Глубокие нейросети как ядерные машины: теоретический взгляд 0:00
В видеоролике Янник Кильхер (Yannic Kilcher) проводит глубокий разбор научной статьи Педро Домингоса (Pedro Domingos) «Every model learned by gradient descent is approximately a kernel machine» («Любая модель, обученная методом градиентного спуска, является приблизительно ядерной машиной»). Основная идея работы заключается в установлении теоретической связи между современными глубокими нейронными сетями и классическими ядерными методами (kernel machines), такими как метод опорных векторов (SVM). Кильхер отмечает, что статья предлагает альтернативный взгляд на процесс обучения нейросетей, интерпретируя веса как суперпозицию тренировочных данных.
🧠 Концепция ядерных машин 4:50
Чтобы понять тезис статьи, необходимо разобраться в том, как работают традиционные ядерные методы. В машинном обучении мы стремимся найти функцию $f$, которая сопоставляет входные данные $x$ с предсказанием $y$.
- Классический подход: В отличие от нейросетей, которые автоматически находят представления данных в разных слоях, ядерные машины строят базу данных всех примеров из обучающей выборки.
- Принцип предсказания: При поступлении нового запроса $x$ ядерная машина сравнивает его с каждым примером из обучающего набора с помощью «ядерной функции» (kernel function), которая измеряет «близость» данных.
- Итог: Предсказание формируется как взвешенная сумма меток обучающих данных, где веса определяются степенью близости (похожести) входного запроса к конкретным точкам выборки.
Янник Кильхер подчеркивает, что выбор ядра — это ключевой этап проектирования таких систем, требовавший ранее серьезных экспертных знаний.
📉 Градиентный спуск и путь модели 10:18
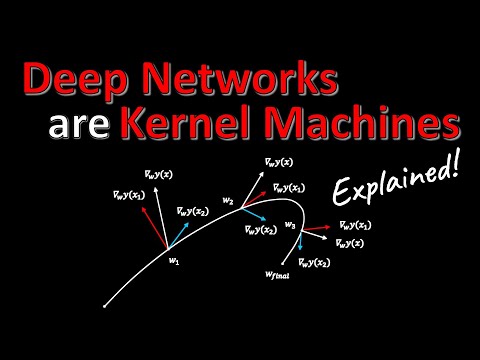
Автор видео сравнивает работу линейной регрессии, обучаемой градиентным спуском, с поведением ядерной машины. В процессе обучения веса модели совершают своего рода «путешествие» от начального состояния $w_0$ до итогового $w_{final}$.
- Траектория обучения: Статья предлагает рассматривать не только финальное состояние модели, но и всю историю изменения весов во время градиентного спуска.
- Чувствительность: Ключевой метрикой в статье является градиент выхода сети по отношению к весам. Это позволяет понять, как изменение весов влияет на предсказание $y$ для конкретной точки данных.
- Сходство векторов: Две точки данных считаются похожими, если изменение весов нейросети в процессе обучения одинаково влияет на изменение их выходных значений.
🔢 Основная теорема и путь обучения 26:05
Теорема 1 статьи утверждает, что в пределе бесконечно малых шагов модель, обученная полным градиентным спуском, математически эквивалентна ядерной машине.
- Path Kernel (Ядро пути): Интегрируя тангенциальные ядра (tangent kernels) вдоль всего пути градиентного спуска, мы получаем «ядро пути».
- Смысл преобразования: Нейронная сеть «запоминает» тренировочные данные в своих весах. По мнению Кильхера, это дает исследователям новый «дуальный» взгляд на проблему: нейросети одновременно находят новые представления данных и сохраняют обучающую выборку в виде суперпозиции.
💡 Выводы и критика 39:17
Янник Кильхер отмечает несколько важных аспектов:
- Interpretability: Представление сети как ядерной машины потенциально повышает интерпретируемость весов, так как они интерпретируются как суперпозиция обучающих примеров.
- Масштабируемость: Автор статьи утверждает, что такой подход преодолевает узкие места масштабируемости классических ядерных методов, так как больше нет необходимости явно вычислять и хранить матрицу Грама (Gram matrix).
- Роль архитектуры: Выбор архитектуры нейросети, по сути, задает способ сравнения данных, предрасполагая алгоритм к поиску определенных признаков.
В заключение Кильхер признает, что, хотя это мощное теоретическое обобщение, оно скорее является способом взгляда на проблему, нежели новым практическим алгоритмом обучения. Он также проводит параллели с методами бустинга (boosting), отмечая, что на определенном уровне абстракции многие алгоритмы обучения начинают выглядеть как вариации одного и того же процесса запоминания данных.




