Сфера компьютерного зрения в последние годы переживает настоящий бум, демонстрируя результаты, которые казались недостижимыми еще несколько лет назад. Основатель DeepLearning.AI Эндрю Ын подробно разбирает переход от простой классификации изображений к более сложным задачам — локализации и детекции объектов, которые лежат в основе современных систем автономного вождения.
🎯 От классификации к локализации: иерархия задач 0:00
Эндрю Ын выделяет три ключевых этапа в развитии алгоритмов распознавания образов . По его словам, понимание локализации является необходимым фундаментом для перехода к полноценному обнаружению (detection) нескольких объектов на одном кадре.
- Классификация изображений (Classification): Алгоритм смотрит на картинку и определяет основной объект (например, «это автомобиль») .
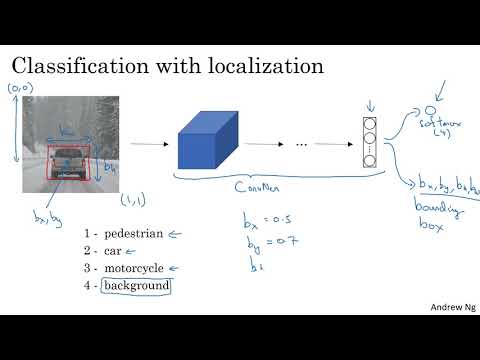
- Классификация с локализацией (Classification with Localization): Нейросеть не только присваивает метку класса, но и рисует ограничивающую рамку (bounding box) вокруг объекта .
- Детекция (Detection): Самая сложная задача, где на одном изображении может находиться множество объектов разных категорий, каждый из которых должен быть найден и выделен .
В рамках локализации Эндрю Ын предлагает фокусироваться на сценарии, где в кадре присутствует один крупный объект, расположенный преимущественно в центре . Технологии, отработанные на этом этапе, позже масштабируются для систем беспилотного транспорта, где необходимо одновременно отслеживать пешеходов, мотоциклистов и другие автомобили .
📦 Анатомия ограничивающей рамки (Bounding Box) 2:11
Стандартный конвейер классификации включает в себя сверточную нейросеть (ConvNet), на выходе которой вектор признаков подается в Softmax-слой для определения класса объекта . Чтобы добавить функцию локализации, структуру сети необходимо расширить.
Для выделения объекта нейросеть должна предсказывать четыре дополнительных числа, характеризующих Bounding Box :
- $B_x$ — координата X центра объекта.
- $B_y$ — координата Y центра объекта.
- $B_h$ — высота ограничивающей рамки (height).
- $B_w$ — ширина ограничивающей рамки (width).
В рамках курса Эндрю Ын использует систему координат, где верхний левый угол изображения имеет координаты (0, 0), а нижний правый — (1, 1) . Таким образом, все параметры рамки являются относительными величинами от 0 до 1. Например, если $B_h$ равно 0.3, это означает, что высота рамки составляет 30% от общей высоты изображения .
📑 Структура целевого вектора Y 5:18
Для обучения нейросети методом «обучения с учителем» (supervised learning) необходимо сформировать расширенный вектор меток $Y$ . В примере с беспилотным автомобилем Эндрю Ын использует три основных класса (пешеход, автомобиль, мотоцикл) и категорию «фон» .
Вектор $Y$ состоит из 8 компонентов:
- $P_c$ (Probability of Class): Бинарный индикатор. $P_c = 1$, если в кадре есть любой из целевых объектов, и $P_c = 0$, если перед нами пустой фон .
- $B_x, B_y, B_h, B_w$: Координаты рамки (актуальны только при $P_c = 1$) .
- $c_1, c_2, c_3$: Вероятности конкретных классов (пешеход, авто или мотоцикл) .
Эндрю Ын подчеркивает важный нюанс: если на изображении нет объекта ($P_c = 0$), то все остальные параметры вектора становятся «безразличными» (don’t cares), что обозначается вопросительными знаками в обучающей выборке . Алгоритму в этом случае неважно, какие координаты или классы он предскажет, так как объекта в реальности не существует .
📉 Оптимизация и функция потерь 8:46
Выбор функции потерь (loss function) зависит от того, содержит ли изображение объект. В качестве базового варианта Эндрю Ын рассматривает среднеквадратичную ошибку (squared error) .
Расчет потерь происходит по двум сценариям:
- Если объект есть ($P_c = 1$): Потеря вычисляется как сумма квадратов разностей всех 8 компонентов вектора $Y$ и предсказанного вектора $\hat{Y}$ .
- Если объекта нет ($P_c = 0$): Нас интересует только точность предсказания параметра $P_c$. В этом случае потеря — это просто квадрат разности между предсказанным и реальным $P_c$ .
Хотя использование среднеквадратичной ошибки упрощает понимание, Эндрю Ын отмечает, что на практике часто применяются комбинированные подходы . По его мнению, для классификации ($c_1, c_2, c_3$) эффективнее использовать логистическую регрессию или Softmax (log-likelihood loss), в то время как для координат рамок лучше оставить среднеквадратичную ошибку или её аналоги .
Идея заставить нейросеть выдавать набор вещественных чисел в качестве регрессионной задачи оказывается чрезвычайно мощным инструментом, который находит применение не только в локализации, но и в других задачах компьютерного зрения .




