В интервью для канала Machine Learning Street Talk финский исследователь и предприниматель Харри Валпола (Harri Valpola), основатель компании Curious AI, подробно рассказал о переходном этапе от систем искусственного интеллекта первого типа к системам второго типа (System 2 AI). В центре дискуссии — разработка алгоритмов модельного обучения с подкреплением (Model-Based Reinforcement Learning), способных моделировать окружающую среду и детально планировать действия. Участники обсудили, как преодолеть фундаментальные ошибки планирования с помощью шумоподавляющих автокодировщиков и как построить успешный глубокотехнологичный бизнес на оптимизации сложных промышленных задач.
🧠 Концепция Систем 1 и 2 в искусственном интеллекте 0:04
Развитие искусственного интеллекта на протяжении последнего десятилетия во многом определялось доминированием подходов глубокого обучения. По мнению Харри Валпола, имеющего 25-летний опыт в индустрии ИИ, текущее состояние технологий эквивалентно так называемой «Системе 1» из классической концепции психолога Даниэля Канемана. Система 1 — это автопилот нашего сознания: она работает быстро, интуитивно и бессознательно, подобно навыку езды на велосипеде. Современные нейросети представляют собой такие «рефлекторные машины», которые берут огромные массивы данных и выстраивают эффективное мгновенное отображение входных сигналов в выходные.
Однако индустрии не хватает «Системы 2» — медленного, осознанного мышления, способного справляться с принципиально новыми ситуациями за счет внутренних симуляций и построения моделей мира. Харри Валпола отмечает инверсию между скоростью работы систем и скоростью их обучения:
- Система 1 мгновенно выдает ответ, но требует колоссального объема данных (Big Data) для долгого и постепенного обучения.
- Система 2 требует времени на внутренние рассуждения и симуляции (работает медленно), но обучается невероятно быстро и эффективно, обходясь малым количеством данных.
Каноническим примером Системы 2 в действии Валпола считает алгоритм AlphaZero (и AlphaGo) от DeepMind. Этот ИИ способен просчитывать ходы вперед с помощью поиска по дереву Монте-Карло (MCTS), зная правила игры. Однако AlphaZero не является универсальным искусственным интеллектом (AGI), поскольку модель мира и правила игры в него были заложены разработчиками вручную. Главный вызов для современной науки, по словам гостя, заключается в том, чтобы заставить ИИ самостоятельно извлекать и изучать модель мира из сырых данных.
Для иллюстрации разницы в обучении Валпола приводит психологический эксперимент с распределением карт по скрытым правилам, в котором участвовали люди и обезьяны. И приматы, и люди начинают угадывать классы карт методом проб и ошибок, постепенно улучшая результат (путь Системы 1). Но в определенный момент человек включает Систему 2, эксплицитно формулирует правило (например: «черно-белые картинки — класс А, цветные — класс Б»), и точность его ответов мгновенно взлетает до 100%. Обезьяны на такое обобщение не способны.
🛑 Проблема планирования: атака на собственную модель мира 8:28
В модельном обучении с подкреплением (Model-Based RL) агент обучается на основе «модели мира» (World Model) — нейросети, которая предсказывает следующее состояние среды в ответ на выбранное действие. Оптимизация траектории (Trajectory Optimization) заключается в том, что алгоритм заглядывает вперед на определенный горизонт планирования $H$ и выбирает цепочку действий, ведущую к максимальной награде.
Как объясняет Янник Килчер, этот процесс таит в себе критическую уязвимость: оптимизатор начинает яростно эксплуатировать любые, даже самые мелкие неточности и пробелы в обученной модели мира. Харри Валпола и исследователи из Curious AI метафорически называют это «эффективной преднамеренной атакой алгоритма планирования на собственную форвардную модель».
Кильчер приводит наглядную аналогию с роботом в лабиринте:
- Агент исследует несколько комнат и строит карту (зеленая зона распределения данных).
- На границе этой зоны модель еще не знает, есть ли дальше стена, потому что никогда там не была.
- Алгоритм планирования, пытаясь найти кратчайший путь к цели, прокладывает маршрут напрямую сквозь неизведанное пространство, ошибочно предполагая, что преград нет.
- В реальности робот врезается в стену.
Чем мощнее и эффективнее ваш алгоритм оптимизации и планирования, тем сильнее он будет разрушать адекватность поведения, цепляясь за ложные высокоэффективные «лазейки» в предсказаниях нейросети. В итоге возникает огромный разрыв между тем, что ИИ ожидает увидеть по своей модели, и тем, что происходит на самом деле.
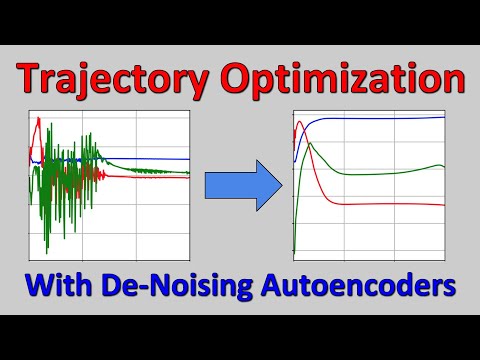
🛠️ Решение от Curious AI: шумоподавляющие автокодировщики как предохранитель 14:04
Чтобы обуздать эпистемическую неопределенность (незнание модели о неизведанных зонах), ученые часто используют байесовские подходы или ансамбли нейросетей. Однако Харри Валпола утверждает, что гауссовские процессы слишком громоздки для крупных промышленных объектов с тысячами датчиков, а ансамбли полностью ломаются, если против них применить эффективные градиентные методы планирования — оптимизатор быстро находит точки, где ошибаются сразу все модели в ансамбле.
На конференции NeurIPS компания Curious AI представила фундаментальную работу «Regularizing trajectory optimization with denoising autoencoders». Они предложили изящное математическое решение: использовать шумоподавляющий автокодировщик (Denoising Autoencoder, DAE), обученный на тех же траекториях, что и модель среды.
Суть метода заключается в следующем:
- Автокодировщик обучается понимать плотность распределения обучающих данных.
- Доказано, что DAE естественным образом вычисляет градиент логарифма вероятности входного распределения ($\nabla \log p(x)$).
- Во время планирования, когда алгоритм пытается увести траекторию в область ложных наград за пределы изученного многообразия, этот градиент буквально «выталкивает» планировщик обратно в безопасную зону высокой плотности данных.
Валпола с иронией называет этот механизм «анти-любопытством» (anti-curiosity). Вместо того чтобы поощрять агента лезть в незнакомые места, алгоритм жестко удерживает планирование в рамках того, что модель знает наверняка. Это создает надежный «жилет безопасности» вокруг мощных нейросетевых архитектур вроде LSTM.
🏭 Практическое применение: от компьютерных игр к очистным сооружениям 15:19
В то время как большинство исследовательских групп тестируют алгоритмы Model-Based RL в виртуальных средах вроде Pacman (Nvidia GameGAN) или VizDoom, стартап Curious AI сфокусировался на управлении тяжелыми нелинейными промышленными процессами — бумажными фабриками и очистными сооружениями.
Янник Кильчер описал классическую проблему на примере химического реактора: есть резервуар, два входных трубопровода с клапанами, один выходной клапан и сложная химическая реакция с задержками по времени. Задача — удерживать показатели на целевой линии и не превысить лимит давления.
Обычный контроллер справляется с этим посредственно и медленно. Если же запустить стандартный ИИ с оптимизацией траектории без регуляризации, то из-за ошибок модели управляющие клапаны начинают хаотично и бешено дергаться вверх-вниз, постоянно пробивая критический лимит давления. Внедрение шумоподавляющего автокодировщика от Curious AI позволяет системе мгновенно и невероятно плавно стабилизировать процесс.
Аналогичным образом технология применима к городским очистным сооружениям (септическим системам). Харри Валпола подтвердил, что ведет проекты с экспертами в этой области. Очистная станция включает в себя непредсказуемые биологические факторы (бактерии, очищающие воду) и огромные задержки. Моделировать это физически или химически почти невозможно, но глубокие нейросети прекрасно выстраивают причинно-следственные связи на основе исторических данных работы операторов.
Гость также озвучил важный технологический инсайт:
«Я не думаю, что разумно применять обучение с подкреплением напрямую к визуальным задачам (пикселям). Намного правильнее использовать старое доброе компьютерное зрение для извлечения признаков, а уже поверх этого компактного представления запускать reinforcement learning».
Благодаря колоссальным мощностям современных процессоров, вычислительное время для работы такой Системы 2 в продакшене стало тривиальным. ИИ способен принимать решения за миллисекунды, тогда как физическая инерция на заводах исчисляется часами.
💼 Стратегия глубокотехнологичного стартапа: инвесторы, патенты и секреты 41:20
Создание коммерческого предприятия на базе фундаментальной науки — тяжелейшая задача. По словам Валпола, Curious AI провела 4,5 года исключительно за разработкой алгоритмов и тестированием технологий, прежде чем выкатить готовый продукт на рынок. Это стало возможным только благодаря феноменальному терпению инвесторов, которые знали Харри по его предыдущему успешному бизнесу.
Валпола делится ключевыми советами для основателей ИИ-стартапов:
- Выбор бизнес-модели: нужно сразу решить, строите ли вы компанию ради скорой продажи технологическому гиганту (Acquisition Target) или планируете развивать независимый устойчивый бизнес. Curious AI пошла по второму пути.
- Фокус на вертикалях: для 90% ИИ-стартапов правильная стратегия — выбрать одну узкую индустриальную нишу и решить ее проблему любой ценой, даже если там не понадобится ИИ.
- Путь игрового движка: Curious AI выбрала редкий и опасный путь — создание горизонтальной платформы (аналога игрового движка) для ключевых процессов крупного бизнеса. Оптимизация таких процессов даже на 10% приносит корпорациям миллионные прибыли.
Отвечая на вопрос о балансе между академической открытостью и коммерческой тайной, Харри Валпола встал на защиту патентной системы. По его мнению, для маленькой независимой компании патенты — это единственный способ безопасно публиковать статьи в рецензируемых журналах. Если публиковать алгоритмы в открытом доступе без патентов, крупные игроки мгновенно поглотят твою рыночную нишу.
В этом коренное отличие стартапов от корпораций уровня Google или Meta. Google может позволить себе бесплатно отдавать обученные языковые модели вроде T5, потому что их реальный продукт — это не алгоритмы распознавания, а реклама и поисковый движок, чьи главные секреты и гигантские массивы данных они никогда и никому не раскрывают.
META---