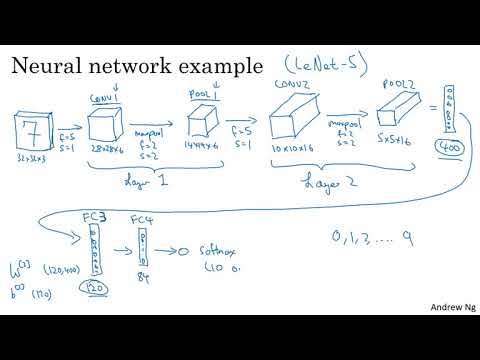
В новом уроке от DeepLearning.AI рассматривается практический пример построения сверточной нейронной сети (CNN) для распознавания рукописных цифр. Основатель проекта Эндрю Ын на примере архитектуры, вдохновленной классической сетью LeNet-5, объясняет принципы объединения различных слоев и логику распределения параметров в современных моделях глубокого обучения.
🏗️ Анатомия классической сверточной сети 0:00
В качестве базового примера Эндрю Ын рассматривает задачу распознавания рукописных цифр (от 0 до 9) на цветных изображениях размером 32x32x3 пикселя . Архитектура, представленная в уроке, во многом вдохновлена классической сетью LeNet-5, созданной Яном Лекуном много лет назад, и использует схожие принципы выбора гиперпараметров .
Процесс обработки данных начинается с первого слоя (Layer 1):
- Входные данные: RGB-изображение 32x32x3.
- Сверточный слой (Conv1): используются 6 фильтров размером 5x5, шаг (stride) равен 1, паддинг (padding) отсутствует.
- Результат свертки: на выходе получается объем 28x28x6 .
- Активация: к результату применяется нелинейная функция, например, ReLU.
- Пулинг (Pool1): применяется Max Pooling с фильтром 2x2 и шагом 2. Это сокращает высоту и ширину представления вдвое, сохраняя количество каналов.
- Итоговый размер после первого блока: 14x14x6 .
📏 Проблема терминологии и подсчета слоев 2:20
Эндрю Ын обращает внимание на существующую в литературе непоследовательность в именовании слоев. Некоторые исследователи считают сверточный слой и слой пулинга отдельными слоями, в то время как другие объединяют их в один .
Автор курса придерживается следующей логики:
- Слоем считается только тот этап обработки, который содержит обучаемые веса (параметры) .
- Поскольку слой пулинга не имеет весов, а обладает лишь гиперпараметрами, Ын объединяет Conv1 и Pool1 в единый «Слой 1» (Layer 1) .
- Названия «Conv1» и «Pool1» в данном контексте указывают на их принадлежность к первому логическому уровню нейросети .
🔗 От сверток к полносвязным слоям 3:45
Второй этап (Layer 2) повторяет структуру первого, но с увеличением глубины каналов. Для входа 14x14x6 применяется свертка с 16 фильтрами 5x5 (stride 1, no padding), что дает на выходе 10x10x16 . После последующего Max Pooling (2x2, stride 2) размер уменьшается до 5x5x16 .
Переход к классической архитектуре нейронных сетей происходит через следующие шаги:
-
Выравнивание (Flattening): объем 5x5x16 разворачивается в вектор из 400 нейронов (5
-
5
- 16 = 400) .
- Первый полносвязный слой (FC3): 400 входных единиц плотно соединяются со 120 нейронами. Матрица весов здесь имеет размерность 120x400 .
- Второй полносвязный слой (FC4): количество нейронов сокращается до 84 .
- Выходной слой (Softmax): для классификации цифр используется Softmax с 10 выходами, соответствующими вероятностям для каждой цифры от 0 до 9 .
📉 Анализ параметров и общие паттерны 7:15
Эндрю Ын выделяет несколько ключевых закономерностей, которые полезно учитывать при проектировании собственных сетей. По его мнению, одна из лучших стратегий для новичка — не изобретать собственные настройки гиперпараметров с нуля, а использовать архитектуры, которые уже доказали свою эффективность в научных публикациях .
Основные тенденции при углублении в сеть:
- Размеры изображения (высота и ширина) обычно постепенно уменьшаются: в примере они сокращаются с 32x32 до 5x5 .
- Количество каналов, напротив, возрастает: от 3 (RGB) до 6, а затем до 16 .
- Большая часть параметров нейросети сосредоточена именно в полносвязных слоях (FC), в то время как сверточные слои имеют их относительно немного .
- Размер активаций должен уменьшаться постепенно. По словам Ына, слишком резкое падение размера активаций на ранних этапах обычно негативно сказывается на производительности модели .
В заключение Эндрю Ын отмечает, что понимание того, как эффективно комбинировать эти блоки, требует интуиции, которую лучше всего развивать через изучение множества конкретных примеров .




