Заключительная лекция курса CS149 в Стэнфордском университете, прочитанная профессором Кейвоном Фатахалианом, подводит итог изучению параллельных вычислений и раскрывает внутреннее устройство современной оперативной памяти. Преподаватель подробно разбирает физические ограничения пропускной способности кремниевых чипов, объясняет устройство сверхбыстрой архитектуры HBM и делится со студентами практическими советами по выстраиванию карьеры и научной работы в ИТ-индустрии.
🧠 Анатомия DRAM: от аналогового заряда к цифровому биту 0:44
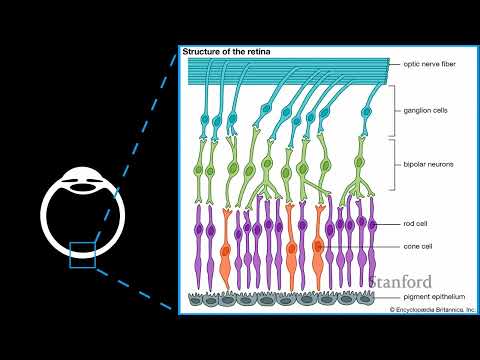
В традиционном представлении компьютер состоит из процессора, кэш-памяти и оперативной памяти (DRAM). Кэш необходим для сокращения времени доступа и увеличения пропускной способности, а за координацию всех запросов отвечает выделенный аппаратный блок — контроллер памяти (memory controller). Если физически разобрать современный ноутбук, внутри обнаружатся микросхемы DRAM, каждую из которых можно представить как гигантский двумерный массив ячеек памяти.
Каждый бит информации в DRAM кодируется величиной электрического заряда, хранящегося в микроскопическом конденсаторе аналоговой ячейки. Этот процесс напоминает работу фотоматрицы в цифровой камере, но в обратном порядке: вместо преобразования уловленных фотонов в напряжение здесь разные уровни напряжения кодируют логические «0» и «1». На физическом уровне чип DRAM имеет крайне ограниченное число внешних контактов данных — стандартно всего 8 пинов, что позволяет передавать лишь 8 бит информации за один такт. Чтобы компенсировать узкое физическое горлышко, внизу чипа расположен цифровой буфер строки (row buffer), временно хранящий значения всей активной строки массива.
⏱️ Пошаговый алгоритм чтения: почему задержка памяти не постоянна 4:50
Когда процессор сталкивается с промахом кэша (cache miss), контроллер памяти транслирует запрос на получение конкретной строки кэша (обычно размером 64 байта) по физическому адресу X. Извлечение нужного байта из аналоговых ячеек состоит из трех последовательных шагов:
- Предзаряд (Precharge) — подготовка линий битов и выравнивание напряжения на внутренних проводах чипа, что занимает около 10 наносекунд.
- Активация строки (Row Activate) — считывание заряда из массива ячеек и перенос всей строки в буфер строки, занимающее еще 10 наносекунд. Из-за аналоговой природы эта операция полностью разрушает данные в исходных конденсаторах, оставляя их копию только в буфере.
- Выбор столбца (Column Selection) — перенос целевых бит из открытого буфера строки на внешнюю шину памяти и их отправка обратно в процессор.
Если программе требуется прочитать несколько смежных байтов из одной строки, повторная активация массива не требуется: данные считываются напрямую из цифрового буфера строки, что происходит значительно быстрее. Из-за этого задержка DRAM кардинально меняется в зависимости от паттерна доступа: хаотичное чтение разбросанных данных заставляет тратить лишние 20–30 наносекунд на каждую операцию, снижая реальную пропускную способность подсистемы в 3–4 раза. Если контроллеру нужно переключиться на другую строку, измененные данные из буфера сначала должны быть принудительно записаны обратно в ячейки массива.
🔀 Распараллеливание на уровне железа: банки памяти и модули DIMM 15:57
Для скрытия задержек и повышения утилизации шины данных инженеры применяют конвейеризацию памяти. Массив ячеек DRAM дублируется на несколько независимых блоков — банков (banks), которые делят между собой общие пины данных. Пока один банк занят предзарядом или активацией строки, контроллер может параллельно считывать или передавать данные из других банков, заполняя паузы на шине.
Для расширения шины данных отдельные чипы объединяются в модули памяти DIMM (In-line Memory Module). Стандартный модуль содержит 8 чипов с 8-битной шиной каждый, образуя в совокупности привычную 64-битную системную шину памяти. Контроллер памяти транслирует линейные физические адреса процессора в трехмерные координаты: банк, строка и столбец. Чтобы эффективно прочитать 64-байтовую строку кэша, адреса чередуются по чипам так, чтобы за один такт считывать 8 последовательных байт сразу со всех кремниевых кристаллов модуля.
🕹️ Мозг подсистемы памяти: очереди запросов и двухканальный режим 25:56
Современные контроллеры памяти динамически переупорядочивают поступающие от ядер процессора запросы, чтобы максимизировать локальность буфера строк и конвейеризацию банков. Процессор может выполнять абсолютно разные приложения на разных ядрах, хаотично смешивая их потоки обращений к памяти и создавая конфликтные ситуации на чипе DRAM. По словам Кейвона Фатахалиана, агрессивное буферизование выгодно для задач, ограниченных пропускной способностью (bandwidth-bound), но может вредить системам, чувствительным к чистой задержке (latency-sensitive). Например, контроллеры в графических процессорах NVIDIA способны удерживать в буфере десятки тысяч запросов одновременно из-за жесткой ориентации GPU на пропускную способность.
Для дальнейшего масштабирования применяется многоканальная архитектура. Двухканальная система DDR4 с частотой шины 1,2 ГГц благодаря технологии Double Data Rate выполняет 2400 млн транзакций в секунду. На 64-битной шине один канал обеспечивает пиковую скорость 19,2 ГБ/с, а два независимых канала удваивают этот показатель до 38,4 ГБ/с. Серверная память также включает механизмы отказоустойчивости: модули с ECC (Error Correcting Codes) оснащаются дополнительным девятым чипом для хранения избыточных данных и автоматического исправления ошибок при случайном изменении состояния битов.
🏗️ Эра HBM: кремниевые интерпозеры и трехмерное стеккование чипов 35:16
Физическое расстояние между процессором и модулями DRAM на материнской плате жестко ограничивает количество доступных контактов из-за их дороговизны и сложности разводки плат. Решением этой проблемы стало появление высокопроизводительной многослойной памяти HBM (High Bandwidth Memory), где кристаллы оперативной памяти располагаются непосредственно на одной подложке (кремниевом интерпозере) вместе с центральным или графическим процессором.
Чипы DRAM в архитектуре HBM устанавливаются вертикально друг на друга с использованием сквозных межкремниевых отверстий — TSV (Through-Silicon-Via). Это позволяет пустить тысячи соединительных проводников по всей площади кристалла, а не только по его краям, расширяя шину данных с 64 бит до 1024 бит на стек. Процессор с четырьмя стеками HBM получает колоссальную 4096-битную шину, выдававшую еще в 2016 году скорость 720 ГБ/с, а в современных ускорителях этот показатель превышает два терабайта в секунду.
Профессор отмечает, что знаменитый алгоритм Flash Attention был спроектирован именно для удержания промежуточных матриц в рамках быстрых 16 ГБ HBM, избегая медленных обращений к внешней памяти DDR. В условиях жесткого дефицита пропускной способности выгодно использовать аппаратное или программное сжатие данных: графические чипы сознательно тратят свободные вычислительные инструкции на декомпрессию текстур на лету, чтобы уменьшить объем физически передаваемой информации по шине.
📉 Проблема неэффективности софта и конец эпохи простого масштабирования 41:43
В обозримом будущем рост производительности вычислительных платформ будет обеспечиваться преимущественно за счет параллелизма и узкой аппаратной специализации. Современные чипы в смартфонах (Apple Silicon) уже представляют собой гетерогенные многоядерные платформы со специализированными ядрами CPU, мощными GPU, нейропроцессорами для ИИ и контроллерами энергосбережения.
При этом Кейвон Фатахалиан указывает на катастрофическую неэффективность большинства современного программного обеспечения. Стандартная, написанная без учета архитектуры железа программа на Си может работать в 40 раз медленнее версии, задействующей векторные инструкции SIMD, а специализированные ускорители дают преимущество еще в 10–100 раз. Профессор считает, что вместо автоматического развертывания огромных и дорогих облачных кластеров разработчикам часто достаточно приложить усилия к локальной оптимизации кода, чтобы ускорить его в 1000 раз. В современных реалиях, когда большие языковые модели ИИ жестко упираются в нехватку мощностей, базовое понимание аппаратных абстракций позволяет инженерам трезво оценивать реальное время выполнения алгоритмов и пресекать написание неоптимального софта.
🔬 Как устроена научная работа в Стэнфорде: проект движка Madrona 45:42
В качестве примера реальной исследовательской деятельности Фатахалиан рассказывает о проекте своей лаборатории — создании легковесного игрового движка Madrona, оптимизированного под массовое распараллеливание на GPU. В современных задачах обучения ИИ-агентов методом проб и ошибок исследователям приходится запускать десятки тысяч копий симуляций в Unity или Unreal Engine, что приводит к критическому перерасходу серверных ресурсов и перегрузке памяти из-за рассинхронизации потоков.
Студент лаборатории Фатахалиана спроектировал мини-движок, который запускает десятки тысяч изолированных игровых миров в жестком параллельном режиме (lock-step) на одном графическом процессоре. Система способна одновременно просчитывать физику, логику игровых событий и высокоскоростную трассировку лучей для определения видимости агентов. В результате удалось добиться ускорения на 2–3 порядка: тренировка ИИ-агентов, требовавшая работы кластера из 64 GPU в течение недели, теперь завершается за пару часов на одной видеокарте.
Другой студент магистратуры, вдохновившись результатами курса, успешно реализовал на базе этого движка собственный аналог Minecraft, работающий со скоростью 600 000 кадров в секунду. Профессор подчеркивает, что независимые студенческие проекты за рамками стандартного учебного плана приносят гораздо больше пользы для реального развития, чем механическое выполнение домашних заданий.
🧭 Карьерные траектории: почему рекомендации профессоров важнее оценок 56:08
Традиционный путь успешного студента — получение идеального GPA 4.0, посещение официальных ярмарок вакансий и сбор стандартных предложений от техногигантов уровня Google или Meta — по мнению профессора, перестал работать эффективно из-за тотального перенасыщения ИТ-рынка. Гораздо более сильным каналом построения карьеры Фатахалиан считает интеграцию студентов в исследовательские группы университета. Преподаватели Стэнфордского университета обладают прямыми контактами с ведущими архитекторами индустрии и могут напрямую рекомендовать сильных кандидатов на ключевые позиции, минуя стандартные HR-фильтры.
Кейвон Фатахалиан делится историей своего выпускника, который очень хотел попасть в передовую исследовательскую команду, но из-за отсутствия научных публикаций не имел шансов пройти жесткий отбор на общих основаниях. Профессор предложил ему в качестве открытого курсового проекта воссоздать сложнейший алгоритм обработки изображений из свежей научной статьи Google. Успешная реализация проекта послужила железным аргументом: Фатахалиан лично связался со своими знакомыми в руководстве подразделения Google, что позволило выпускнику получить оффер наравне с обладателями степени PhD. Впоследствии этот специалист опубликовал несколько статей, успешно закончил аспирантуру Беркли всего за 4 года и перешел на работу в Anthropic.
В заключение лектор призывает студентов активно общаться на офисных часах, проявлять инициативу за рамками обязательных заданий и не бояться писать преподавателям повторно, если их письма случайно затерялись в плотном потоке входящей почты.