В видеообзоре известного ИИ-исследователя Янника Килчера (Yannic Kilcher) подробно разбирается научная работа специалистов из Facebook AI Research (FAIR) и INRIA, посвященная новой архитектуре под названием Expire-Span. Авторы предложили инновационный подход к оптимизации механизма внимания в трансформерах, обучая нейросеть самостоятельно «забывать» нерелевантную информацию. Это решение позволяет моделям эффективно обрабатывать контекст из десятков тысяч токенов, успешно преодолевая классические вычислительные ограничения базовых архитектур.
🧠 Проблема бесконечного контекста: почему трансформеры «помнят» слишком много 2:01
Механизмы внимания (Attention) совершили прорыв в моделировании последовательностей, требующих долговременной памяти. Однако стандартный подход авторегрессионного декодера, где каждый новый токен может ссылаться только на свое прошлое, имеет фундаментальный математический недостаток. С увеличением длины последовательности количество элементов, к которым необходимо обращаться на каждом шаге, лавинообразно растет. Это приводит к традиционной квадратичной сложности вычислений и жестким затратам памяти, описываемым как $O(N^2)$.
Для наглядной иллюстрации проблемы Янник Килчер приводит в пример классическое английское предложение «The cat sat on the mat». По его мнению, далеко не все слова в этой фразе одинаково важны для предсказания финального слова «mat». Оценивать важность контекста можно следующим образом:
- Артикль «the» практически бесполезен для семантического прогнозирования и удержания в памяти.
- Комбинация «sat on» (сидела на) критически важна, так как указывает на высокую вероятность появления физического объекта (коврика, стула или дивана).
- Существительное «cat» (кошка) имеет среднюю степень важности для общей структуры повествования.
Если бы ИИ-система могла отбрасывать незначительные токены вроде артиклей, количество элементов в рабочей памяти существенно сократилось бы. Главная цель технологии Expire-Span — снизить вычислительную сложность алгоритмов внимания до уровня $O(N \times M)$, где $M$ представляет собой динамически регулируемый размер активной памяти, очищенной от «мусора».
⏳ Принцип работы Expire-Span: динамическое время жизни воспоминаний 5:44
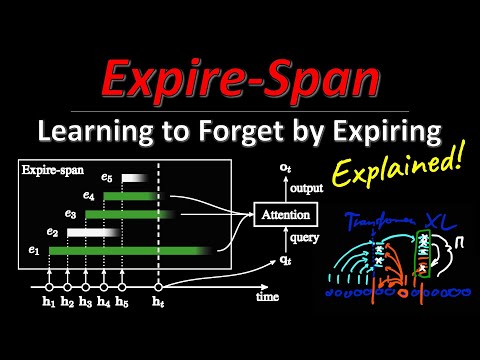
В традиционных архитектурах трансформеров каждый элемент последовательности проходит через слои нейросети, генерируя скрытое состояние $H$ и предсказание $Y$. Модель Expire-Span добавляет к этому процессу принципиально новый шаг: на каждом временном этапе она вычисляет дополнительный параметр $E$ — длительность хранения (expiration duration) конкретного воспоминания.
Значение $E$ формируется напрямую из скрытого состояния $H$ и определяет, как долго этот вектор будет доступен для механизма внимания последующих токенов. Ведущий детально описывает этот алгоритм на абстрактном примере:
- Для скрытого состояния $H_1$ нейросеть вычисляет значение $E_1 = 2$, то есть оно должно оставаться валидным ровно два шага.
- Последующие токены $H_2$ и $H_3$ могут беспрепятственно обращаться к памяти $H_1$ в рамках своего окна видимости.
- Однако при переходе к генерации токена $H_4$ память $H_1$ уже считается официально истекшей, и система полностью удаляет ее из графа вычислений, блокируя возможность обращения.
По словам Янника Килчера, данный подход кардинально отличается от стандартного локального внимания (local attention) с фиксированным окном размера $L$. В случае фиксированного окна все токены имеют абсолютно равную ценность, и критически важная информация безвозвратно теряется, как только она выходит за рамки жесткого лимита. В Expire-Span ключевой токен может получить гигантский «срок годности» (например, миллиард шагов), оставаясь доступным бесконечно долго, в то время как неинформативные элементы будут удаляться практически мгновенно.
🔧 Маскирование внимания и преодоление проблемы дифференцируемости 18:39
С технической точки зрения ограничение зоны внимания реализуется через специальную маску. В авторегрессионных декодерах верхняя треугольная часть матрицы внимания всегда маскируется нулями на уровне графического процессора (GPU), чтобы модель не могла «заглядывать в будущее». Expire-Span накладывает поверх этого свою динамическую маску, отсекающую элементы, чей срок жизни подошел к концу.
Само по себе вычисление остаточного времени жизни памяти строится на простом математическом условии: если разница между текущим временем и моментом создания токена превышает предсказанное значение $E$, итоговый индекс становится отрицательным, что указывает на необходимость удаления данных. Однако прямое использование дискретного (бинарного) маскирования делает функцию недифференцируемой — в таком жестком режиме модель просто не сможет получать градиенты для обучения.
Чтобы решить эту проблему оптимизации, авторы работы применили метод мягкого маскирования (soft masking), который плавно переводит значения маски от 1 к 0:
- Логистическая регрессия: Первичное значение $E$ рассчитывается с помощью функции сигмоиды, возвращающей значение от 0 до 1, которое затем умножается на гиперпараметр $L$ (максимально возможная длина хранения контекста).
- Линейный спад (Ramp Drop-off): Маска сохраняет значение 1 на протяжении основного срока жизни воспоминания, а затем линейно затухает до 0 на отрезке, регулируемом гиперпараметром $R$.
Янник Килчер подчеркивает, что этот математический компромисс накладывает серьезные ограничения на обучение системы. Модуль, генерирующий время жизни памяти, получает обучающий сигнал (градиент) исключительно в узкой зоне этого линейного спада $R$. Если важный токен должен быть востребован далеко в будущем, но гиперпараметр $L$ изначально задан некорректно, или спад произошел слишком рано, модель никогда не получит сигнал о том, что эту память нужно было удерживать дольше.
Дополнительно авторы используют регуляризацию $L_1$ ($L_1$ penalty) для штрафования модели за слишком длинные сроки хранения информации. По умолчанию сеть стимулируют активно забывать информацию, и только сильный обучающий сигнал из функции потерь заставляет её увеличивать время жизни токенов.
🏢 Архитектурный фундамент: интеграция с Transformer-XL 13:43
Разработчики из FAIR построили свое решение на базе известной архитектуры Transformer-XL, которая выступает здесь главным бэйслайном для сравнения. Transformer-XL решает проблему длинных последовательностей путем разбиения входящего текста на отдельные блоки фиксированного размера.
Особенности работы базовой архитектуры Transformer-XL:
- Вычисления внутри текущего блока происходят стандартным образом.
- Скрытые состояния из предыдущего блока сохраняются в специальный кэш-регистр с обязательным применением операции прекращения градиентов (
stop_gradient). - Токены нового блока могут свободно обращаться как к элементам своего блока, так и к кэшированным векторам прошлого периода.
Трансформер-XL позволяет хранить кэш нескольких прошлых блоков, однако удерживать их бесконечно невозможно из-за квадратичного роста затрат вычислительных ресурсов. Expire-Span интегрируется прямо в этот механизм: модель обрабатывает данные блоками, но при обращении к кэшу прошлых периодов учитывает только те скрытые состояния, чье динамическое время жизни еще не истекло. Это позволяет кардинально уменьшить количество активных слотов памяти и заглядывать гораздо дальше в прошлое при неизменном объеме аппаратных мощностей.
🔬 Результаты практических экспериментов: от языковых моделей до Grid World 32:33
Эффективность Expire-Span тестировалась разработчиками на нескольких разноплановых задачах: посимвольном языковом моделировании, текстовых инструкциях, детекции столкновений на видео и в обучении с подкреплением (RL).
В задаче посимвольного моделирования исследователи визуализировали, какие именно слова система считает приоритетными для сохранения. Оказалось, что в предложении «powerful influence in Egypt... Alexander» модель максимально продлевает срок жизни уникальных имен собственных и географических названий — «Egypt» и «Alexander». Если заменить слово «Egypt» на абстрактное «somewhere», алгоритм мгновенно забывает его, но при замене на редкое выражение вроде «Humpty Dumpty» — снова пролонгирует память. На основе этого авторы заявляют, что модель успешно научилась выделять редкие слова и имена на основе их значимости.
Наиболее наглядным примером превосходства алгоритма стал тест в Grid World на задачу с длинным коридором (Corridor Task). Агент начинает движение в комнате определенного цвета (красный или синий), затем должен пройти через экстремально длинный коридор и в конце открыть дверь, цвет которой соответствует стартовому.
Результаты сравнения показали явное преимущество нового метода:
- Transformer-XL требует пропорционального увеличения физического размера памяти. При малых объемах кэша он демонстрирует случайные результаты (около 50% успеха) и начинает справляться, только когда размер памяти физически покрывает длину коридора.
- Expire-Span стабильно и безошибочно решает задачу при минимальном эффективном размере памяти.
Согласно анализу приложений к статье, длина коридора варьировалась случайным образом от 3 до 200 шагов. Параметр максимального окна $L$ был выставлен на 200, а зона спада $R$ составила 16 шагов. По мнению Янника Килчера, именно такая случайная генерация длины обеспечила идеальную структуру потерь: модель плавно обучалась удерживать память дольше, так как задачи разной длины регулярно попадали в активную зону градиентного спада $R$.
💡 Ограничения технологии и предложения по улучшению от Янника Килчера 10:47
Несмотря на выдающиеся результаты, Янник Килчер выделяет фундаментальную концептуальную слабость Expire-Span. Модель обязана принять окончательное решение о времени жизни воспоминания в момент его первого прочтения (потребления токена), полностью изолированно от того, что произойдет в последовательности дальше.
В реальной жизни или сложных текстах ценность информации часто раскрывается ретроспективно. Слово, казавшееся незначительным, через 1000 шагов может стать ключевым триггером, но к этому моменту Expire-Span уже безвозвратно сотрет его. В этом плане архитектура уступает классическим рекуррентным сетям (LSTM), которые способны динамически обновлять свое внутреннее состояние на каждом шагу, делая запоминание зависимым от последующего контекста. Однако LSTM проигрывают из-за невозможности параллельного обучения и необходимости сквозного обратного распространения ошибки во времени (BPTT).
В качестве развития этой идеи Янник Килчер предлагает два авторских направления для будущих исследований:
- Механизм пересмотра памяти: Добавить в трансформер возможность «вспоминать» или корректировать предсказанный срок жизни токенов на основе вновь поступающих свидетельств, не скатываясь при этом в тяжеловесную структуру LSTM.
- Древовидная иерархия: Вместо плоского линейного буфера (банка памяти) организовать хранение прошлых состояний в виде древовидной структуры (наподобие дерева Меркля), но использующей скрытые латентные переменные вместо хэш-функций.
В заключение ведущий отмечает, что Expire-Span — это отличная, рабочая система для задач со сверхдлинными последовательностями, где критически важно удерживать лишь несколько ключевых островков информации на огромных дистанциях.