В обучении моделей машинного обучения существует тонкая грань между недостаточной точностью и избыточной сложностью. В рамках курса Machine Learning Specialization основатель DeepLearning.AI Эндрю Ын (Andrew Ng) подробно разбирает два фундаментальных препятствия — недообучение (underfitting) и переобучение (overfitting). Понимание этих концепций критически важно для создания алгоритмов, способных давать адекватные прогнозы на реальных данных, а не просто «зазубривать» примеры из тренировочного набора.
📉 Проблема недообучения и феномен высокого смещения 1:09
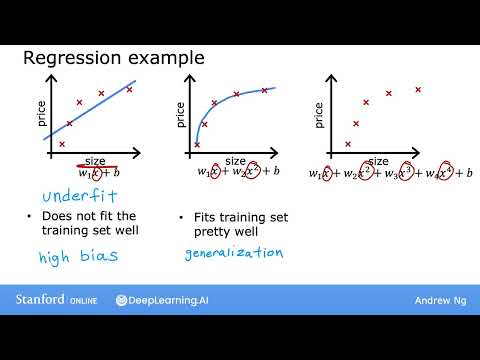
На примере задачи прогнозирования цен на жилье в зависимости от площади дома Эндрю Ын демонстрирует, что происходит, когда выбранная модель слишком проста для имеющихся данных . Если попытаться аппроксимировать нелинейную зависимость (где цены обычно «выравниваются» при росте площади) обычной прямой линией, алгоритм не сможет уловить структуру данных .
Этот феномен в машинном обучении называется недообучением (underfitting). Эндрю Ын выделяет следующие ключевые характеристики этого состояния:
- Высокое смещение (High Bias): Модель имеет сильное «предубеждение», что данные линейны, вопреки очевидным доказательствам обратного .
- Плохая работа на тренировочных данных: Алгоритм не справляется даже с теми примерами, на которых учится .
- Упрощение реальности: Модель игнорирует явные паттерны, присутствующие в наборе данных .
Автор подчеркивает, что термин «bias» (смещение/предубеждение) в техническом смысле отличается от социального контекста (дискриминация по полу или этнической принадлежности), хотя проверка алгоритмов на этические предубеждения также является критически важной задачей разработчика .
🎯 Идеальный баланс и концепция обобщения 3:34
В качестве альтернативы Ын предлагает использовать квадратичную функцию. В этом случае модель описывается кривой, которая гораздо лучше соответствует распределению точек . Такой подход позволяет достичь того, что в индустрии называют хорошим обобщением (generalization).
Основные аспекты успешного обобщения по мнению автора:
- Прогноз на новых данных: Способность модели делать точные предсказания для примеров, которые она никогда раньше не видела (например, для дома, которого не было в обучающей выборке) .
- Умеренная сложность: Модель достаточно сложна, чтобы уловить тренд, но не настолько, чтобы реагировать на случайный шум .
- Статус «Just Right»: Эндрю Ын называет такие модели «в самый раз», проводя аналогию со сказкой о Златовласке (Goldilocks) и трех медведях, где героиня искала кашу идеальной температуры .
🎢 Переобучение: когда точность становится врагом 4:43
На другом полюсе находится переобучение (overfitting). Это происходит, когда мы используем слишком сложную модель, например, полином четвертого порядка для пяти точек данных . В этом случае кривая может пройти идеально через каждую точку, в результате чего функция стоимости (cost function) станет равной нулю .
Однако такая модель, по словам Ына, обладает «высокой дисперсией» (High Variance) и имеет ряд критических недостатков:
- Чрезмерная изменчивость: Если изменить тренировочные данные хотя бы на одну точку, вид кривой может измениться радикально .
- Алогичные предсказания: Кривая может совершать резкие скачки вверх и вниз. Например, модель может предсказать, что огромный особняк стоит дешевле маленького дома из-за причудливой формы функции .
- Отсутствие обобщения: Модель «заучивает» шум и специфические особенности тренировочного набора, становясь бесполезной для реального применения .
🛡️ Переобучение в задачах классификации 8:53
Проблемы смещения и дисперсии актуальны не только для регрессии, но и для классификации (например, при использовании логистической регрессии для диагностики опухолей) .
Эндрю Ын сравнивает три типа разделяющих границ:
- Линейная граница (Недообучение): Простая прямая линия, которая лишь приблизительно разделяет злокачественные и доброкачественные опухоли, допуская много ошибок .
- Эллиптическая граница (Оптимально): Квадратичная функция, которая хорошо разделяет классы, допуская лишь незначительные ошибки на пересекающихся данных. Ын утверждает, что такая модель будет лучше всего работать с новыми пациентами .
- Сложная ломаная граница (Переобучение): Если использовать полиномы очень высокой степени, алгоритм будет «извиваться», чтобы идеально обойти каждую точку в обучающей выборке . Такая граница выглядит крайне неестественно и, скорее всего, не отражает реальную медицинскую логику .
🛠️ Как бороться с дисперсией? 11:25
В завершение лекции Эндрю Ын резюмирует, что главная цель инженера — найти «золотую середину» между слишком простыми и слишком сложными моделями. В качестве одного из самых эффективных инструментов для борьбы с переобучением он называет регуляризацию (regularization) . Этот метод позволяет минимизировать риск высокой дисперсии и заставляет алгоритмы работать стабильнее, что будет темой следующих занятий курса .




