В своем видеообзоре популярный AI-исследователь Янник Кильхер (Yannic Kilcher) подробно разбирает научную работу «Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention». Автор объясняет, как замена стандартного механизма внимания на ядерные функции позволяет преодолеть вычислительные ограничения современных моделей. Ключевая идея статьи заключается в том, что авторегрессионные трансформеры можно математически свести к особому типу рекуррентных нейронных сетей (RNN), что позволяет радикально ускорить генерацию данных.
⚠️ Проблема квадратичной сложности классических трансформеров 1:31
Современные модели обработки последовательностей, такие как BERT или GPT, построены на базе архитектуры Transformers. Главным элементом этой архитектуры является механизм внимания (attention mechanism), который сопоставляет каждый элемент входной последовательности со всеми остальными. Для каждого токена (например, слова или его части) нейросеть генерирует три вектора: ключ (key), запрос (query) и значение (value).
Процесс вычисления классического внимания устроен следующим образом:
- Для конкретного токена берется его вектор запроса.
- Вычисляется скалярное произведение этого запроса со всеми векторами ключей других токенов в последовательности.
- Полученные результаты пропускаются через функцию софтмакс (softmax) для формирования нормированного распределения вероятностей (гистограммы).
- На основе этого распределения происходит агрегация векторов значений.
Главная вычислительная проблема, по словам Янника Кильхера, заключается в том, что каждый токен должен выполнить скалярное произведение своего запроса со всеми ключами. Если длина входной последовательности составляет $n$ токенов, то вся процедура требует выполнения порядка $O(n^2)$ операций. Квадратичная сложность по времени и памяти делает обработку длинных текстов, аудиозаписей или изображений крайне ресурсоемкой.
🧠 Переход к линейному вниманию через ядерные методы 9:40
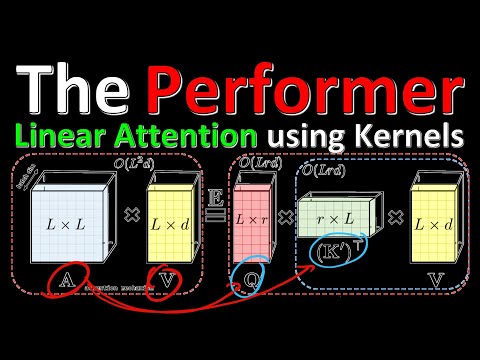
Авторы исследуемой работы предлагают альтернативное решение под названием «линейный трансформер» (Linear Transformer). Они переформулировали операцию вычисления матрицы внимания, представив функцию софтмакс через функцию сходства (similarity function). Обычный софтмакс делает операцию нелинейной, что заставляет хранить в памяти огромные промежуточные матрицы.
Исследователи обратились к теории ядерных методов (kernel methods). Согласно математическому определению, если функция сходства является ядром, то существует такое отображение $\Phi(x)$, при котором значение ядра для двух векторов эквивалентно скалярному произведению их проекций в пространстве более высокой размерности. Подобный подход позволяет заменить сложную нелинейную функцию софтмакса простым линейным скалярным произведением в скрытом высокоразмерном пространстве.
Применение свойства ассоциативности матричного умножения позволяет изменить порядок вычислений. В классическом трансформере сначала перемножаются матрицы запросов и ключей ($Q \times K^T$), образуя промежуточную матрицу размером $n \times n$. В линейном трансформере за счет ассоциативности можно сначала перемножить проекции ключей на векторы значений, сформировав одну общую матрицу контекста для всего слоя. После этого вектору запроса достаточно умножиться на эту матрицу. В результате вычислительная сложность падает с квадратичной до линейной — $O(n)$.
В качестве конкретного инструмента для проецирования векторов авторы применили функцию активации ELU (Exponential Linear Unit). По утверждению разработчиков, эта конфигурация обеспечивает вычислительную стабильность и сохраняет распределение положительных значений сходства.
📊 Результаты экспериментов и вычислительная эффективность 24:19
В ходе тестирования архитектуры авторы сопоставили линейный трансформер с классической моделью и алгоритмом Reformer. Reformer использует локально-чувствительное хеширование (LSH) для снижения квадратичной сложности, однако, как отмечает Кильхер, этот метод неизбежно приводит к потере точности из-за стохастической природы хеширования.
На логарифмических графиках зависимости времени обработки и объема памяти GPU от длины последовательности видно, что кривая классического трансформера имеет очень крутой наклон. Линейный трансформер демонстрирует практически плоскую (линейную) характеристику, разделяя лидерство с Reformer по объему используемой памяти, но превосходя его по скорости. Как предполагает ведущий, Reformer уступает из-за вычислительных накладных расходов на проведение множественных раундов хеширования.
Показатели прироста скорости зависят от длины обрабатываемых данных:
- На речевом датасете линейная модель оказалась в 3 раза быстрее классической.
- На задаче обработки изображений LM MNIST скорость увеличилась в 300 раз.
- На датасете CIFAR-10 модель показала ускорение в 4000 раз.
При этом Янник Кильхер обращает внимание на важный нюанс: на сложных задачах вроде распознавания речи классический трансформер с софтмаксом все еще удерживает лидерство по точности, опережая линейную модель. По мнению блогера, софтмакс остается более мощным математическим инструментом, однако колоссальный выигрыш в скорости делает линейную архитектуру крайне привлекательной для практического применения.
🗺️ Концептуальное отличие: связь с тематическим моделированием 28:33
Чтобы объяснить качественную разницу между алгоритмами, Кильхер проводит аналогию с классическим тематическим моделированием (topic modeling).
В стандартном механизме внимания каждый выходной токен имеет возможность напрямую «посмотреть» на абсолютно любой входной токен последовательности и решить, сколько информации из него забрать. Это обеспечивает высокую гибкость, но порождает квадратичную зависимость.
Линейный трансформер работает иначе:
- Функция $\Phi$ переводит все входные ключи и запросы во внутреннее пространство, которое можно интерпретировать как пространство «тем» (topics).
- Каждый входной токен распределяет свое содержимое по фиксированному набору этих скрытых тем.
- Выходные токены больше не видят отдельные входные элементы напрямую. Они считывают информацию исключительно из агрегированных векторов тем.
Таким образом, квадратичная зависимость от длины последовательности $n$ исчезает. Вместо нее появляется зависимость от размерности $D$ промежуточного пространства тем. Выходной токен взаимодействует лишь с линейной комбинацией признаков в этом пространстве.
🔄 Авторегрессионные трансформеры как рекуррентные сети 33:48
Вторая важная часть научной работы посвящена математическому доказательству того, что авторегрессионный трансформер по своей сути эквивалентен рекуррентной нейронной сети (RNN).
Авторегрессионные модели предсказывают каждый следующий элемент на основе всех предыдущих. При обучении трансформеров используется механизм каузального маскирования (causal masking): специальная треугольная матрица-маска запрещает токенам подглядывать в будущее. Это позволяет вычислять ответы для всех позиций параллельно во время обучения, что выгодно отличает трансформеры от классических RNN, которые можно обучать только последовательно, шаг за шагом.
Однако на этапе инференса (генерации текста пользователю) трансформер вынужден заново просчитывать связи для каждого нового сгенерированного слова, что сильно замедляет работу. Авторы статьи показали, что если переписать формулу линейного внимания без софтмакса, то промежуточные матрицы агрегации контекста ($S$ и $Z$) можно обновлять итеративно.
В такой формулировке матрицы $S$ и $Z$ начинают выполнять роль скрытого состояния (hidden state) рекуррентной сети. Модель на этапе инференса превращается в чистую RNN: она просто принимает текущий токен, обновляет скрытое состояние за $O(1)$ и выдает следующий токен. Это позволяет развернуть модель даже в обычном веб-браузере для мгновенной генерации текстов или изображений.
🛠️ Каузальное маскирование и скрытые компромиссы 41:14
Янник Кильхер подчеркивает, что утверждение «трансформеры — это RNN» содержит в себе важную техническую оговорку. Эквивалентность рекуррентным сетям возникает только из-за применения каузального маскирования, которое Кильхер называет «вынужденным хаком» для параллельного обучения.
По мнению блогера, каузальная маска искусственно ослабляет теоретическую мощность архитектуры трансформера. В полноценном трансформере промежуточные слои могут строить сложные перекрестные связи между прошлым и будущим, не нарушая строгого авторегрессионного принципа на финальном выходе. Если убрать маску, свести модель к RNN станет невозможно.
Различие в математической логике RNN и трансформеров Кильхер объясняет на примере выполнения программного кода:
- Пусть модель обрабатывает вызов функции $f(a)$, где аргумент $a$ находится далеко впереди по тексту.
- Трансформер может просто направить вектор внимания вперед и считать значение $a$, когда оно появится.
- RNN не способна смотреть вперед. Чтобы разрешить эту зависимость, рекуррентная сеть вынуждена концептуально закодировать и удерживать в своем скрытом состоянии всю логику ветвления функции (например: «если $a=1$, то сделать X; если $a=2$, то Y») до тех пор, пока переменная не будет прочитана. Из-за этого работа с памятью в RNN становится бесконечно более сложной.
В завершение обзора ведущий демонстрирует примеры генерации изображений (цифр MNIST). На сгенерированных картинках видно, что линейный трансформер иногда допускает характерные геометрические артефакты (например, рисует прямые линии там, где у классической модели получается плавный наклон). Это доказывает, что линейное приближение не идеально, хотя колоссальный выигрыш в скорости делает данную технологию важным шагом в эволюции архитектур машинного обучения.