Методология оценки уровня загрязнения воздуха в городской среде 0:03
Завершение этапа проектирования системы мониторинга качества воздуха требует разработки методологии, позволяющей оценивать уровни загрязняющих веществ в точках, где отсутствуют физические датчики. Процесс создания такой модели начинается с построения простого базового решения (baseline), которое впоследствии может быть улучшено с помощью методов машинного обучения. В качестве примера рассматривается город Богота, где необходимо интерполировать данные о качестве воздуха между существующими станциями мониторинга.
Метод ближайшего соседа: простая база для оценок 0:39
Наиболее интуитивно понятным подходом является метод «ближайшего соседа» (nearest neighbor method). Логика метода заключается в предположении, что показатели качества воздуха в конкретной точке наиболее близки к измерениям на ближайшей к ней станции мониторинга.
- Принцип работы: для любой выбранной точки на карте берется последнее значение PM 2.5 с ближайшего сенсора.
- Универсальность: данный подход применим не только к пространственным данным, но и к временным рядам или любым другим характеристикам, где соседние значения коррелируют между собой.
- Ограничения: эксперт отмечает, что хотя этот метод является разумным первым приближением, он не всегда точно отражает физическую реальность распространения загрязняющих веществ.
Алгоритм K-ближайших соседей (KNN) и взвешивание 1:56
Для повышения точности оценки используется расширение базового метода — алгоритм K-ближайших соседей (K-nearest neighbors, KNN), где $K$ — это количество учитываемых станций мониторинга. При использовании нескольких соседей возникает задача объединения их данных в единую оценку.
В реальных приложениях простого усреднения недостаточно, поэтому применяется схема взвешивания, основанная на удаленности станций. В текущем проекте используется обратно-квадратичное взвешивание расстояния (inverse distance weighting):
- Каждому из $K$ ближайших соседей присваивается вес.
- Вес обратно пропорционален квадрату расстояния от станции до точки оценки.
- Итоговое значение является взвешенным средним, что позволяет учитывать влияние более близких датчиков сильнее, чем удаленных.
Практическая реализация и анализ точности 3:02
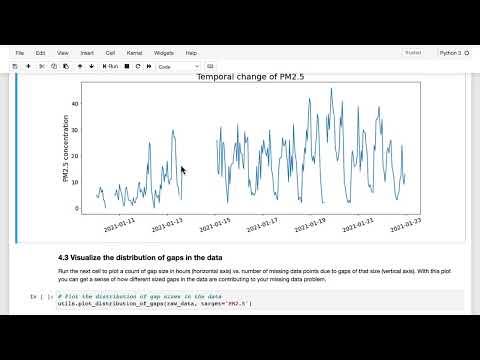
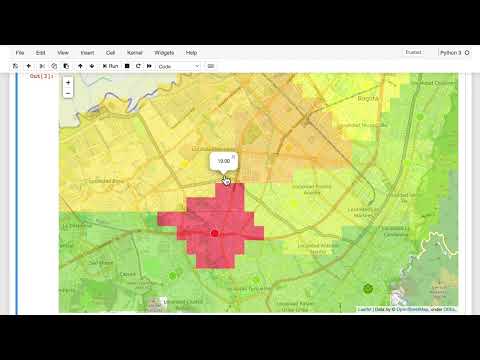
Работа в лабораторной среде начинается с подготовки набора данных, содержащего географические координаты (широту и долготу) и измерения уровня PM 2.5. Создание сетки (grid) над городом позволяет визуализировать оценочные данные в каждом ячейке.
- Визуализация: на карте станции с прямыми измерениями отмечаются белым контуром, а расчетные значения (полученные нейронной сетью или KNN) — черным. Пользователь может выбирать временную метку для анализа ситуации в конкретный момент.
- Оценка ошибок: для проверки эффективности модели используется метрика средней абсолютной ошибки (Mean Absolute Error, MAE).
- Результаты: при $K=1$ средняя ошибка составляет около 8 единиц (микрограмм на кубический метр). Дальнейшее увеличение $K$ до 3–4 позволяет немного улучшить точность, однако после этого значения улучшения становятся незначительными.
Выводы и ограничения проектирования 8:35
По завершении этапа проектирования создана полноценная система: от модели для заполнения пропущенных данных в существующих точках до алгоритма интерполяции между ними. Несмотря на возможность применения более сложных алгоритмов, эксперт подчеркивает наличие фундаментального физического ограничения: реальный уровень загрязнения между датчиками остается неизвестным.
По мнению ведущего, любая модель в данном контексте будет лишь приближенной оценкой, и метод KNN с взвешиванием по расстоянию часто является достаточно эффективным решением, которое трудно значительно превзойти в условиях неполных данных.