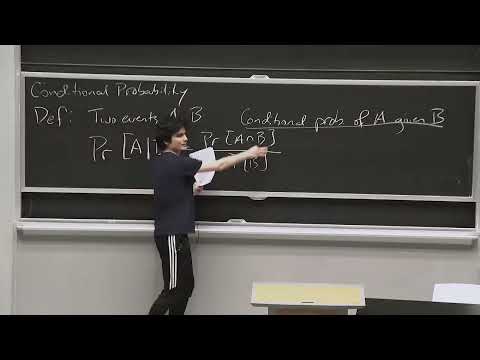
В лекции MIT OpenCourseWare преподаватель Бринмор Чепмен раскрывает фундаментальные принципы условной вероятности, переводя интуитивные догадки на строгий язык математики. На ярких примерах — от турниров по покемонам до медицинских тестов и громких судебных процессов — демонстрируется, как классические ошибки восприятия вероятностей могут приводить к ложным выводам. Автор показывает, почему в условиях неопределенности стоит опираться на математические формулы, а не на слепую интуицию.
📊 Базовые правила теории вероятностей и множеств 0:14
Перед тем как перейти к анализу сложных условных взаимосвязей, необходимо зафиксировать базовый математический аппарат. Вероятностная функция $Pr$ отображает пространство исходов (sample space) на интервал от 0 до 1. Вероятность любого случайного события — это просто сумма вероятностей всех исходов, входящих в это событие. Поскольку события технически представляют собой множества, к ним применимы стандартные правила теории множеств.
Из базового определения вероятности напрямую вытекает несколько следствий:
- Правило суммы (Sum rule): если два события $A$ и $B$ являются несовместными (disjoint), то вероятность их объединения равна сумме их индивидуальных вероятностей: $Pr(A \cup B) = Pr(A) + Pr(B)$.
- Правило дополнения (Complement rule): вероятность того, что событие $A$ не произойдет, рассчитывается как $1 - Pr(A)$. Это логично, поскольку $A$ и его отрицание несовместны, и одно из них обязательно случится с полной достоверностью.
- Правило разности (Difference rule): для вычисления вероятности разности множеств $A \setminus B$ необходимо из вероятности $A$ вычесть вероятность их пересечения: $Pr(A \setminus B) = Pr(A) - Pr(A \cap B)$.
- Принцип включений-исключений (Principle of inclusion/exclusion): для общего случая, когда события могут пересекаться, вероятность их объединения равна $Pr(A) + Pr(B) - Pr(A \cap B)$.
Существуют также два специфических правила, которые реже акцентируются в стандартном подсчете множеств, но критически важны для вероятностного анализа. Первое — это граница объединения (Union bound): вероятность $Pr(A \cup B)$ всегда меньше или равна $Pr(A) + Pr(B)$. Это неравенство (известное как неравенство Буля) справедливо, поскольку вероятность пересечения событий всегда неотрицательна. Если убрать вычитаемое пересечение из формулы включений-исключений, итоговое значение может только вырасти. Второе правило — монотонность (Monotonicity): если событие $A$ является подмножеством события $B$ ($A \subseteq B$), то его вероятность строго меньше или равна вероятности $B$. Все эти правила естественным образом обобщаются на произвольные (и даже счетные) системы событий.
🔍 Что такое условная вероятность? 9:44
В реальной жизни мы постоянно сталкиваемся с необходимостью оценить вероятность события при условии, что другое событие уже произошло. Ярким примером является знаменитая задача Монти Холла: если главный приз скрыт за дверью A, какова вероятность того, что ведущий или участник выберет дверь B?. Для формализации таких суждений вводится понятие условной вероятности.
Математически условная вероятность события $A$ при условии $B$ (обозначается как $Pr(A \mid B)$) определяется следующей формулой:
$$Pr(A \mid B) = \frac{Pr(A \cap B)}{Pr(B)}$$
Смысл формулы заключается в масштабировании исходного вероятностного пространства. Мы искусственно сужаем наш фокус: теперь событие $B$ становится новым универсальным пространством исходов, а все вероятности делятся на $Pr(B)$, чтобы их сумма снова давала единицу. Внутри этого нового пространства нас интересуют только те исходы события $A$, которые одновременно лежат и внутри $B$ — то есть их пересечение.
Если переписать это определение, мы получим правило произведения (Product rule):
$$Pr(A \cap B) = Pr(A \mid B) \cdot Pr(B)$$
Это правило масштабируется на цепочки из трех и более событий. Например, вероятность пересечения $A \cap B \cap C$ раскрывается последовательно:
$$Pr(A \cap B \cap C) = Pr(A \mid B \cap C) \cdot Pr(B \mid C) \cdot Pr(C)$$
Подобный пошаговый расчет лежит в основе построения древовидных диаграмм (вероятностных деревьев). Первый шаг от корня соответствует безусловной вероятности $Pr(C)$. Каждое последующее ветвление из вершины — это условная вероятность, зависящая от того, какой путь уже был пройден. Продвигаясь по ветвям к «листьям» дерева, мы фактически перемножаем последовательные условные вероятности.
Полезным расширением правила произведения является вычисление условной вероятности пересечения в уже ограниченном пространстве:
$$Pr(A \cap B \mid C) = Pr(A \mid B \cap C) \cdot Pr(B \mid C)$$
Это то же самое правило произведения, но примененное внутри вероятностного подпространства, где событие $C$ принимается за истину. Студентам важно помнить, что условная вероятность $A$ при условии $B$ — это не операция над множествами, а полноценное событие, существующее в измененном вероятностном поле.
🎮 Турнир покемонов: пошаговый расчет на дереве вероятностей 19:59
Чтобы закрепить теорию на практике, Бринмор Чепмен предлагает разобрать игровой сценарий: серию матчей между персонажами Эшем и Гарри. Они проводят турнир по покемонам, где победителем становится тот, кто первым выиграет две битвы. Вероятности исходов здесь неравномерны и зависят от психологического фактора:
- В самом первом матче шансы равны: Эш выигрывает с вероятностью 0,5 и проигрывает с вероятностью 0,5.
- В последующих играх тот, кто победил в предыдущем раунде, получает преимущество из-за высокого боевого духа и выигрывает следующий матч с вероятностью $\frac{2}{3}$. Ничьих в их противостоянии быть не может.
Введем два целевых события. Пусть событие $A$ означает, что Эш выигрывает весь турнир, а событие $B$ — что Эш выигрывает самую первую битву. Задача — найти условную вероятность $Pr(A \mid B)$.
Для решения строим дерево вероятностей. Первый уровень ветвления — первая игра Эша: победа ($W$) или поражение ($L$) с вероятностями по 0,5. Второй уровень — вторая игра. Если в первом матче была победа, то условная вероятность победить снова равна $\frac{2}{3}$, а проиграть — $\frac{1}{3}$. Если же в первом матче Эш уступил, шансы выиграть второй падают до $\frac{1}{3}$, а вероятность повторного проигрыша составляет $\frac{2}{3}$. Если игрок набирает две победы или два поражения подряд ($WW$ или $LL$), серия завершается, и ветка превращается в финальный лист. Если счет становится 1:1 ($WL$ или $LW$), назначается третий, решающий матч.
Для расчета финальных вероятностей каждого исхода мы перемножаем коэффициенты вдоль путей от корня до листьев:
- Исходи $WW$ (Эш побеждает в серии сразу): $0,5 \cdot \frac{2}{3} = \frac{1}{3}$.
- Исход $WLW$ (Эш выиграл, проиграл, затем выиграл): $0,5 \cdot \frac{1}{3} \cdot \frac{1}{3} = \frac{1}{18}$.
- Исход $WLL$ (Эш выиграл, затем дважды проиграл): $0,5 \cdot \frac{1}{3} \cdot \frac{2}{3} = \frac{1}{9}$.
- Исход $LWW$ (Эш проиграл, затем дважды выиграл): $0,5 \cdot \frac{1}{3} \cdot \frac{2}{3} = \frac{1}{18}$.
- Исход $LWL$ (Эш проиграл, выиграл, проиграл): $0,5 \cdot \frac{1}{3} \cdot \frac{1}{3} = \frac{1}{18}$.
- Исход $LL$ (Эш сразу проиграл турнир): $0,5 \cdot \frac{2}{3} = \frac{1}{3}$.
Теперь определим множества исходов для интересующих нас событий. Событие $B$ (победа в первом матче) включает исходы ${WW, WLW, WLL}$, суммарная вероятность которых равна 0,5. Пересечение событий $A \cap B$ (Эш выиграл и первый матч, и весь турнир) состоит из исходов ${WW, WLW}$. Применив правило суммы, получаем: $Pr(A \cap B) = \frac{1}{3} + \frac{1}{18} = \frac{7}{18}$.
Финальный шаг — деление по формуле условной вероятности: $Pr(A \mid B) = \frac{7}{18} / 0,5 = \frac{7}{9}$. Таким образом, победа в дебютной игре поднимает шансы на триумф в турнире до $\frac{7}{9}$.
Интересно, что если мы посчитаем обратную условную вероятность $Pr(B \mid A)$ (какова вероятность, что Эш выиграл первый матч, при условии, что мы уже знаем о его победе в турнире?), результат тоже окажется равным $\frac{7}{9}$. Математически это объясняется симметрией исходных данных, из-за которой безусловные вероятности $Pr(A)$ и $Pr(B)$ совпали. Однако содержательно этот пример иллюстрирует важный концепт: условная вероятность не зависит от времени или причинно-следственных связей. Это сугубо численный инструмент вывода (inference). Даже если событие $B$ хронологически произошло раньше $A$, мы можем рассчитывать вероятность прошлого на основе информации о будущем, обновляя степень нашей уверенности в условиях неопределенности.
⚖️ Теорема Байеса и язык статистики 35:50
Связь между прямой и обратной условной вероятностью формализуется с помощью знаменитой теоремы Байеса, которую можно назвать замаскированным правилом произведения:
$$Pr(B \mid A) = \frac{Pr(A \mid B) \cdot Pr(B)}{Pr(A)}$$
Если перенести знаменатель $Pr(A)$ в левую часть, равенство превратится в обычный расчет пересечения множеств $A \cap B$ с двух разных сторон. В статистике и анализе данных для элементов этой формулы принята строгая терминология, описывающая процесс обучения на основе наблюдений:
- $Pr(B)$ — априорная вероятность (prior probability): наше исходное убеждение в истинности гипотезы $B$ до того, как стали известны какие-либо новые данные.
- $Pr(A \mid B)$ — правдоподобие (likelihood): вероятность получить наблюдение $A$ при условии, что наша гипотеза $B$ верна.
- $Pr(B \mid A)$ — апостериорная вероятность (posterior probability): обновленная оценка истинности гипотезы $B$ после того, как мы зафиксировали факт наступления события $A$.
Иногда вычисление безусловного знаменателя $Pr(A)$ представляет собой крайне сложную математическую задачу. В таких ситуациях удобнее использовать теорему Байеса в форме отношений (odds form), сравнивая апостериорные вероятности гипотезы и её отрицания:
$$\frac{Pr(B \mid A)}{Pr(\overline{B} \mid A)} = \frac{Pr(A \mid B) \cdot Pr(B)}{Pr(A \mid \overline{B}) \cdot Pr(\overline{B})}$$
В этой формуле знаменатель исходной теоремы Байеса взаимоуничтожается, что позволяет полностью обойти необходимость вычисления сложного безусловного события.
🪙 Парадокс двух монет и ловушка тестирования на COVID 42:22
Для демонстрации работы теоремы Байеса Чепмен приводит два классических примера, результаты которых часто кажутся контринтуитивными.
Кейс с монетами
В кармане лежат две монеты: одна честная (дает орел/решка в соотношении 50/50), а вторая — фальшивая, у которой с двух сторон отчеканен орел. Мы вслепую выбираем одну из монет с равной вероятностью, подбрасываем ее и видим орла ($H$). Какова вероятность $Pr(F \mid H)$, что в руках оказалась именно честная монета ($F$)?.
Применим формулу отношений Байеса, разделив вероятность вытащить честную монету на вероятность вытащить фальшивку:
$$\frac{Pr(F \mid H)}{Pr(\overline{F} \mid H)} = \frac{Pr(H \mid F) \cdot Pr(F)}{Pr(H \mid \overline{F}) \cdot Pr(\overline{F})}$$
Нам известны все составляющие: правдоподобие орла на честной монете $Pr(H \mid F) = 0,5$; на фальшивой — $Pr(H \mid \overline{F}) = 1$. Априорные шансы выбрать любую из монет одинаковы: $Pr(F) = Pr(\overline{F}) = 0,5$. Подставляя значения, получаем, что отношение вероятностей равно 0,5. Поскольку сумма апостериорных вероятностей должна быть равна 1, единственные числа, дающие в отношении 0,5 — это $\frac{1}{3}$ и $\frac{2}{3}$. Ответ: вероятность того, что монета честная, составляет всего $\frac{1}{3}$.
Кейс с медицинскими тестами
Второй пример касается массового ПЦР-тестирования в кампусе MIT во время пандемии. Предположим, что реальный уровень заболеваемости COVID-19 в университете составляет 10%. Используемый тест имеет следующие характеристики:
- Доля ложноположительных результатов (false-positive rate) — 30%. Это означает, что у 30% здоровых людей тест ошибочно диагностирует вирус.
- Доля ложноотрицательных результатов (false-negative rate) — 10%. То есть у 10% реально больных тест не заметит инфекцию.
Допустим, студент сдает тест, и результат оказывается положительным ($+$). Какова вероятность, что он действительно болен ($S$)?. Большинство людей, ориентируясь на относительно невысокие маркеры ошибок, предполагают, что вероятность болезни очень высока. Проверим это с помощью формулы отношений:
$$\frac{Pr(S \mid +)}{Pr(H \mid +)} = \frac{Pr(+\mid S) \cdot Pr(S)}{Pr(+\mid H) \cdot Pr(H)}$$
Здесь вероятность истинно положительного теста у больного равна $Pr(+\mid S) = 1 - 0,1 = 0,9$ (90%). Априорная вероятность болезни $Pr(S) = 0,1$. Вероятность ложноположительного теста у здорового $Pr(+\mid H) = 0,3$. Априорная вероятность быть здоровым $Pr(H) = 0,9$. Подставив эти коэффициенты, мы увидим, что значения 0,9 в числителе и знаменателе сокращаются, оставляя отношение $\frac{0,1}{0,3} = \frac{1}{3}$.
Если отношение шансов заболеть к шансам остаться здоровым равно 1 к 3, то реальная апостериорная вероятность болезни составляет всего $\frac{1}{4}$, то есть 25%. Положительный тест с большей вероятностью говорит о том, что человек здоров. Ошибка обывательского восприятия кроется в игнорировании априорной вероятности (prior). Поскольку изначально подавляющее большинство людей в популяции здоровы (90%), огромный массив ложноположительных результатов от этой группы численно перевешивает правильные ответы, полученные от малой группы больных. В реальной медицинской практике этот парадокс нивелируется тем, что тесты редко назначают случайным людям; обычно обследуют пациентов с явными симптомами, что изначально резко сдвигает априорную вероятность $Pr(S)$ вверх.
🏛️ Парадокс Симпсона: почему статистика Беркли казалась сексистской 1:01:35
Одним из самых удивительных феноменов в агрегации данных является парадокс Симпсона — ситуация, при которой направленность вывода кардинально меняется при переходе от изолированных групп данных к объединенным массивам.
Бринмор Чепмен иллюстрирует этот парадокс реальным историческим прецедентом: около 50 лет назад против Калифорнийского университета в Беркли был подан судебный иск. Причиной послужили подозрения в дискриминации по половому признаку при приеме в магистратуру: общая статистика показывала, что процент одобренных заявок среди мужчин был значительно выше, чем среди женщин. Однако когда руководство вуза провело аудит по конкретным кафедрам, выяснилась парадоксальная деталь: внутри практически каждого отдельного департамента процент зачисления женщин был выше, чем у мужчин.
Для понимания математической природы этого феномена рассмотрим утрированную модель университета из двух вымышленных факультетов: электротехники ($EE$) и компьютерных наук ($CS$). Допустим, в университет поступают 100 мужчин и 100 женщин. Интересы абитуриентов распределились неравномерно:
- На факультет CS подали заявки 99 женщин и всего 1 мужчина.
- На факультет EE подали заявки 99 мужчин и всего 1 женщина.
Факультет CS имеет крайне жесткие квоты и строгий отбор — они одобряют лишь 1 заявку из всех. Эту единственную позицию получает женщина, а единственный мужчина получает отказ. Итоговые показатели зачисления на CS: женщины — $\frac{1}{99}$ (около 1%), мужчины — 0%. Факультет демонстрирует явное статистическое преимущество в пользу женщин.
Факультет EE, напротив, готов зачислять практически всех подряд. Они одобряют документы единственной пришедшей женщины и берут 98 из 99 мужчин. Итоговые показатели зачисления на EE: женщины — 100%, мужчины — $\frac{98}{99}$ (около 99%). Снова на локальном уровне статистика благоволит женщинам.
Однако если мы объединим данные и посчитаем общие итоги по университету, мы увидим следующую картину:
| Пол | Подали заявки | Зачислены | Общий процент приема |
|---|---|---|---|
| Мужчины | 100 | 98 | 98% |
| Женщины | 100 | 2 | 2% |
На глобальном уровне мужчины продемонстрировали колоссальный перевес (98% против 2%). Парадокс Симпсона возникает из-за скрытых условных факторов (в данном случае — из-за разницы в объемах выборок и базовой строгости отбора на разных факультетах). Женщины в массе своей подавали документы на факультет с жестким конкурсом, где отсеивались почти все, а мужчины штурмовали факультет, куда принимали практически каждого. Таким образом, общая негативная статистика Беркли свидетельствовала не о предвзятости приемных комиссий на местах, а о системных различиях в распределении образовательных предпочтений среди мужчин и женщин.
🍰 Дело о похищенном пироге: условная вероятность в суде 1:06:42
В финальной части лекции преподаватель показывает, как манипуляции с условной вероятностью могут использоваться в юридической практике, ломая человеческие судьбы из-за банальной математической неграмотности сторон. Для наглядности Чепмен выстраивает игровой пример на основе вселенной мультсериала «Принц-дракон» (The Dragon Prince).
Из королевской пекарни исчезает пирог. У пекаря Бариуса есть главный подозреваемый — принц Эзран. Чтобы убедить короля в виновности мальчика, пекарь хочет приобщить к делу неоспоримый факт: этот ребенок регулярно ворует из пекарни желейные тарты. Логика обвинения звучит весомо: статистика показывает, что люди, склонные к воровству желейных тартов ($J$), в 10 раз чаще совершают кражи крупных пирогов ($C$), чем обычные граждане. Казалось бы, улика имеет колоссальное доказательное значение.
Однако сторона защиты принца выдвигает сильный математический контраргумент. Если мы изучим абсолютно всех воришек желейных тартов в королевстве, то увидим, что лишь 1 из 2500 таких мелких воров в итоге идет на кражу большого пирога. Даже с учетом десятикратного роста рисков относительно базового уровня (который составлял 1 на 25 000), абсолютная вероятность того, что конкретный любитель тартов украл пирог, ничтожно мала: всего 0,04%. В уголовном праве действует стандарт доказывания «вне разумных сомнений», и вероятность вины в 0,04% категорически не может служить основанием для обвинительного приговора. Напротив, демонстрация факта прошлых краж лишь необоснованно настроит короля против подсудимого.
Обе стороны в данном споре оперируют одной и той же условной вероятностью $Pr(C \mid J)$, но интерпретируют ее по-разному:
- Пекарь (обвинение) доказывает, что отношение $\frac{Pr(C \mid J)}{Pr(C \mid \overline{J})} \approx 10$ (высокая релевантность улики).
- Защита доказывает, что абсолютное значение $Pr(C \mid J) = \frac{1}{2500}$ (ничтожно малая вероятность вины).
В чем же заключается главная ошибка этих рассуждений и кто прав? С точки зрения математики, неправы обе стороны, поскольку они в корне неверно выбрали событие для кондиционирования. Они полностью проигнорировали ключевое обстоятельство: пирог уже украден, это свершившийся факт. Нас совершенно не интересует абстрактная вероятность кражи пирога в вакууме. Реальное условное событие, которое должен рассматривать суд, обязано включать маркер факта преступления ($X$):
$$Pr(C \mid J \cap X)$$
Если мы пересчитаем вероятность с учетом того, что пирог действительно пропал, а подсудимый — мелкий воришка, пойманный в этой же локации, то условная вероятность его вины взлетает примерно до 80%. Потребители мелких тартов, находящиеся в пекарне в момент пропажи крупных пирогов, с огромной вероятностью оказываются реальными виновниками.
Этот сказочный пример описывает реальную катастрофу, произошедшую во время знаменитого судебного процесса над О. Джеем Симпсоном в США. Тогда адвокаты защиты заявляли, что до допущения убийства доходит лишь ничтожная доля случаев домашнего насилия, а обвинение упирало на кратную разницу в статистике, искажая реальное положение дел. Обе стороны, будучи высокооплачиваемыми экспертами, оперировали некорректными условными вероятностями.
Резюмируя лекцию, Бринмор Чепмен призывает студентов никогда не полагаться на поверхностные логические конструкции в юридических, медицинских или житейских вопросах. При возникновении любых сомнений необходимо отбрасывать эмоции, возвращаться к фундаментальным математическим основам, чертить дерево исходов и строго считать условные вероятности по формулам.