В своем видеообзоре популярный исследователь искусственного интеллекта Янник Кильхер (Yannic Kilcher) подробно разбирает фундаментальную научную работу «Neural Ordinary Differential Equations» (Нейронные обыкновенные дифференциальные уравнения). Авторами этого прорывного исследования, кардинально меняющего подход к проектированию глубоких нейросетей, выступили Рики Чен, Юлия Рубанова, Джесси Беттанкур и Дэвид Дювено. Суть новой концепции заключается в отказе от традиционной архитектуры из дискретных слоев в пользу непрерывных математических систем, управляемых специализированными алгоритмами-солверами.
🧠 От дискретных слоев к непрерывному времени: концепция Neural ODE 0:00
Рассматриваемая научная статья описывает совершенно новое семейство моделей глубокого обучения. Вместо того чтобы выстраивать жесткую дискретную последовательность скрытых слоев, исследователи предложили параметризовать производную скрытого состояния с помощью нейросети. Итоговый выход всей системы вычисляется при помощи стороннего «черного ящика» — численного решателя дифференциальных уравнений (ODE solver).
По мнению Янника Кильхера, данная концепция выглядит невероятно многообещающей и свежей. Модели с непрерывной глубиной (continuous-depth models) обладают целым рядом уникальных преимуществ:
- Константный расход оперативной памяти при обучении.
- Адаптивная стратегия вычислений под каждый конкретный входной объект.
- Возможность явного компромисса между численной точностью и скоростью работы.
Чтобы понять суть нововведения, Янник Кильхер предлагает обратиться к классическим остаточным нейросетям (ResNet). В традиционной архитектуре каждый скрытый слой вычисляет новое представление данных, добавляя некоторое изменение к предыдущему состоянию. В обычной рекуррентной сети для получения следующего шага выполняется последовательное умножение на матрицу весов. В сетях типа ResNet слой обучается не полной трансформации, а лишь вычислению разницы (дельта-изменения) между текущим и следующим шагами. Таким образом, архитектурное смещение направлено на сохранение идентичности представления данных, меняя его лишь незначительно на каждом шаге.
🔢 Непрерывный предел глубоких сетей 3:37
Если представить процесс прохождения через очень глубокую нейросеть как развитие системы во времени, то шаги между слоями можно сделать бесконечно малыми. В этот момент дискретная модель превращается в динамический непрерывный процесс — обыкновенное дифференциальное уравнение. Время становится непрерывной величиной, а локальная линеаризация позволяет описать переход к каждому следующему бесконечно малому моменту времени через функцию $F$.
В непрерывном случае производная скрытого состояния сети параметризуется весами нейросети. Математический решатель дифференциальных уравнений (ODE solver) строит траекторию системы, отталкиваясь от стартового состояния. На каждом бесконечно малом шаге алгоритм обращается к функции $F$, чтобы узнать текущий градиент направления движения, и корректирует траекторию.
С практической точки зрения это открывает уникальные возможности для классификации:
- В качестве стартового состояния берется входной объект, например, изображение из датасета MNIST.
- Нейросеть обучается выдавать правильные производные для кривой на каждом участке времени.
- При решении дифференциального уравнения финальная точка траектории должна в точности соответствовать правильной метке класса.
Вместо прямого прохода от входа к выходу через фиксированные слои, нейросеть задает закон изменения системы в любой точке временного континуума.
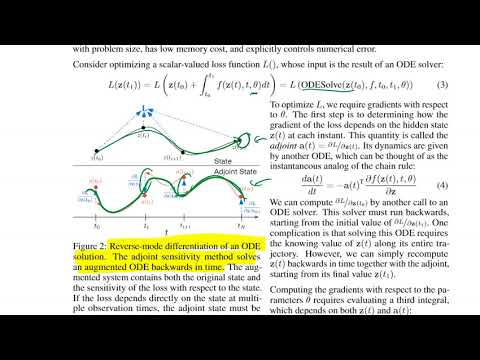
🛠️ Метод сопряженных состояний: революция в оптимизации памяти 8:20
Для успешного обучения такой системы стандартный подход с фиксацией промежуточных этапов не подходит. Традиционная нейросеть требует хранения в памяти всех активаций слоев для последующего обратного распространения ошибки (backpropagation). В случае с бесконечным числом слоев в Neural ODE это потребовало бы колоссального объема памяти.
Как отмечает Янник Кильхер, функция потерь может зависеть как от конечного состояния системы, так и от промежуточных этапов. Чтобы обучить параметры $\theta$, необходимо вычислять градиенты функции потерь. Прямой бэкпропагейшн через внутренние операции численного решателя привел бы к огромным затратам ресурсов. Авторы статьи изящно обходят эту проблему, применяя метод сопряженных состояний (Adjoint Sensitivity Method).
Этот метод работает следующим образом:
- Сначала выполняется прямой проход (forward pass), в ходе которого ODE-солвер вычисляет траекторию системы и находит конечное состояние.
- Затем запускается второе, дополненное дифференциальное уравнение в обратном направлении во времени.
- Вместе первая и вторая кривые позволяют математически точно рассчитать необходимые градиенты без сохранения промежуточных состояний первого прохода.
Сопряженное состояние (обозначаемое как $a(t)$) представляет собой непрерывный аналог правила дифференцирования сложной функции (chain rule). Оно показывает, как функция потерь зависит от скрытого состояния системы $Z(t)$ в любой произвольный момент времени. Зная финальное значение потерь, алгоритм разворачивает чувствительность системы вспять во времени, позволяя в конечном счете вычислить интеграл и получить точные градиенты для статических параметров $\theta$ сети.
⚖️ Вычислительный компромисс: точность против скорости 16:02
В ходе практической оценки авторы исследования сравнили Neural ODE с традиционными архитектурами и выявили интересную закономерность. В отличие от обычных сетей, здесь невозможно заранее предугадать точное количество вычислительных операций. Солвер динамически уточняет траекторию кривой, совершая столько запросов к функции $F$, сколько требуется для достижения заданной пользователем погрешности.
Янник Кильхер обращает внимание на ключевой компромисс технологии:
- Чем меньшую ошибку в вычислениях мы требуем на прямом проходе, тем больше обращений к функции приходится делать алгоритму.
- С ростом точности пропорционально увеличивается время, затрачиваемое на вычисления.
- Количество вычислений на обратном проходе (backward pass) также возрастает, однако оно стабильно составляет примерно половину от объема вычислений прямого прохода. По мнению ведущего, это весьма обнадеживающий фактор.
Еще одна важная деталь заключается во влиянии процесса обучения на нагрузку. По мере увеличения эпох обучения, ODE-солвер запрашивает все больше и больше вычислений для одних и тех же примеров. Модель пытается уловить более тонкие и сложные закономерности в тренировочных данных, что подтверждает общую работоспособность концепции.
🌀 Работа со сложными временными рядами и экстраполяция 18:42
Помимо базовой классификации, архитектура Neural ODE демонстрирует выдающиеся результаты в анализе последовательностей данных и непрерывных потоков (нормализующих потоков). Традиционные рекуррентные нейросети (RNN) жестко привязаны к регулярным временным интервалам между измерениями. Если данные (например, показатели артериального давления пациента в медицинской карте) поступают хаотично и в случайное время, стандартные RNN сталкиваются с огромными трудностями.
Решением становится использование вариационного автокодировщика (VAE), где классическая RNN выступает в роли энкодера, а Neural ODE — в роли декодера. Поскольку дифференциальные уравнения непрерывны по своей природе, их можно «развернуть» и рассчитать состояние системы абсолютно в любой произвольный момент времени.
Эксперименты на игрушечном датасете со спиралевидным поведением наглядно показали разницу в подходах:
- Декодер на базе стандартной RNN выдает рваную, угловатую траекторию при попытке предсказания.
- Neural ODE генерирует идеально гладкие и физически корректные кривые.
- В задачах экстраполяции (прогнозирования за пределы имеющихся данных, где присутствуют только начальные маркеры) RNN часто уходит в неверном направлении, тогда как непрерывная модель точно продолжает заложенный физический тренд.
По мнению Янника Кильхера, хотя на текущем этапе эксперименты проводятся на относительно небольших моделях и данных, это направление исследований имеет огромный потенциал развития в будущем.




