В рамках курса Стэнфордского университета EE274 по сжатию данных лектор Пулкит (Pulkit) подробно разбирает ключевой, но часто игнорируемый в классической теории информации фактор — человеческое восприятие. На примере устройства зрительной системы человека, классических иллюзий и современных нейросетевых алгоритмов объясняется, почему привычная метрика среднеквадратичного отклонения (MSE) не отражает реальное качество контента. В материале рассматривается эволюция подходов к компрессии: от традиционного алгоритма JPEG до революционной концепции трехстороннего компромисса между скоростью передачи, искажением и восприятием (RDP).
🎧 Анатомия аудиокомпрессии: почему в MP3 именно два канала и 44,1 кГц? 2:52
Разработку любого мультимедийного компрессора невозможно отделить от биологических особенностей его конечного потребителя — человека. Простейшие примеры такого антропоцентрического дизайна скрыты в метаданных обычных аудиофайлов, которые мы запускаем ежедневно.
Если открыть утилиту MediaInfo и проанализировать стандартный сжатый файл MP3 (например, культовую тему из мультсериала Pokémon), можно обнаружить строго фиксированные параметры: два аудиоканала и частоту дискретизации 44,1 килогерца. Эти цифры не случайны.
Наличие двух каналов обусловлено банальной анатомией: у людей два уха. Если бы эволюция наделила человека тремя ушами, инженеры сжимали бы звук в трехканальном формате для создания адекватной стереопанорамы. Бездумное увеличение количества каналов привело бы к удвоению объема несжатых данных без какой-либо практической пользы для слушателя.
Выбор частоты 44,1 кГц уходит корнями в элементарную биологию и классическую теорию сигналов. Среднестатистический человек способен воспринимать звуковые частоты в диапазоне от 20 герц до 20 килогерц. Согласно знаменитому критерию Найквиста (в русскоязычной традиции — теорема Котельникова), для точной реконструкции аналогового сигнала без наложения спектров (алиасинга) частота дискретизации должна как минимум вдвое превышать верхнюю границу спектра. Отсюда рождается базовое требование в 40 килогерц.
Дополнительные 4,1 килогерца выступают в качестве технического буфера. В реальном мире невозможно создать идеальный аналоговый фильтр нижних частот с бесконечно крутым срезом, поэтому инженерам необходим технологический зазор.
Более того, число 44100 обладает красивыми математическими свойствами. Оно легко раскладывается на простые множители (2, 3, 5), что существенно упрощает последующее понижение частоты дискретизации (даунсемплинг) цифрового звука в вычислительных чипах. Каждое из этих неочевидных решений напрямую определяет финальный размер файлов, которые хранятся на наших устройствах.
👁️ Как устроена человеческая «камера»: особенности анатомии глаза 7:41
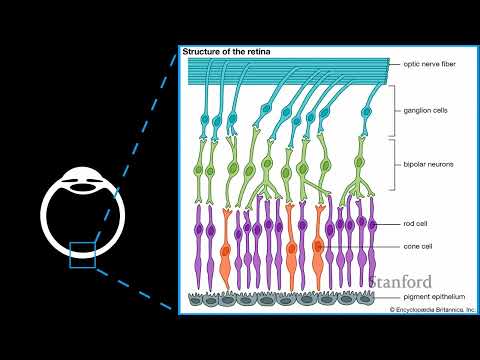
Переходя от звука к изображениям, необходимо детально разобрать оптическое устройство человеческого глаза. Световой сигнал проходит через роговицу и зрачок, фокусируясь хрусталиком на задней стенке глазного яблока — сетчатке. Именно здесь происходит трансдукция — физический процесс преобразования световых волн в электрические импульсы, которые затем передаются по зрительному нерву в головной мозг.
Физика и оптика глаза накладывают первые ограничения на восприятие информации. Если направить на сетчатку идеальный точечный источник света высокой интенсивности (математическую дельта-функцию, окруженную абсолютно черными пикселями), на самой сетчатке мы не увидим четкой точки. Из-за несовершенства линзовой системы глаза световое пятно неизбежно размывается.
Биологически человеческий глаз выполняет функцию низкочастотного фильтра. Если расположить множество контрастных линий слишком близко друг к другу, оптическая система глаза просто сольет их в единый серый фон.
С практической точки зрения это открывает колоссальные возможности для компрессии. Инженерам нет никакого смысла тратить драгоценные биты на сохранение сверхвысоких пространственных частот, поскольку человеческое зрение физически не способно их зафиксировать. Природа изначально создавала механизмы восприятия под сигналы с низкой мощностью в высокочастотном спектре.
🌓 Палочки, колбочки и феноменальный динамический диапазон 12:43
Строение сетчатки в разрезе демонстрирует фундаментальное различие между биологическим зрением и цифровой матрицей фотоаппарата. Видеокамера воспринимает изображение как жесткий плоский массив пикселей, где в каждой точке зафиксирована комбинация значений RGB. В глазу человека обработка структурирована иначе.
Сетчатка покрыта слоем фоторецепторов двух типов — палочками (rods) и колбочками (cones). Палочки отвечают исключительно за кодирование интенсивности света и монохромную картинку, они полностью игнорируют цвет. В глазу человека насчитывается около 100 миллионов палочек.
Главное преимущество палочек — их фантастическая способность к адаптации. Они способны обрабатывать колоссальный динамический диапазон освещенности, охватывающий девять порядков величины ($10^9$).
Каждый сталкивался с этим эффектом: выходя из-под палящего калифорнийского солнца в темную лекционную аудиторию, человек сначала слепнет, но уже через несколько секунд зрение полностью адаптируется к полумраку. Палочки мгновенно перестраивают базовый уровень чувствительности, фиксируя малейшие флуктуации фотонов в темноте. Современные цифровые камеры до сих пор с трудом справляются с подобными перепадами освещения.
Анатомическая структура глаза имеет еще одну странную особенность — слепое пятно. В месте, где зрительный нерв подключается к сетчатке, полностью отсутствуют фоторецепторы.
Существует классический домашний эксперимент: если вытянуть перед собой руку, зафиксировать взгляд на большом пальце и медленно отводить его в сторону, продолжая смотреть строго вперед, в определенной точке палец буквально исчезнет из поля зрения. Наш мозг незаметно для нас маскирует эту слепую зону, дорисовывая текстуру окружения.
🎯 Саккады и фовеация: иллюзия идеальной картинки 16:17
Плотность распределения рецепторов по сетчатке крайне неравномерна. Палочки рассредоточены практически по всей площади глаза, за исключением слепого пятна. С колбочками, отвечающими за цвет, высокую четкость и детализацию, ситуация прямо противоположная.
Колбочки практически полностью отсутствуют на периферии сетчатки. Они жестко сгруппированы в крошечной центральной области зрительной зоны под углом около нуля градусов. Эта микроскопическая зона высокого разрешения называется центральной ямкой, или фовеа (fovea).
Фактически, человек видит мир в идеальном качестве и цвете только через узкую «замочную скважину» в центре своего взгляда. Вся остальная часть панорамы вокруг — это размытое монохромное изображение низкого разрешения. Возникает закономерный вопрос: почему же мы воспринимаем окружающий мир как цельную, плавную и четкую картину?
Дело в том, что человеческий глаз никогда не находится в состоянии покоя. Мы не смотрим на мир статично, как на фотографию. Наше зрение — это непрерывный видеопоток, а глазное яблоко постоянно совершает микроскопические высокоскоростные движения — саккады (saccadic movements).
За доли миллисекунд глаз постоянно сканирует пространство, перемещая фовеа из одной точки физической сцены в другую. Если сознательно зафиксировать взгляд на настенных часах, лица людей и предметы по бокам начнут стремительно терять четкость и практически исчезнут.
Но в обычном состоянии мозг непрерывно интерполирует данные, полученные в ходе быстрых саккадических сканирований. На основе этих обрывков он собирает в сознании иллюзию стабильного, полностью детализированного кадра.
Этот феномен, называемый фовеацией, открывает огромные перспективы для инженерии. Зная, куда именно устремлен взгляд пользователя в конкретную секунду, можно кардинально перераспределить битрейт.
Подобный подход активно исследуется в технологиях виртуальной реальности (VR). Интегрированные в VR-гарнитуру датчики трекинга глаз позволяют отдавать максимальный приоритет сжатия (высокий битрейт) той зоне 3D-сцены, куда смотрит человек, снижая разрешение периферийных областей практически до нуля. Это экономит огромные вычислительные ресурсы.
🎨 Закон Вебера и две теории цветового зрения 21:44
Еще один фундаментальный биологический принцип — закон Вебера. Согласно ему, человеческое восприятие реагирует не на абсолютное изменение физического стимула, а на его относительный прирост.
В контексте яркости это означает, что изменение цвета пикселя на 1 бит в темной области (низкая интенсивность) будет критически заметно для глаза. В то же время точно такое же изменение на 1 бит в области высокой яркости (белый снег в солнечный день) останется абсолютно неощутимым. Неравномерное распределение битрейта с учетом закона Вебера критически важно при кодировании контента для современных HDR и 4K-телевизоров.
Исторически ученые долго пытались понять, как именно человек различает цвета. В итоге сформировались две дополняющие друг друга теории.
Первая — трихроматическая теория цветового зрения. График отклика колбочек показывает, что рецепторы делятся на три типа в зависимости от длины воспринимаемой световой волны: LMS (Long, Medium, Short — длинные, средние и короткие волны). Они грубо соответствуют красному, зеленому и синему цветам.
Именно поэтому в цифровой индустрии закрепился стандарт RGB. Мы используем три цветовых компонента не потому, что физика света так устроена, а потому, что наш биологический сенсор имеет ровно три разновидности приемников. В полиграфии, напротив, прижилась субтрактивная модель CMYK, работающая по принципу вычитания волн при смешивании чернил.
В 1931 году Международная комиссия по освещению (CIE) зафиксировала физические границы человеческого зрения на специальной хроматической диаграмме. Внутри этой подковообразной зоны видимого спектра коммерческие компании создают свои стандарты — например, узкий sRGB или более широкий Adobe RGB.
[Хроматическая диаграмма CIE 1931 с треугольниками цветовых охватов sRGB и Adobe RGB]
Для инженеров сжатия это вечная головная боль. Цифровые данные пикселей в конечном счете преобразуются дисплеем в физические фотоны. Ошибка в интерпретации цветового пространства на этапе декодирования полностью разрушает математическую модель искажения, из-за чего ломаются даже идеально оптимизированные алгоритмы Хаффмана.
👗 Иллюзия платья и рождение цветового пространства YUV 30:50
Вторая важнейшая концепция — оппонентная теория цветового зрения. Трихроматическая модель не объясняет всех парадоксов нашего восприятия.
Яркий пример — знаменитый интернет-мем с фотографией платья, которое одни люди видят как сине-черное, а другие — как золото-белое, несмотря на идентичные RGB-пиксели на экране. Другой пример — оптический феномен «сиреневого преследователя» (Lilac Chaser). Если долго смотреть на крестик в центре вращающихся фиолетовых кругов, исчезающий круг внезапно покажется зрителю зеленым или желтовато-зеленым.
Зрительная система человека склонна адаптироваться и «вычитать» статичные цвета. Оппонентная теория утверждает, что сигналы от LMS-колбочек не передаются в мозг напрямую. На выходе из сетчатки они объединяются нейронами в три контрастные пары (оппонентные каналы):
- Яркостный канал (белый минус черный), формирующийся суммированием волн.
- Канал «красный-зеленый».
- Канал «синий-желтый».
Биологическая оппонентная модель легла в основу инженерного разделения сигналов на компоненты YUV (или YCbCr). Инженеры отказались от хранения чистых каналов RGB и перешли к схеме, где:
- Y (Luma) — отвечает за яркость (черно-белый контур изображения).
- U / Cb (Chroma Blue) — кодирует разность синего и желтого цветов.
- V / Cr (Chroma Red) — кодирует разность красного и зеленого цветов.
📉 Хрома-субсемплинг: как сэкономить половину файла, обманув мозг 36:44
Контрастная чувствительность человеческого глаза к изменению цвета (компоненты Cb и Cr) падает колоссально быстро с ростом пространственной частоты по сравнению с чувствительностью к изменению яркости (компонента Y). Простыми словами: мозг четко видит резкие границы перепада света и тени, но моментально теряет фокус, если на высокой частоте начинают чередоваться мелкие цветовые оттенки.
Это позволяет применить радикальный даунсемплинг к цветовым каналам, оставляя неизменным разрешение яркостного канала Y. Данный шаг заложен в основу алгоритма JPEG. Переход от RGB к YCbCr с последующим сжатием цвета позволяет уменьшить объем несжатого массива данных еще до начала работы основного кодера. Человек при этом визуально не замечает разницы между оригиналом и пережатой копией.
Более того, сильное уменьшение разрешения цветовых каналов искусственно повышает корреляцию (схожесть) между соседними пикселями. Последующие этапы сжатия JPEG (например, дискретное косинусное преобразование DCT и кодирование Хаффмана) используют эту корреляцию для повторного извлечения выгоды. Эффект экономии перемножается, снижая вес файла почти вдвое.
В спецификациях видео и изображений вы постоянно будете встречать маркировки субсемплинга вида 4:4:4, 4:2:2 или 4:2:0. Формат 4:4:4 означает полное разрешение без потерь.
Самым популярным дефолтным стандартом в мире является формат YUV 4:2:0. При кодировании в 4:2:0 берется блок пикселей размера $2 \times 2$. Значения яркости Y сохраняются для каждого из четырех пикселей индивидуально, а цветовые значения U и V усредняются по всему блоку. Вместо четырех уникальных цветовых пар кодер сохраняет всего одну, отбрасывая огромный пласт информации.
⚠️ Опасные артефакты субсемплинга и проблемы цветовых матриц 44:56
Агрессивное усреднение цвета в формате 4:2:0 таит в себе серьезную опасность в практических сценариях. Если изображение содержит искусственные высококонтрастные элементы (например, скриншот консольного терминала, где тонкие красные буквы написаны на глубоком синем фоне), субсемплинг приводит к катастрофическим хроматическим артефактам.
Принудительное математическое усреднение цвета в окне $2 \times 2$ на стыке букв приводит к тому, что края шрифта размываются, а сам цвет символов физически искажается. С точки зрения классической среднеквадратичной ошибки (MSE) разница может казаться незначительной, но для пользователя такой текст становится нечитаемым.
Дополнительные трудности создает сам процесс конвертации RGB в YUV, который представляет собой стандартное матричное умножение. Коэффициенты этих матриц жестко завязаны на исторические стандарты оборудования.
Например, для старого телевидения стандартной четкости (SDTV) используется одна конверсионная матрица, а для современного высокой четкости (HDTV / sRGB) — совершенно другая. Если проигнорировать эти нюансы при обработке видеопотока, на выходе получится искаженная цветопередача.
Информацию о примененных алгоритмах можно легко извлечь из метаданных с помощью инструмента ExifTool. При разборе стандартного JPEG-файла (например, официального логотипа Stanford University) в логах четко прописываются все этапы: цветовое пространство sRGB, кодирование на базе дискретного косинусного преобразования (Baseline DCT), энтропийное кодирование Хаффмана (Huffman) и субсемплинг YCbCr в конфигурации 4:2:0.
📊 За пределами MSE: эволюция перцептивных метрик качества 50:10
Индустрия сжатия данных десятилетиями опиралась на метрику среднеквадратичного отклонения (MSE), поскольку ее легко рассчитать математически. Однако MSE абсолютно не эквивалентна человеческому восприятию.
Существует хрестоматийный пример: берутся пять вариантов искажения одного исходного кадра. Первый вариант слегка размыт, второй сглажен, на третьем и четвертом искусственно рассыпан пиксельный шум. Математически все пять картинок имеют абсолютно идентичный показатель MSE по отношению к оригиналу. Но при этом для любого человека размытый кадр выглядит приемлемо, в то время как зашумленные варианты кажутся ужасающим браком.
[Иллюстрация неэффективности MSE: исходное изображение и 5 вариантов искажений с одинаковым MSE]
Очевидный провал MSE вынудил ученых заняться разработкой перцептивных метрик, моделирующих человеческое зрение. Современные подходы можно разделить на три крупные категории:
- Математическое моделирование низкоуровневых фич зрения. Самый яркий представитель — индекс структурного сходства SSIM (Structural Similarity), созданный в 2002 году, а также его многомасштабная версия MS-SSIM. Метрика SSIM оценивает изображение по трем независимым параметрам: сохранение средней яркости (luminescence), контраста (contrast) и ковариационной структуры (structure). При расчете среднего значения пикселей в SSIM применяется взвешенный гауссовский фильтр, имитирующий эффект фовеации (фокус на центре блока). Сегодня без отчета по SSIM невозможно опубликовать ни одну научную работу по компрессии.
- Использование глубоких нейросетевых моделей. Вместо ручного прописывания формул инженеры берут предобученные большие сверточные сети и используют их внутренние слои эмбеддингов как пространство признаков. Наиболее популярный метод этой группы — LPIPS (Learned Perceptual Image Patch Similarity), появившийся на рубеже 2018–2020 годов. Эмпирически доказано, что внутренние представления глубоких нейросетей эмерджентно копируют логику распознавания фич человеческой зрительной корой.
- Гибридные метрики с человеческим обучением. Данный подход комбинирует ручные низкоуровневые признаки с машинным обучением, параметры которого настраиваются на основе массовых субъективных тестов (когда тысячи реальных людей оценивают качество кадров по шкале). Главный стандарт здесь — метрика VMAF, разработанная и популяризированная стриминговым гигантом Netflix в 2015 году.
🌾 Компромисс RDP: когда фейковая трава лучше размытого оригинала 1:04:12
В 2018–2019 годах исследователи совершили фундаментальный прорыв в теории информации, доказав существование трехстороннего компромисса — Rate-Distortion-Perception (RDP), то есть баланса между скоростью передачи данных (битрейтом), математическим искажением (Distortion) и визуальной реалистичностью (Perception).
Суть концепции идеально иллюстрирует эксперимент со сжатием фотографии зеленого газона на территории Стэнфорда. Если сильно зажать изображение травы стандартным кодеком JPEG, газон превратится в унылое размытое месиво. Но если пропустить этот же кадр через генеративную нейросеть (GAN), она полностью перерисует текстуру. Каждая травинка на сгенерированной картинке окажется на случайном новом месте, не совпадающем с оригиналом.
С точки зрения математики и метрики MSE нейросетевой кадр имеет чудовищное искажение. Но если спросить человека, какой вариант он предпочтет — размытый оригинал JPEG или четкую сгенерированную нейросетью траву, абсолютное большинство выберет генеративный вариант. Человеку неважно точное геометрическое расположение мелких объектов на текстурах ковра или газона, ему важна их общая статистическая достоверность.
Математически восприятие теперь моделируется как расстояние между распределениями вероятностей оригинального ($P_X$) и реконструированного ($P_{\hat{X}}$) сигналов. Вместо классической оптимизации двух параметров ($R + \lambda D$) инженерам приходится балансировать уравнение по трем осям.
Эффект наглядно виден на примере сжатия рукописных цифр из базы данных MNIST на экстремально низком битрейте в 2 бита. Чистая оптимизация по Шеннону дает размытые, нечитаемые пятна. Добавление жесткого штрафа за восприятие делает символы невероятно четкими, но возникает опасный побочный эффект: из-за нехватки битов нейросеть может случайно перерисовать распределение и превратить исходную цифру 5 в четкую цифру 7.
Свежие математические теоремы 2019 года доказывают, что при соблюдении определенных условий можно строго ограничить максимальную ошибку искажения, даже если алгоритм полностью оптимизируется под идеальное визуальное восприятие. Это гарантирует, что нейросеть не начнет бездумно генерировать посторонние объекты там, где важна точность.
🤖 Нейросетевое сжатие: GAN, диффузия и будущее компрессии с LLM 1:11:48
Поскольку современные метрики вроде SSIM или LPIPS являются линейными или дифференцируемыми операторами, их можно напрямую встраивать в качестве функций потерь (Loss function) при обучении нейросетевых компрессоров. В последние годы стандартом стало обучение моделей на базе комбинированной потери:
Loss = MAE + LPIPS
Здесь среднеквадратичное (или среднее абсолютное MAE) отклонение удерживает нейросеть от глобального изменения структуры кадра и уплывания пикселей, а перцептивный критерий LPIPS заставляет модель сохранять высокую четкость и микротекстуры.
Альтернативный путь — использование генеративно-состязательных сетей (GAN), где за оценку качества отвечает отдельная сеть-дискриминатор, пытающаяся отличить сжатый кадр от реального. Настоящим прорывом в этой области стала архитектура HiFiC (High-Fidelity Generative Image Compression), объединившая условные GAN, LPIPS и MSE для достижения революционного качества сжатия.
Стремительное развитие генеративных моделей (таких как Stable Diffusion, DALL-E и Clip) открывает принципиально новые горизонты для компрессии. Большие языковые модели (LLM) накопили в себе колоссальные знания о структуре нашего мира. Текущие исследования направлены на то, чтобы заставить декодер на стороне пользователя буквально «додумывать» и генерировать целые куски реалистичного изображения по минимальному набору текстовых или векторных подсказок, переданных по сети, обеспечивая экстремально низкий битрейт.
Эпоха сжатия исключительно ради минимизации математической ошибки MSE подошла к концу. Будущее компрессии — будь то обработка видео в виртуальной реальности (VR), хранение геномных данных или специфических показателей медицинских датчиков — лежит на стыке инженерии, нейробиологии и глубокого понимания контекста использования данных.




