Известный ИИ-исследователь и блогер Янник Кильчер (Yannic Kilcher) представил подробный разбор научных работ Юргена Шмидхубера, посвященных революционной концепции под названием Upside-Down Reinforcement Learning (UDRL). В отличие от классического обучения с подкреплением, где алгоритмы пытаются предсказать будущую награду, этот подход полностью переворачивает привычную парадигму и напрямую сопоставляет желаемый результат с необходимыми действиями. Подобная смена фокуса позволяет трансформировать сложную задачу RL в стандартное обучение с учителем (Supervised Learning) и извлекать пользу даже из самых неудачных попыток агента.
🔄 Переворот в обучении с подкреплением: Отказ от предсказания наград 0:01
Новая научная работа Юргена Шмидхубера, описывающая концепцию обучения с подкреплением «вывернутого наизнанку» (Upside-Down Reinforcement Learning), была представлена ИИ-сообществу на специализированном воркшопе конференции NeurIPS. Янник Кильчер выражает огромный энтузиазм по поводу этой идеи, поскольку она предлагает свести традиционно нестабильный процесс обучения RL-агентов к гораздо более предсказуемому обучению с учителем (Supervised Learning).
Чтобы наглядно оценить радикальность предложенного подхода, Кильчер предлагает вспомнить классическую постановку задачи RL на примере стандартной игры для Atari (например, Marine Commander). В такой игре агент видит экран (текущее состояние среды), отслеживает шкалу кислорода, избегает враждебных рыб и собирает золотые монеты. Традиционная цель агента в этой системе — продержаться в живых как можно дольше и максимизировать получаемую от монет награду. Однако парадигма UDRL предлагает полностью изменить принципы взаимодействия ИИ с окружающей средой и поступающими сигналами вознаграждения.
🧠 Суть концепции Upside-Down Reinforcement Learning (UDRL) 4:09
Главная особенность UDRL заключается в том, что базовые понятия входов и выходов в структуре алгоритма меняются местами.
В классических методах (таких как Q-learning или алгоритмы градиента политики) нейросеть принимает на вход текущее наблюдение среды и пытается либо выдать распределение вероятностей для доступных действий, либо присвоить каждому действию математическую ценность (value). Например, система рассчитывает, что шаг влево принесет в будущем +3 очка, шаг вправо обернется штрафом в -1 очко, а выстрел даст 0. На основе этих прогнозов агент выбирает наиболее выгодный путь.
В архитектуре UDRL на вход модели, помимо стандартного наблюдения за средой, подается совершенно новый компонент — команда (command), которая кодирует будущие цели и желания разработчика. По словам Кильчера, входной запрос к агенту теперь формулируется следующим образом: «Вот твое текущее состояние. Я хочу, чтобы ты получил ровно 5 единиц награды за следующие 2 временных шага — сделай так, чтобы это произошло». Нейросеть, в свою очередь, обязана подобрать конкретное действие, удовлетворяющее этой жестко заданной цели.
По мнению ведущего, модель, обученная по такой схеме, способна не просто банально максимизировать выигрыш, но и формирует фундаментальное, общее понимание устройства виртуального мира. Она начинает четко осознавать, какие именно цепочки действий ведут к самым разнообразным исходам.
🛠️ Превращение траекторий в обучающие примеры: Пошаговый разбор 7:36
Процесс подготовки данных и обучения в UDRL кардинально отличается от индустриальных стандартов. В традиционном обучении с подкреплением один пройденный агентом эпизод (цепочка переходов от состояния к состоянию с получением промежуточных наград) дает системе, по сути, лишь один комплексный пример для обновления общей политики. В рамках UDRL одну и ту же историческую траекторию агента можно декомпозировать на огромное количество независимых обучающих примеров.
Кильчер описывает пошаговый алгоритм формирования обучающей выборки из сохраненных логов среды:
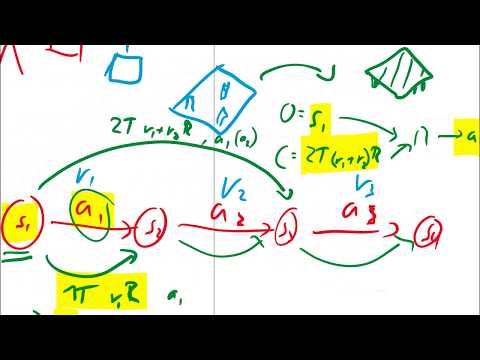
- Одношаговое сопоставление: Если в истории зафиксирован переход из состояния $s_1$ в состояние $s_2$ посредством действия $a_1$ с получением награды $r_1$, система генерирует точечный пример. На вход модели отправляется наблюдение $s_1$ и команда «получить награду $r_1$ за 1 шаг». Целевым выходом, который должна выдать сеть, назначается действие $a_1$. Это абсолютно корректно, так как в прошлом данный опыт уже был успешно пережит агентом.
- Многошаговое сопоставление: Горизонт планирования искусственно расширяется. Для того же исходного состояния $s_1$ конструируется более масштабная команда: «получить суммарную награду $r_1 + r_2$ ровно за 2 временных шага». На вход сети подается состояние $s_1$ и эта агрегированная цель. Целевым выходом модели снова становится действие $a_1$, поскольку именно оно послужило успешным триггером для запуска всей цепочки.
Важнейшим преимуществом UDRL, как подчеркивает Кильчер, является способность системы эффективно учиться абсолютно на любых сессиях, включая самые провальные и нелепые. В стандартном RL плохой опыт утилизируется или игнорируется. В UDRL, если агент в состоянии $s_3$ совершил глупость $a_3$ и заработал штраф в условные минус пять миллиардов очков, этот кейс тоже идет в дело. Модель прилежно запоминает: «Если ты находишься в точке $s_3$ и твоя цель — мгновенно потерять кучу очков за 1 шаг, то выбирай действие $a_3$».
Когда наступает этап реальной эксплуатации (evaluation), разработчик просто никогда не станет отправлять на вход агенту команду на получение гигантского штрафа. Нейросеть, зафиксировав в памяти жесткую связь действия $a_3$ с катастрофическим исходом, гарантированно отбросит этот вариант и выберет безопасную альтернативу.
📊 Сравнение с существующими подходами: UVF и Hindsight Experience Replay 12:44
Концепция Юргена Шмидхубера имеет очевидные пересечения с такими известными инструментами машинного обучения, как универсальные функции ценности (Universal Value Functions, UVF) и механизм повторения опыта «задним числом» (Hindsight Experience Replay, HER). Тем не менее, Кильчер указывает на принципиальные концептуальные различия между ними.
В рамках UVF в условиях простого сеточного мира (Grid World) агент параллельно учится перемещаться в самые разные координатные точки (подцели). Однако классические UVF-функции на этапе обучения не используют точное численное значение награды в качестве прямого входного параметра сети. Они лишь аппроксимируют общую ценность достижения локальной точки. UDRL же выстраивает полноценное обучение поведению на базе целевой награды и жесткого лимита времени.
Технология HER работает по иной логике: если робот пытался дойти до конкретного объекта, но промахнулся и ушел в угол комнаты, HER виртуально подменяет изначальное техническое задание. Алгоритм заявляет: «Представим, что этот случайный угол и был нашей истинной целью с самого начала», после чего начисляет агенту виртуальный плюс. По мнению Кильчера, прямое введение понятной «команды» на вход нейросети в UDRL выглядит гораздо более элегантным и перспективным решением.
💻 Алгоритм обучения и генерации эпизодов 16:49
Вторая научная работа, опубликованная одновременно с теоретическим обоснованием Шмидхубера, была подготовлена группой инженеров-практиков и сфокусирована на проведении реальных экспериментов. Авторы формализовали так называемую функцию поведения (Behavior Function) вида $B(s, c) \to a$, которая принимает на вход текущее состояние $s$, команду $c$ и преобразует их в действие $a$. Это в корне отличается от Q-learning, завязанного на оценку пар состояние-действие.
Архитектура распределенного обучения в данном исследовании опирается на классическое разделение вычислительных ролей:
- Обучающий модуль (Learner): Центральный монолитный процесс, который непрерывно оптимизирует и обновляет веса базовой модели поведения на основе входящего потока данных.
- Агенты-сборщики (Workers): Множество параллельных процессов или машин, которые скачивают свежую версию нейросети у Learner, запускают ее внутри симуляторов для генерации новых игровых сессий и отправляют свежий опыт назад в буфер.
Кильчер детально описывает математический цикл генерации новых эпизодов агентами-сборщиками с целью непрерывного повышения качества работы ИИ:
- Новые сессии генерируются на основе выборки из верхней части буфера повторения (Replay Buffer), который предварительно жестко сортируется по величине итогового возврата. То есть для анализа всегда берутся исключительно лучшие исторические прохождения.
- Временной горизонт планирования ($h$) для следующего захода рассчитывается как среднее арифметическое от длины этих выбранных успешных эпизодов.
- Параметр желаемой награды (Desired Return) выбирается случайным образом из равномерного распределения в диапазоне между $M$ и $M + S$, где $M$ — это среднее значение наград в лучших исторических сессиях, а $S$ — их стандартное отклонение.
Подобный математический трюк с диапазоном $M \dots M+S$, как объясняет Кильчер, искусственно заставляет модель выходить за рамки комфорта и расширять свои границы. Разработчики буквально ставят перед ИИ задачу: «Ты уже умеешь стабильно собирать определенный объем наград за это время, а теперь попробуй сделать еще чуть-чуть больше». За счет встроенного механизма экстраполяции модель нащупывает новые эффективные паттерны поведения, ставит новые рекорды и отправляет их обратно модулю Learner, запуская тем самым бесконечную спираль самосовершенствования системы.
⚖️ Ограничения парадигмы и результаты тестирования 23:29
Несмотря на оригинальность концепции, Кильчер делится и долей здорового скепсиса. Как утверждает ведущий, Upside-Down RL фактически никак не решает фундаментальную дилемму исследования и эксплуатации (exploration-exploitation dilemma). Алгоритм по-прежнему опирается на постепенное, инкрементальное улучшение вокруг уже известных траекторий. В хардкорных играх с крайне редкой (разреженной) наградой, таких как Montezuma's Revenge, UDRL рискует намертво застрять в локальном минимуме, и для их прохождения все еще будут необходимы специализированные поисковые движки уровня Go-Explore.
Тем не менее, экспериментальная часть статьи наглядно доказывает превосходство UDRL в специфических сценариях. В стандартной цифровой среде Lunar Lander, где небольшая порция наград стабильно выдается агенту на каждом шаге, классический алгоритм максимизации вознаграждения A2C обходит UDRL. Авторы предположили, что такой плотный поток подсказок идеален для классического RL.
Чтобы проверить устойчивость систем, исследователи радикально модифицировали Lunar Lander: они полностью отключили все промежуточные награды, перенеся выдачу всех очков строго в финальный кадр успешного завершения эпизода. В этой измененной среде с предельно разреженной наградой UDRL безоговорочно разгромил классические подходы.
Благодаря тому, что вывернутый наизнанку алгоритм изначально учится комплексной структуре времени и целеполагания, агент без проблем выполняет команды вида: «удерживай нулевую награду на протяжении 50 шагов, а затем забери законную тысячу очков на сотом шаге». Классические же методы максимизации в таких условиях моментально слепнут. Подводя итог, Кильчер выражает искреннее восхищение нестандартным стилем мышления Шмидхубера и резюмирует, что сейчас наступило потрясающее время для наблюдения за эволюцией нейросетей.