Компания OpenAI представила SWE-Lancer — инновационный бенчмарк, призванный оценить способности искусственного интеллекта в решении реальных задач по разработке программного обеспечения. В отличие от традиционных тестов, SWE-Lancer измеряет эффективность моделей не в абстрактных баллах, а в реальной рыночной стоимости выполненных работ, используя данные фриланс-платформы Upwork на общую сумму более 1 миллиона долларов . Этот шаг знаменует переход от теоретических оценок ИИ к анализу его прямого экономического влияния на рынок труда и индустрию кодинга.
💰 SWE-Lancer: Бенчмарк на миллион долларов 0:00
OpenAI представила SWE-Lancer как инструмент для исследования экономического эффекта от развития моделей ИИ . Бенчмарк включает в себя более 1400 реальных задач по программной инженерии, взятых с платформы Upwork . Общая стоимость этих задач в реальных выплатах составляет 1 000 000 долларов США .
По словам ведущего Уэса Рота, этот бенчмарк делает важный скачок от обсуждения оценок к реальной валюте и оплате труда . Задачи в наборе данных крайне разнообразны:
- Исправление мелких багов стоимостью от 50 долларов.
- Реализация сложных функций с гонораром до 32 000 долларов .
- Управленческие задачи, где модели выступают в роли техлидов .
Рот отмечает, что OpenAI стремится сопоставить производительность моделей с денежной стоимостью, чтобы лучше понять, какой процент рабочей силы может быть автоматизирован или заменен инструментами ИИ в будущем .
🛠 Методология: как ИИ «зарабатывает» деньги 3:53
Исследователи разделили задачи на две основные категории, чтобы протестировать различные навыки моделей:
- Индивидуальный исполнитель (Individual Contributor, IC): Модели должны генерировать программные патчи для решения конкретных технических проблем. Результатом является код, удовлетворяющий требованиям .
- Менеджер (SWE Manager): Модели действуют как технические руководители, выбирая лучшее предложение по реализации из нескольких вариантов, предложенных другими пользователями .
Процесс тестирования IC-задач имитирует реальную работу над кодом. Разработчики берут кодовую базу и «откатывают» её до состояния, предшествующего исправлению ошибки человеком . Модели предлагается создать решение, которое затем проверяется с помощью сквозных тестов (end-to-end), написанных людьми . Если тест пройден — ИИ «получает» выплату, если нет — заработок равен нулю .
В менеджерских задачах выбор ИИ сравнивается с решением, которое принял опытный человек-менеджер в реальной ситуации . Если ИИ выбирает тот же путь решения, задача считается выполненной успешно.
📈 Кейс Expensify: динамическое ценообразование и сложность 6:42
В качестве примера реальных данных Рот приводит компанию Expensify — публичную компанию с оборотом 300 миллионов долларов, торгующуюся на Nasdaq, чьими сервисами пользуются 12 миллионов человек . Expensify использует открытый репозиторий и выставляет задачи на Upwork с конкретными выплатами для фрилансеров .
Особый интерес представляет механизм определения стоимости задач. Рот описывает случай с исправлением ошибки валидации почтового индекса, за который ИИ «получил» 8 000 долларов . Изначально за эту задачу предлагали 1 000 долларов, но цена динамически росла:
- Неделя 1: Предложено 1 000 долларов, задача не решена .
- Неделя 2: Цена выросла до 2 000 долларов, пять предложенных решений были отклонены .
- Неделя 4: Цена увеличилась до 4 000 долларов, когда стала ясна истинная сложность задачи, требующая валидации по всем мировым почтовым кодам .
- Итог: После итераций с менеджером вознаграждение составило 8 000 долларов .
По мнению Уэса Рота, такая система является отличным способом оценки сложности, так как цена формируется глобальным рынком . Если мировое сообщество не готово решить задачу за тысячу, цена растет, пока не будет найден исполнитель.
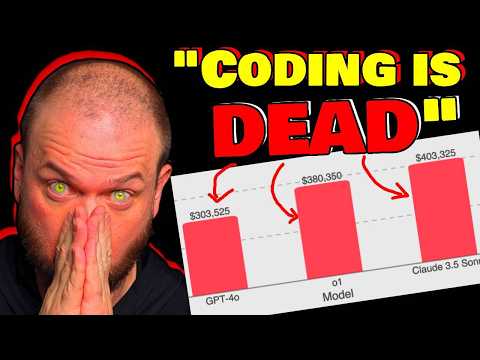
🏆 Результаты: Claude против OpenAI 9:47
Результаты тестирования современных моделей оказались выше ожиданий ведущего. Лидером среди доступных моделей стала Claude 3.5 Sonnet, которая смогла «заработать» 403 325 долларов из миллиона возможных .
Статистика выплат для других моделей:
- Claude 3.5 Sonnet: $403 325 (около 40% всех задач) .
- OpenAI o1: $380 000 (38%) .
- GPT-4o: $300 000 (30%) .
Рот подчеркивает, что невыпущенная модель OpenAI o3 показывает еще более впечатляющие результаты. В тесте SWE-Verified она на 42% эффективнее, чем Claude 3.5 Sonnet . Экстраполируя эти данные, Рот предполагает, что o3 могла бы заработать более 572 000 долларов на задачах SWE-Lancer .
🧠 Связь между «размышлениями» и прибылью 12:00
Исследование подтвердило прямую зависимость между объемом вычислительных ресурсов (compute), затраченных на «размышления» модели, и её финансовой эффективностью. На примере модели o1 было показано, что увеличение времени на рассуждения (от низкого до высокого уровня усилий) значительно повышает точность решения сложных и дорогих задач .
Рот проводит аналогию с призом Arc AGI, где модель o3 при низких вычислительных затратах показывает результат 76%, а при высоких (High Compute) — достигает 88%, превосходя базовый уровень способностей человека . Хотя стоимость запуска модели в режиме глубоких размышлений велика (для o3 в тестах она могла составлять более 300 000 долларов по розничным ценам API), точность ответов растет экспоненциально .
⚠️ Будущее работы: ИИ против фрилансера 15:03
Одной из самых тревожных тем обсуждения стало сравнение выплат фрилансерам со стоимостью API для выполнения тех же задач . По мнению Рота, цифры могут оказаться «пугающими».
Ведущий предполагает следующие сценарии:
- Задача, за которую человек получает 8 000 долларов, может быть решена ИИ-моделью по цене «меньше, чем заезд в Starbucks» .
- Если использовать локальные open-source модели, стоимость решения сложных задач может свестись к затратам на электроэнергию .
Рот отмечает стремительный прогресс: еще недавно люди выполняли 100% этой работы, а сейчас ИИ уже справляется с 40% . С учетом невыпущенных моделей (таких как o3 или внутренние разработки OpenAI), доля задач, доступных только людям, может сократиться до 43% и ниже в ближайшем будущем .
В завершение Уэс Рот призывает не паниковать, но признает, что ситуация выглядит «вызывающей беспокойство» . Он полагает, что подобные бенчмарки станут новым полем битвы для ИИ-гигантов, где OpenAI, Google и Anthropic будут бороться за звание самого экономически эффективного «цифрового инженера» .




