 баллов — этот показатель официально считается признаком полного решения задачи.
Сложность ландшафта в симуляторе параметризована и зависит от пяти ключевых факторов:
- Общая шероховатость и холмистость поверхности (roughness).
- Нижняя граница высоты вертикальных препятствий-пеньков (stumps).
- Верхняя граница высоты пеньков.
- Ширина провалов и ям на пути (gaps).
- Частота появления препятствий на единицу дистанции.
Янник Кильхер объясняет, почему стандартные подходы к оптимизации, включая классические эволюционные стратегии (Evolution Strategies), неизбежно терпят неудачу при попытке решить эту задачу на сложных трассах с нуля. Прямолинейный алгоритм быстро учится просто идти направо по ровной поверхности, накапливая за это промежуточные награды.
Однако, столкнувшись с глубокой ямой, такой агент мгновенно падает в нее. Чтобы перешагнуть или перепрыгнуть расщелину, роботу необходимо выполнить сложную последовательность действий: заранее спланировать маневр, поднять ногу и изменить угол наклона корпуса.
В терминах наград подъем ноги наказывается штрафом (например, -5 баллов за изменение стабильного угла). Обычная оптимизация не способна преодолеть этот барьер: она стремится к сиюминутному получению выигрыша и попадает в ловушку локального минимума. Ведущий приводит наглядную аналогию с лабиринтом: чтобы дойти до цели, ИИ часто должен сначала пойти в противоположную сторону, отдалившись от финиша, что классический алгоритм сделать не может, так как видит в этом лишь падение эффективности.
🏛️ Два столпа POET: Курикулум и «промежуточные камни» 9:31
Для обхода фундаментальных ограничений стандартной оптимизации авторы POET обратились к идеям открытого обучения (open-ended learning) и поиску новизны (novelty search). Вместо того чтобы заставлять одну нейросеть штурмовать сложнейшую среду, алгоритм постепенно выстраивает дерево решений. Архитектура POET базируется на двух концептуальных методологиях.
Первым столпом является автоматическое пошаговое обучение (Curriculum Learning). Процесс всегда начинается с максимально тривиальной задачи — движения по абсолютно плоской поверхности, с чем без труда справляется даже базовый алгоритм. Как только базовый навык закреплен, среда начинает плавно и дозированно усложняться: добавляется легкая холмистость, затем небольшие единичные препятствия. Первичный опыт ходьбы выступает в роли своеобразного «предобучения» (по аналогии с NLP-моделями), на фундаменте которого ИИ постепенно осваивает более изощренные паттерны движений, например, случайное преодоление крошечных расщелин.
Вторым, и наиболее критичным компонентом системы, выступает обучение через «промежуточные камни» (stepping-stone learning), совмещенное с трансфером навыков (Transfer Learning) внутри популяции агентов. По словам Янника Кильхера, POET оперирует не одиночной моделью, а целой экосистемой, где параллельно развиваются несколько независимых эволюционных цепочек.
Например, в одной ветке ландшафт сохраняется плоским, но на нем планомерно увеличивают количество и ширину ям. В параллельной ветке ям нет вовсе, но рельеф становится все более грубым, холмистым и каменистым.
Философская суть этого разделения заключается в том, что специфический навык, полученный агентом в процессе адаптации к экстремально бугристому ландшафту, может внезапно оказаться идеальным решением для преодоления широких расщелин в совершенно другой ветке. И наоборот, опыт прыжков через пропасти может помочь преодолеть крутой вертикальный уступ.
Янник Кильхер проводит прямую аналогию с биологической эволюцией на Земле: какое-то эволюционное изобретение, возникшее у птиц для решения их специфических задач, впоследствии может быть перенято и адаптировано млекопитающими для совершенно иных целей в совершенно другой среде обитания. POET целенаправленно ищет такие кросс-доменные пересечения.
🔄 Как устроен цикл POET: От мутации к трансферу 15:47
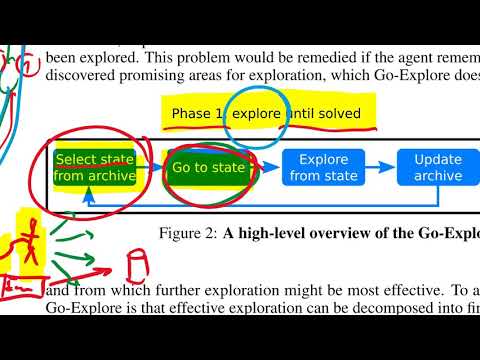
В развернутом виде алгоритм POET представляет собой циклическую последовательность шагов, оперирующую парами «среда — агент». Каждая уникальная сгенерированная среда жестко закреплена за одним индивидуальным ИИ-оптимизатором.
Исполняемый цикл состоит из следующих упорядоченных этапов:
- Мутация сред: на каждом временном шаге алгоритм берет существующие среды и случайным образом модифицирует их параметры. Поскольку среда кодируется вектором из пяти чисел (отвечающих за шероховатость, параметры пеньков и ям), мутация представляет собой небольшое случайное изменение этих численных значений. Это порождает «дочерние» локации. Важное требование к симуляции — ее процедурная природа: минимальный сдвиг в векторе параметров должен приводить к прогнозируемому и плавному изменению физических свойств ландшафта.
- Отбор и фильтрация сред: свежесгенерированные мутировавшие локации проходят строгий пре-скрининг. Они должны соответствовать двум критериям: быть проходимыми (solvable) и обладать новизной (novel). Критерий проходимости означает, что задача не должна быть слишком легкой, но и не должна быть чрезмерно хардкорной — для этого тестируется текущий уровень агентов, и их гипотетический результат должен укладываться в строго заданный диапазон баллов. Критерий новизны оценивается путем вычисления евклидова расстояния от вектора параметров новой среды до векторов всех ранее созданных и существующих сред в популяции. Если дистанция до ближайших соседей достаточно велика, среда признается уникальной и добавляется в общий пул.
- Локальная оптимизация: внутри каждой активной пары агент подвергается стандартному обучению на своей конкретной трассе в течение фиксированного количества шагов. Полная оптимизация на этом этапе не проводится — делается лишь несколько итераций обновления весов (ES-шагов). Из-за ограниченности вычислительных ресурсов самые старые и неэффективные пары сред и агентов постепенно удаляются из памяти системы.
- Попытка трансфера навыков: это важнейший шаг, на котором все существующие в популяции агенты (включая представителей старых поколений) временно переносятся во все имеющиеся среды для проведения перекрестного тестирования. Если в процессе этой глобальной оценки выясняется, что «чужой» агент справляется с конкретной трассой лучше, чем его «коренной» обитатель, происходит замещение. Веса успешного пришельца копируются в данную среду, заменяя старую нейросеть. Авторы подчеркивают важность сохранения всей истории поколений: старые агенты, обучавшиеся на простых трассах, имели больше времени на базовую стабилизацию движений, поэтому их навыки могут неожиданно реанимировать зашедшую в тупик сложную ветку.
Янник Кильхер отдельно отмечает скрытую сложность алгоритма. Процесс содержит колоссальное количество гиперпараметров: шаг мутации, частота трансферных проверок, количество шагов локального обучения, пороговые значения новизны и коэффициенты обучения. По признанию ведущего, обилие этих настроек делает самостоятельную реализацию и отладку POET крайне пугающей и трудоемкой задачей.
🧮 Эволюционные стратегии против градиентного спуска 24:27
Для непосредственного обучения нейросетей внутри сред авторы POET применили эволюционные стратегии (Evolution Strategies, ES), которые выступают эффективной альтернативой классическим градиентным методам обучения с подкреплением (таким как Policy Gradient).
Янник Кильхер кратко поясняет фундаментальную разницу между ними:
- Policy Gradient (например, REINFORCE): в этих методах параметры нейросети (политики) масштабируются напрямую в зависимости от полученной награды. Если действие привело к высокому результату, градиент корректирует веса сети таким образом, чтобы это действие выбиралось чаще в аналогичных ситуациях. Это требует сквозного дифференцирования.
- Evolution Strategies: данный подход работает иначе. Вокруг текущего вектора параметров нейросети генерируется облако случайных «шумовых» модификаций (создается подмножество агентов с немного измененными весами). Все эти зашумленные версии тестируются в среде, и для каждой фиксируется итоговый результат. Затем исходный вектор параметров базовой нейросети сдвигается в направлении тех шумовых векторов, которые показали наилучшую производительность. По мнению ведущего, это изящный метод, незаменимый в тех случаях, когда функцию потерь среды невозможно продифференцировать напрямую для классического обратного распространения ошибки.
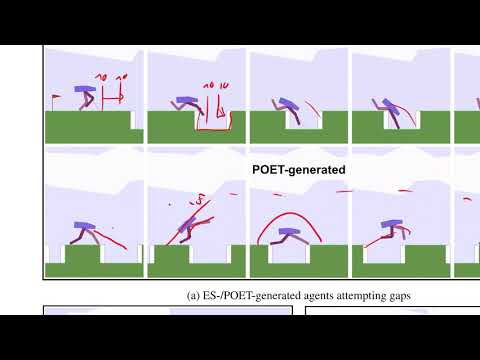
Оценивая экспериментальную часть исследования, Янник Кильхер высказывает долю здорового скептицизма. В оригинальной статье авторы наглядно демонстрируют, что классический алгоритм ES полностью проваливается на сложных трассах, тогда как POET стабильно преодолевает целевой порог в 230 баллов. Однако ведущий называет это сравнение не вполне справедливым.
Дело в том, что POET тестируется в тех сложных средах, которые он сам же плавно сгенерировал в процессе эволюции своего дерева, попутно обучая под них агентов. В то же время базовый алгоритм ES заставляют штурмовать эту финальную комплексную локацию «в лоб», с чистого листа и без предварительного курикулума. У ES просто нет глобальной цели, он решает локальную задачу изоляционно.
Тем не менее, тесты на абляцию (удаление компонентов) доказывают ценность архитектуры. Сравнение POET со стандартным целенаправленным курикулум-обучением (когда сложность повышают линейно к одной конкретной финальной конфигурации ландшафта) показало безоговорочное преимущество открытого подхода.
При росте комплексности среды по всем пяти осям параметров прямолинейный курикулум быстро упирается в тупик и перестает прогрессировать. POET же, благодаря нелинейному трансферу весов между ветками, забирается гораздо дальше по шкале сложности.
В качестве яркого примера трансфера Янник описывает зафиксированный в логах случай: «родительский» агент умел лишь лениво ползти, волоча ноги по земле. В «дочерней» среде появились небольшие пеньки, из-за чего мутировавший агент случайно научился высоко поднимать ноги, чтобы не спотыкаться. Через несколько итераций этот развитый навык перешагивания посредством трансфера вернулся обратно в родительскую среду, существенно увеличив скорость и стабильность тамошнего шагохода.
Эксперименты с отключением функции трансфера (POET без Transfer Learning) подтвердили: без перекрестного обмена опытом популяция способна решать задачи средней тяжести, но никогда не достигает экстремальных уровней сложности. И все же Янник Кильхер рекомендует воспринимать триумфальные графики с определенной долей осторожности, так как создатели комплексных систем всегда склонны вкладывать гораздо больше усилий в тонкую настройку гиперпараметров собственного детища, нежели в полировку базовых алгоритмов сравнения.