Обучение алгоритмов оптимизации — одна из наиболее интригующих и сложных областей современного мета-обучения. Исследователь в области машинного обучения Янник Килчер (Yannic Kilcher) подробно разобрал амбициозную работу команды Google Research, посвященную созданию эффективных обучаемых оптимизаторов и их способности к рекуррентному самообучению. Несмотря на колоссальные вычислительные ресурсы, инвестированные в этот проект, практическая жизнеспособность и масштабируемость предложенного подхода вызывают у экспертного сообщества серьезные вопросы.
🛠️ От ручных признаков к эволюции алгоритмов 0:00
Исторически развитие компьютерного зрения начиналось с ручного проектирования признаков: инженеры создавали фиксированные фильтры (например, фильтры Собеля или градиентные детекторы) для поиска углов и контуров на изображениях. Появление глубокого обучения изменило этот подход, позволив нейросетям самостоятельно извлекать высокоуровневые признаки из сырых данных, что привело к технологическому прорыву в обработке изображений, звука и текста. Исследователи из Google Research предлагают экстраполировать эту логику на процессы оптимизации, заменив созданные человеком математические формулы обучаемыми нейросетевыми алгоритмами.
Оптимизация глубоких нейросетей представляет собой сложную невыпуклую задачу, где ландшафт функции потерь изобилует локальными минимумами, резкими обрывами и протяженными плоскими участками. Популярные человеческие алгоритмы (такие как AdaGrad, RMSprop или Adam) содержат эвристические механизмы адаптации: AdaGrad автоматически масштабирует шаг для каждого измерения отдельно, а Adam подстраивается под изменения крутизны склонов во времени. Идея обучаемого оптимизатора заключается в том, чтобы представить шаг обновления весов не в виде жестко заданной формулы, а как гибкую функцию, параметры которой настраиваются в ходе предварительного мета-обучения.
🧠 Архитектура обучаемого оптимизатора: шаг назад в инженерию? 15:42
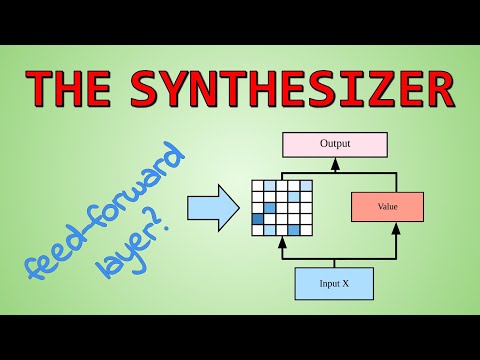
Конструктивно предложенный оптимизатор устроен так, что с каждым отдельным параметром оптимизируемой сети ассоциируется собственная ячейка памяти LSTM и небольшая полносвязная многослойная нейросеть (MLP). На каждом шаге эта MLP генерирует два численных коэффициента, которые определяют итоговое изменение весов целевой модели.
Входные признаки, подаваемые в мета-сеть:
- Текущее значение градиента целевого параметра.
- Первый момент градиента (momentum).
- Второй момент градиента (используемый в методах вроде AdaGrad).
- Общая норма градиента по всему тензору.
- Динамика значений функции потерь на обучающей и валидационной выборках.
По мнению Янника Килчера, обилие входных признаков вступает в прямое противоречие с исходной философией глубокого обучения. В чистом нейросетевом подходе на вход достаточно было бы подавать лишь текущий вес и градиент, позволяя внутренней памяти LSTM самостоятельно вычислять моменты и историю изменений. Килчер считает, что авторы статьи остановились на полпути к полноценному ИИ-оптимизатору, вернувшись к классическому «проектированию признаков» (feature engineering) и предоставив модели слишком много человеческих подсказок.
🧬 Как обучить оптимизатор без градиентов: эволюционные стратегии 23:01
Фундаментальное препятствие при создании обучаемых оптимизаторов — невозможность сквозного обратного распространения ошибки (backpropagation) через весь цикл обучения внутренней модели. Если оптимизация требует тысяч шагов, честный расчет градиентов для мета-сети приводит к взрывному росту требований к памяти и нестабильности вычислений. Чтобы обойти это ограничение, исследователи отказались от вычисления производных в пользу эволюционных стратегий (Evolution Strategies, ES).
По оценке Янника Килчера, применяемый метод по своей сути является «прославленным случайным поиском» или методом конечных разностей. Параметры мета-оптимизатора слегка возмущаются в случайных направлениях, формируя популяцию решений, после чего алгоритм сдвигает базовую оценку в сторону наиболее успешных траекторий. Для вычисления псевдо-градиентов авторы используют математический трюк с логарифмической производной, заимствованный из алгоритма REINFORCE. Полученные значения затем передаются в стандартный оптимизатор Adam, который выполняет внешнее обновление весов мета-модели. Килчер подверг критике псевдокод и текстовое описание этой механики в статье, назвав их запутанными и скрывающими ключевую логику взаимодействия переменных.
📊 Датасет из задач: ограничения масштаба proxy-тестов 30:35
Для обучения мета-алгоритма авторам потребовалось создать структуру, где роль отдельных примеров (семплов) играют не изображения или тексты, а полноценные сценарии обучения нейросетей (TaskSet). Один элемент такого датасета может представлять собой обучение пятислойной сверточной сети на датасете MNIST с размером батча 32 в течение 10 тысяч итераций. Итоговый набор данных включает более 6000 уникальных задач, охватывающих рекуррентные сети, авторегрессионные потоки, языковое моделирование и вариационные автокодировщики.
Чтобы процесс внешнего обучения оставался вычислительно подъемным, авторы ввели жесткое ограничение: один шаг обучения любой внутренней задачи должен занимать менее 100 миллисекунд. Янник Килчер подчеркивает, что эта рамка вынудила исследователей тестировать алгоритм исключительно на крошечных архитектурах и простых выборках уровня MNIST и CIFAR-10. По его мнению, в современной индустрии эффекты масштаба определяют всё: оптимизация гигантских моделей вроде BERT или GPT подчиняется другим закономерностям, и там традиционно доминирует классический SGD с моментом. Обучение мета-сети на мелких proxy-задачах делает ее нерепрезентативной для реальных крупномасштабных IT-проектов.
📉 Результаты и иллюзия «неявной регуляризации» 34:06
Главное преимущество готового обучаемого оптимизатора заключается в полном отсутствии гиперпараметров: он не требует долгого подбора скорости обучения (learning rate) и запускается за один проход. Эксперименты показывают, что он уверенно превосходит стандартный Adam без калибровки, однако уступает человеческим алгоритмам, если для последних проводится глубокий координатный поиск параметров (grid search) на протяжении сотен и тысяч итераций. При этом нейросетевой оптимизатор потребляет в 5 раз больше оперативной памяти, чем Adam.
При изучении траектории оптимизатора на тестовой квадратичной функции авторы зафиксировали, что он активно стягивает веса к началу координат $(0,0)$, и интерпретировали это как свойство «неявной регуляризации». На малых объемах данных такое поведение действительно помогает бороться с переобучением и улучшает показатели валидационного подмножества. Тем не менее, Янник Килчер относится к такой трактовке скептически, приводя два ключевых контраргумента:
- Человечество давно использует модификацию AdamW, которая решает задачу явного штрафования весов (weight decay) аналогичным образом.
- При переходе к более крупным задачам (например, 14-слойному ResNet на CIFAR-10) обучаемый оптимизатор попросту не может эффективно минимизировать ошибку на обучающей выборке.
Килчер утверждает: не стоит путать гениальную регуляризацию с тривиальной неспособностью алгоритма пробить плато функции потерь. Общая тенденция экспериментов демонстрирует явный регресс: на малых задачах обучаемый оптимизатор лидирует, на средних — сравнивается с классическими методами, а на крупных архитектурах начинает необратимо отставать.
🔄 Компилятор, который не смог: самообучение и мета-параметры 45:27
Финальным аккордом исследования стала попытка запустить рекурсивное самообучение: использовать первую версию мета-оптимизатора для обучения его следующей, улучшенной модификации (по аналогии с компилятором, компилирующим собственный исходный код). Данные из приложения к статье показывают, что этот процесс быстро затухает. Классический Adam справляется с обучением мета-сети гораздо успешнее, чем сам обучаемый оптимизатор, пытающийся настроить собственные веса.
Килчер также деконструирует заявление об «отсутствии гиперпараметров» у предложенного решения. На этапе проектирования самой мета-системы инженеры внедрили колоссальное количество жестко заданных и произвольных констант:
- Принудительное ограничение (clipping) нормы градиента строго на уровне 5.
- Использование тригонометрических функций синуса для масштабирования.
- Специфические логарифмические трансформации модулей чисел.
Все эти архитектурные решения представляют собой те же самые скрытые гиперпараметры, перенесенные с микро-уровня на макро-уровень, что оставляет открытым вопрос о необходимости ручной настройки системы человеком.
🕊️ Мем об этике ИИ в действии 49:51
В финале обзора Янник Килчер обращает внимание на обязательный раздел статьи, описывающий потенциальные этические и социальные последствия научной работы (Broader Impact Statement). Он отмечает, что в академической среде сформировался устойчивый шаблон для таких деклараций, укладывающийся в ироничную формулу: «Технологии — это хорошо, технологии — это плохо, технологии содержат предвзятость (biased)».
Авторы из Google Research полностью подтвердили этот мем, поднявшись на высшую ступень абстракции вместо разбора рисков своего конкретного метода. В статье утверждается, что развитие ИИ ускорит глобальное влияние технологий как в хорошую, так и в плохую сторону, но авторы верят в итоговую пользу для человечества. Килчер подчеркивает, что подобный текст не сообщает ничего специфического о природе обучаемых оптимизаторов. Тем не менее, он выражает авторам глубокую признательность за публикацию отрицательных результатов и открытую демонстрацию всех слабых мест алгоритма, отмечая, что именно такая честность двигает вперед исследовательское сообщество.