Retentive Network: архитектурный прорыв или временный успех? 0:28
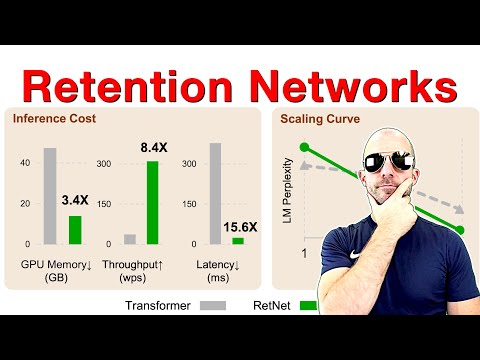
В мире больших языковых моделей (LLM) появился новый амбициозный игрок — Retentive Network (RetNet). Янник Килчер (Yannic Kilcher) в своем обзоре анализирует одноименную статью исследователей из Microsoft Research и Университета Цинхуа, которые заявляют, что создали архитектуру, превосходящую стандартный Transformer по всем ключевым параметрам: потреблению памяти GPU, пропускной способности, латентности и масштабируемости. По мнению Килчера, главный вопрос заключается в том, действительно ли эта архитектура «лучше во всем», или же за линейную природу модели приходится платить скрытыми компромиссами, которые еще предстоит выявить.
«Невозможное триединство» и линейность 2:31
Авторы RetNet утверждают, что им удалось разрешить так называемое «невозможное триединство» (impossible triangle), объединив в одной модели три характеристики:
- Эффективность инференса (low-cost inference): отсутствие квадратичного роста потребления памяти при увеличении длины последовательности.
- Параллелизм при обучении (training parallelism): возможность обучать модель на всей последовательности одновременно, а не по одному токену.
- Высокая производительность (strong performance): экспериментально подтвержденные результаты, сопоставимые или превосходящие Transformer.
Традиционный Transformer, по словам Килчера, обладает мощным механизмом внимания, позволяющим каждому токену «видеть» все предыдущие, что дает преимущество в параллельном обучении. Однако использование функции softmax создает квадратичную сложность, из-за которой при инференсе требуется хранить огромные объемы данных (KV-кэш).
Ключевая идея RetNet заключается в отказе от softmax. Делая архитектуру линейной, разработчики получают возможность переключаться между двумя режимами:
- Параллельная форма: аналогично Transformer, позволяет использовать всю последовательность как обучающий пример.
- Рекуррентная форма: позволяет накапливать информацию в буфере фиксированного размера, что делает инференс крайне экономичным.
Механика работы: от теории к практике 16:06
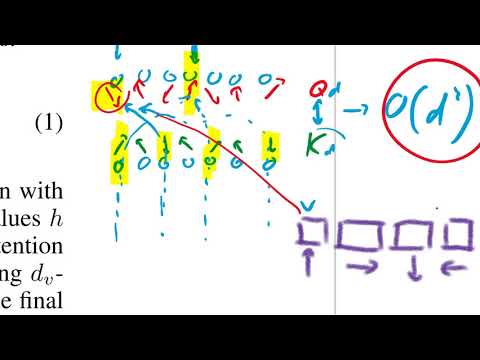
Архитектурно RetNet напоминает Transformer, где многоголовое внимание (multi-head attention) заменено на мультимасштабное удержание (multi-scale retention). Основные технические особенности:
- Causal Mask с затуханием: в отличие от классической «каузальной маски», здесь используется скалярный коэффициент затухания
gamma, который уменьшает влияние старых токенов по мере удаления от текущего. - Гейтированное мультимасштабное удержание: авторы применяют разные коэффициенты затухания для разных «голов» внимания. Это позволяет одним частям модели фокусироваться на недавнем контексте, а другим — удерживать в памяти всю последовательность.
- Chunk-wise рекурсия: модель делит длинные последовательности на фрагменты (chunks), комбинируя рекуррентный подход (накопление в буфере) для далекого прошлого и параллельный режим для текущего сегмента.
Перспективы и скепсис 26:40
Килчер отмечает, что экспериментальные результаты выглядят многообещающе — RetNet стабильно обходит Transformer в задачах языкового моделирования. Однако он выражает сдержанность:
- Масштаб экспериментов: хотя размеры моделей значительны, они все еще не достигают масштабов «триллионных» моделей, используемых в индустрии.
- Линейность как компромисс: по мнению Килчера, отказ от нелинейности
softmaxможет быть как преимуществом, так и ограничением. Он предполагает, что со временем будут обнаружены задачи, где RetNet будет уступать Transformer, несмотря на текущие «фантастические» показатели.
С точки зрения автора видео, RetNet является крайне интересным объектом для оптимизации, так как всё, что можно выразить линейно, открывает огромные возможности для аппаратных ускорений, недоступных для сложных нелинейных архитектур.