Player of Games: Универсальный алгоритм для игр с любой информацией 0:00
Алгоритм Player of Games, разработанный исследователями DeepMind, представляет собой значительный шаг к созданию универсального искусственного интеллекта, способного эффективно играть в игры как с полной, так и с неполной информацией. В интервью ведущий канала Yannic Kilcher обсуждает с Мартином Шмидом, первым автором одноимённой статьи, как их разработка объединяет методы поиска в дереве игры, заимствованные из AlphaZero, и алгоритмы для работы с неопределённостью, такие как counterfactual regret minimization. Главная идея проекта — создать алгоритм, не требующий ручной подстройки под конкретные правила игры, а способный обучаться «с нуля» через самоигру.
🎮 Преодоление барьера неполной информации 0:41
В отличие от классических игр вроде шахмат или го, где вся информация о состоянии доски доступна игрокам, игры с неполной информацией (например, покер или Scotland Yard) скрывают часть данных от участников.
- Шахматы и го: Использование поиска в дереве игры с ограниченной глубиной, где нейронная сеть оценивает привлекательность узлов, которые алгоритм не может просчитать до конца.
- Игры с неполной информацией: Здесь игроки не знают точного состояния противника (например, карт в покере или местоположения мистера Икса в Scotland Yard). По словам Шмида, игроки должны оперировать «публичными состояниями» и оценивать вероятности возможных «приватных состояний» (диапазоны карт противника).
Шмид отмечает, что оптимальная стратегия в таких играх требует рандомизации действий — если игрок будет предсказуем, противник легко его обыграет.
🧠 Архитектура: синтез AlphaZero и DeepStack 8:14
Player of Games объединяет два фундаментальных подхода: мощный поиск AlphaZero и достижения DeepStack, который первым победил профессиональных игроков в безлимитный покер.
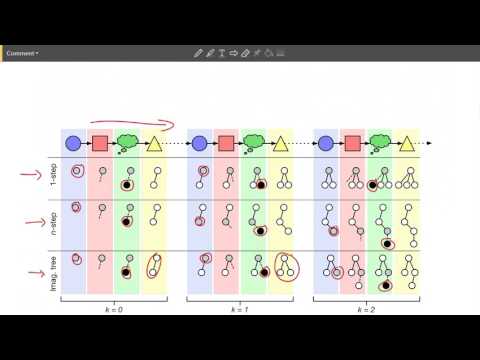
- Функция ценности (Value Function): Центральный компонент алгоритма. Она отображает публичное состояние и текущие убеждения игрока (диапазоны противника) в оценку выгоды подигры.
- Поиск в дереве игры: В отличие от AlphaZero, где будущее не меняет прошлого, в играх с неполной информацией изменение стратегии в узле влияет на интерпретацию прошлых ходов. Алгоритм вынужден обновлять всё дерево после каждого расширения, что значительно увеличивает вычислительную сложность.
- Обучение: Алгоритм использует самоигру, собирая обучающие примеры в процессе взаимодействия с «самим собой». В качестве целей (target) используются результаты локального поиска, которые по мере обучения становятся всё более точными оценками.
🏆 Результаты и ограничения 34:43
Хотя Player of Games не стремится превзойти специализированные алгоритмы в каждой конкретной игре, он демонстрирует впечатляющую генеральную способность.
- Покер: Алгоритм показал преимущество в 7 миллибигблайндов на руку по сравнению с Slumbot, лучшим на тот момент открытым покерным ботом.
- Scotland Yard: Даже при использовании огромного количества итераций поиска специализированный алгоритм Pinbot уступал Player of Games, который обучался через общие методы самоигры.
Тем не менее, у алгоритма есть два существенных ограничения:
- Проблема масштабирования: Если размер «приватного состояния» (например, количество комбинаций карт) слишком велик, дерево игры взрывается, и алгоритм теряет эффективность.
- Зависимость от модели: В текущем виде для работы алгоритма требуется точная модель правил игры (симулятор), в отличие от алгоритма MuZero, который обучается в латентном пространстве.
Мартин Шмид подчёркивает, что конечная мечта исследователей в DeepMind — создание алгоритма, которому «всё равно», в какую среду его поместили, будь то Atari, робототехника или ответы на вопросы, однако до полной реализации этого видения предстоит ещё долгий путь.