Лаборатория ИИ DeepMind представила алгоритм Agent57, ставший первой системой искусственного интеллекта, способной превзойти человеческий уровень производительности во всех 57 играх классического тестового набора Atari. Аналитик Янник Кильхер разбирает техническую эволюцию архитектур обучения с подкреплением, которая сделала это достижение возможным, и подробно анализирует внутренние механизмы нового агента. В то же время эксперт ставит под сомнение реальную универсальность системы, указывая на признаки избыточного инженерного приспособления под конкретный бенчмарк.
🕹️ Эволюция обучения с подкреплением: от DQN к R2D2 0:00
Долгое время игра Solaris оставалась одним из самых сложных испытаний для систем обучения с подкреплением (Reinforcement Learning, RL). Проблема заключалась в структуре распределения наград: агент мог совершать множество действий, но игровой счет на экране не менялся в течение длительного времени. Agent57 базируется на целой серии фундаментальных улучшений классической архитектуры Deep Q-Networks (DQN), разработанной DeepMind еще в 2015 году. Именно публикация 2015 года популяризировала бенчмарк Atari и впервые доказала эффективность связки глубоких нейросетей с обучением с подкреплением.
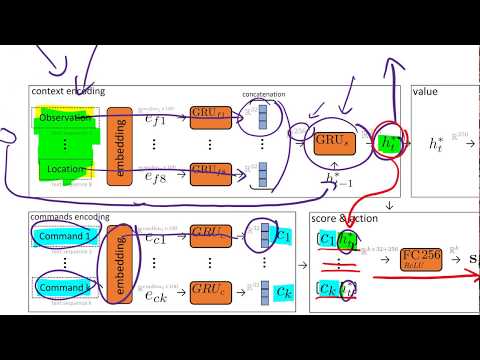
В классической парадигме RL взаимодействие строится между агентом и средой. Среда выдает наблюдение (в данном случае — текущий кадр игры), а агент должен в ответ выбрать действие. В играх Atari доступно около 20 вариантов действий, сочетающих отклонения джойстика и нажатие кнопки. После этого среда возвращает измененный кадр и определенную награду. Если в игре Pac-Man награда поступает непрерывно за каждую съеденную точку, то в таких играх, как Montezuma's Revenge, агенту необходимо пройти через цепочку комнат, лестниц и врагов, найти ключ, дойти до двери и лишь тогда получить первый положительный сигнал.
Для решения задач с отложенной наградой стандартная архитектура DQN, обновляющая параметры пошагово, оказалась неэффективной. Важным шагом вперед стал алгоритм R2D2, в который интегрировали рекуррентные блоки LSTM или GRU. Благодаря этому сеть начала принимать на вход не просто один изолированный кадр, а закодированную историю прошлых наблюдений и действий за последние 10–100 шагов. Это позволило градиентам напрямую проходить сквозь историю состояний, качественно решая задачу кредитования ответственности (credit assignment) — определения того, какие именно действия в прошлом привели к текущему успеху.
Кроме того, архитектура R2D2 внедрила распределенный подход к вычислениям:
- Центральный узел (Learner): хранит основные веса нейросети $\theta$ и занимается их непрерывным обновлением.
- Рабочие узлы (Workers): множество независимых агентов, которые параллельно запускают игровые сессии, собирают опыт и отправляют его центральному вычислителю, периодически синхронизируя веса.
⚖️ Дилемма исследования и эксплуатации 9:59
Несмотря на масштабируемость, главным недостатком алгоритма R2D2 оставалась примитивная стратегия балансирования между исследованием среды (exploration) и эксплуатацией накопленных знаний (exploitation). Традиционно для этого применялся так называемый эпсилон-жадный метод ($\epsilon$-greedy).
Суть данного подхода заключается в фиксации параметра $\epsilon$ (например, на уровне 5%):
- С вероятностью $1 - \epsilon$ агент совершает действие, которое, по его текущим оценкам, принесет максимальную награду (эксплуатация).
- С вероятностью $\epsilon$ агент выбирает абсолютно случайное действие из доступных (исследование).
Янник Кильхер иллюстрирует уязвимость такой логики на примере космического симулятора. Перед космическим кораблем находятся два метеорита, а чуть дальше — золотая монета. Если агент выбирает действие «выстрел», он уничтожает первый метеорит и сразу получает +1 к награде, но затем неизбежно погибает от второго метеорита. Если же агент выберет действие «движение вправо», в текущем кадре он получит 0 наград, однако сможет облететь препятствия, забрать монету и открыть путь к цепочке из пяти последующих наград.
Жадный алгоритм, зафиксировав быструю награду от выстрела и не умея заглядывать дальше, застревает в локальном оптимуме и постоянно выбирает деструктивную эксплуатацию.
Для исправления этого перекоса был разработан алгоритм Never Give Up (NGU), сфокусированный на создании механизмов внутренней мотивации и «любопытства». К стандартной внешней награде от игровой среды ($r_{ext}$) разработчики добавили собственный внутренний компонент — $r_{int}$, который поощряет агента за обнаружение новизны. Посещая состояния и кадры, которые нейросеть ранее не видела, агент получает дополнительное внутреннее подкрепление, что мотивирует его сознательно выбирать маршруты с нулевой немедленной внешней наградой ради долгосрочного изучения карты.
🧠 Внутренний выбор Agent57: разделение Q-функции и метаконтроль 17:46
Главная инновация Agent57 заключается в автоматизации и тонкой настройке этого деликатного баланса под каждую конкретную игру. Разработчики из DeepMind осознали, что единая фиксированная конфигурация параметров любопытства не способна одинаково хорошо работать и в простых аркадах, и в сложных долгосрочных стратегиях.
Первым серьезным изменением структуры стало математическое разделение классической функции полезности (Q-функции) на два независимых потока. Теперь итоговое значение рассчитывается по формуле:
$$Q(s, a) = Q_{ext}(s, a) + \beta \cdot Q_{int}(s, a)$$
Параметр $\beta$ выполняет роль регулятора: при высоких значениях $\beta$ агент превращается в исследователя-экстремала, игнорирующего игровой счет ради поиска новизны, а при низких — в прагматичного игрока, нацеленного только на результат.
Вторым критически важным рычагом управления стал фактор дисконтирования $\gamma$, определяющий глубину планирования. Итоговая ценность состояния формируется как взвешенная сумма наград:
$$V(s) = \sum_{k=0}^{H} \gamma^k R_{t+k}$$
Если установить $\gamma$ на уровне 0.1, ИИ будет ценить только те награды, которые можно получить буквально на следующем шаге. Если же поднять $\gamma$ до 0.999, то награда, отдаленная на 100 шагов в будущее, становится для агента почти столь же ценной, сколь и мгновенная.
Agent57 динамически управляет параметрами $\beta$ и $\gamma$ прямо в процессе обучения. В начале сессии агенту выгоднее иметь высокий уровень любопытства (большая $\beta$) и короткий горизонт планирования для построения базовой карты ценностей, а ближе к концу — минимизировать внутренние стимулы и увеличивать глубину прогноза, максимизируя итоговый счет.
Для реализации этой схемы инженеры DeepMind внедрили надстрочный блок — метаконтроллер. Архитектура не меняет параметры непрерывно, а выбирает одну из дискретных стратегий (например, из шести фиксированных профилей комбинаций $\beta$ и $\gamma$). Метаконтроллер оценивает эффективность работы каждого профиля на основе возвращаемой из среды общей выручки наград и перераспределяет приоритеты, решая, какая именно стратегия должна генерировать игровой опыт в данный момент времени.
📉 Проблема мета-инжиниринга и критика концепции AGI 30:10
Несмотря на выдающиеся результаты Agent57 на тестовом наборе, Янник Кильхер высказывает аргументированный скепсис относительно архитектурной избыточности решения. По мнению аналитика, использование алгоритма многоруких бандитов со скользящим окном (sliding window bandit) для обучения самого метаконтроллера не решает проблему фундаментально, а лишь переносит дилемму исследования-эксплуатации на один уровень выше. У метаконтроллера появляются собственные скрытые гиперпараметры (например, размер этого самого скользящего окна), которые исследователям снова приходится настраивать вручную.
Кильхер утверждает, что подобный подход начинает напоминать «мета-оверэнжиниринг» — процесс искусственной и чрезмерной подгонки алгоритмических надстроек под узкие особенности конкретного бенчмарка Atari. Вместо создания гибкой, по-настоящему адаптивной системы, инженеры фактически занимаются тонким оверфиттингом структуры под 57 известных конфигураций.
Особую критику со стороны ведущего вызвало позиционирование работы сотрудниками DeepMind. По словам Кильхера, авторы статьи неоправданно начинают повествование с рассуждений о том, как измерять прогресс на пути к созданию сильного искусственного общего интеллекта (AGI). Эксперт считает попытки увязать стопроцентное прохождение старого набора двумерных видеоигр с реальным продвижением к универсальному человеческому мышлению исключительно маркетинговым ходом.