MLP-Mixer: Архитектурная простота в эпоху гигантов 0:01
В мире компьютерного зрения, где доминируют сложные механизмы внимания и тяжеловесные сверточные нейронные сети (CNN), исследователи из Google Research представили альтернативный подход — MLP-Mixer. Как отмечает Янник Кильхер, это архитектура, полностью построенная на многослойных перцептронах (MLP), которая отказывается от привычных сверток и механизмов внимания (attention), полагаясь исключительно на матричные умножения, нелинейности и нормализацию. По словам Кильхера, работа является отличным уроком того, как «старые» идеи могут обрести вторую жизнь при правильном масштабировании.
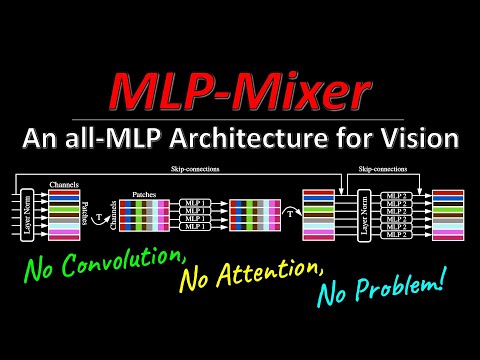
🏗 Как устроена «смешивающая» архитектура 2:26
В основе MLP-Mixer лежит принцип обработки данных, схожий с Vision Transformer: изображение разбивается на фиксированные патчи (например, 16x16 пикселей), которые затем преобразуются в векторы латентных представлений. Однако «магия» происходит внутри слоев миксера (mixer layers):
- Token Mixing: Этот этап отвечает за взаимодействие между различными патчами. Таблица представлений транспонируется, и полносвязный слой применяется ко всем патчам внутри одного канала, что позволяет модели «видеть» общие признаки по всему изображению.
- Channel Mixing: На этом этапе вычисления производятся внутри одного патча, объединяя информацию из всех каналов.
Кильхер подчеркивает, что эта двухэтапная процедура повторяется несколько раз, позволяя модели эффективно агрегировать информацию как пространственно (по патчам), так и семантически (по каналам). Важной особенностью здесь является разделение весов: операции эффективно используют общие весовые матрицы, что делает архитектуру вычислительно легкой.
📈 Масштабируемость и производительность 13:29
Главное преимущество MLP-Mixer перед Vision Transformer заключается в линейной зависимости сложности от количества патчей, тогда как механизм внимания требует квадратичных затрат вычислительных ресурсов.
Основные выводы из экспериментов, представленных в статье:
- Конкурентоспособность: Хотя MLP-Mixer не всегда бьет рекорды State-of-the-Art по точности классификации на ImageNet, он показывает «адекватные» результаты и выигрывает в эффективности.
- Пропускная способность: Модель обладает значительно более высокой скоростью обработки изображений в секунду на ядро, что критически важно для практического развертывания.
- Масштабируемость данных: По мнению Кильхера, модель демонстрирует удивительную способность «выигрывать» при увеличении объема обучающих данных, успешно закрывая разрыв в точности с более сложными архитектурами при работе с большими датасетами.
🧐 Философский вопрос: в чем секрет успеха? 21:53
Видео поднимает глубокий вопрос: является ли успех таких архитектур следствием их дизайна или просто триумфом масштабирования (Scale)?
- Кильхер размышляет, что если мы продолжим увеличивать объемы данных и вычислительных мощностей, возможно, даже «неоптимальная» архитектура начнет работать превосходно.
- Автор видео иронично замечает, что если довести масштабирование до предела, то даже примитивный метод k-ближайших соседей (k-NN) теоретически мог бы достичь 100% точности, так как мы будем иметь доступ ко «всей вероятности всех изображений».
- Индуктивные смещения (inductive biases) в MLP-Mixer, по мнению ведущего, могут оказаться «суперкорректными» для задачи классификации естественных изображений, что объясняет, почему столь простая конструкция работает наравне со сложными нейросетями.




