«Всегда визуализируйте: вы никогда не сможете узнать достаточно о своих данных», — утверждает эксперт, и в разработке Vision Transformer это правило становится фундаментом для борьбы с ошибками модели. Разбираем пошаговый путь от теоретических основ архитектуры до реализации полноценного пайплайна обучения ViT на датасете CIFAR-10, позволяющий повысить точность классификации изображений с помощью аугментации.
🌐 От текста к пикселям: Анатомия классического Трансформера и зарождение ViT 0:00
Классическая теория: Как NLP-трансформеры обрабатывают текст 1:57
Классическая архитектура Transformer кардинально изменила сферу обработки естественного языка (NLP), однако её базовые принципы лежат и в основе современных моделей компьютерного зрения. Любая работа с текстовым трансформером начинается с исходной строки текста, которая разбивается на отдельные элементы — токены. Этот этап называется токенизацией. После разделения текста полученные токены сопоставляются с их уникальными числовыми идентификаторами (Token IDs). Эти идентификаторы передаются во входной слой эмбеддингов (Input Embedding), который преобразует числа в высокоразмерные плотные векторы.
Поскольку архитектура трансформеров по своей природе не обладает встроенным пониманием порядка элементов в последовательности, к полученным векторам эмбеддингов обязательно добавляется позиционное кодирование (Positional Encoding). Это позволяет сохранить контекстную информацию и структуру предложения. Объединенный вектор направляется в блок кодировщика (Transformer Encoder). Внутри него данные проходят через слой многоголового внимания (Multi-Head Attention), а затем попадают в блок Add & Norm. Компонент «Add» представляет собой остаточное подключение (residual connection), объединяющее исходный вектор с результатом работы слоя внимания, после чего слой нормализации стабилизирует эти данные. Далее выходные данные передаются на полносвязный слой (Feed Forward), предназначенный для выявления сложных внутренних закономерностей. Полный классический трансформер также включает в себя блок декодера (Decoder), необходимый для генеративных языковых моделей. Однако в архитектуре Vision Transformer декодер полностью отсутствует — модель опирается исключительно на слои энкодера.
Революция в компьютерном зрении: Принципы архитектуры Vision Transformer 5:28
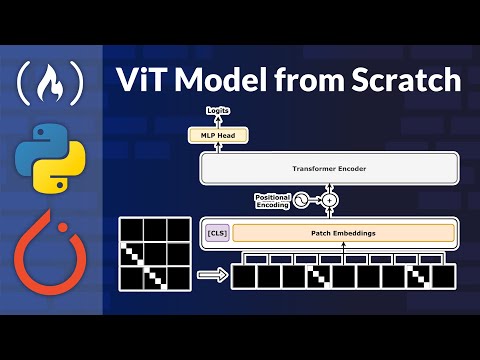
Перенос текстовой архитектуры на работу с графикой требует особого подхода, разработанного Мухаммадом Аль Абра. Главный вызов заключается в том, что стандартный кодировщик трансформера способен оперировать только одномерными последовательностями, в то время как изображения по своей природе двумерны. Для решения этой проблемы входное изображение сегментируется на небольшие квадратные фрагменты фиксированного размера — патчи. Этот процесс концептуально эквивалентен токенизации в текстовых моделях.
Размер патча жестко задается разработчиком: это может быть сетка 16x16 или, как в текущем практическом проекте автора, миниатюрные блоки 4x4 пикселя. Каждый такой патч, изначально имеющий три цветных канала, сглаживается (flattened) в одномерный вектор. Полученные векторы проходят через слой линейной проекции (Linear Projection Layer), который выполняет функцию слоя эмбеддингов и трансформирует их в плотные векторы заданной размерности. По аналогии с NLP, к эмбеддингам патчей добавляются позиционные эмбеддинги для сохранения пространственной структуры изображения. Важнейшим элементом архитектуры является внедрение специального обучаемого вектора — CLS-токена (Classification Token). Он добавляется в самое начало последовательности патчей. Проходя через все слои трансформера, CLS-токен аккумулирует в себе агрегированную информацию о всем изображении, и именно его финальное состояние используется на выходе для классификации. Стоит отметить, что в последующих главах будут детально разобраны конфигурация гиперпараметров, предобработка пакетов данных и непосредственное программирование этого механизма эмбеддингов.
Великое сопоставление: Мост между текстовыми и зрительными моделями 9:36
Для глубокого понимания Vision Transformer (ViT) крайне полезно сопоставить его терминологию с классическими NLP-моделями. Автор наглядно демонстрирует, что каждый шаг обработки изображений имеет прямого аналога в текстовой сфере, хотя математическая реализация некоторых компонентов различается. Например, вместо стандартного слоя эмбеддингов в ViT применяется линейная проекция.
Ниже приведена подробная таблица соответствия ключевых компонентов:
| Компонент / Термин | NLP-Трансформер | Vision Transformer (ViT) |
|---|---|---|
| Базовый элемент | Токен (слово или подслово) | Патч (фрагмент изображения) |
| Идентификатор | Token ID (числовой индекс слова) | Индекс патча (координатная позиция) |
| Векторное представление | Token Embedding (из таблицы эмбеддингов) | Patch Embedding (через линейную проекцию) |
| Информация о порядке | Positional Embedding (порядок слов) | Positional Embedding (пространственная структура) |
| Входная последовательность | Encoder input sequence | Embedded patch sequence |
| Целевой вектор | CLS-токен (обобщение текста) | CLS-токен (обобщение признаков картинки) |
| Финальный предиктор | Слой Softmax | Classification Head (MLP + Softmax) |
В то время как текстовый трансформер выдает вероятности для токенов, ViT передает вектор CLS-токена в классификационную голову (Classification Head), состоящую из многослойного перцептрона и Softmax, для получения финального прогноза. В дальнейших главах мы коснемся реализации слоев MLP и кодировщика.
Разбор полигона: Структура и классы датасета CIFAR-10 20:20
В качестве практического полигона для обучения создаваемой с нуля модели ViT выбран классический набор данных CIFAR-10. Автор подробно знакомит аудиторию со структурой этого датасета, заходя на его официальный сайт. Датасет содержит в общей сложности 60 000 цветных изображений. Каждая картинка имеет фиксированное низкое разрешение — 32x32 пикселя. Наличие трех цветных каналов (красный, зеленый, синий) определяет их как полноцветные RGB-изображения.
Весь объем данных строго распределен по 10 классам. В этот список входят:
- Самолеты (airplane)
- Автомобили (automobile)
- Птицы (bird)
- Кошки (cat)
- Олени (deer)
- Собаки (dog)
- Лягушки (frog)
- Лошади (horse)
- Корабли (ship)
- Грузовики (truck)
Задача создаваемой нейросети — выдать логиты (вероятности) для каждого из этих десяти классов. Итоговое решение модели будет определяться с помощью функции argmax, выбирающей класс с наивысшим значением вероятности. Разработка функций потерь и запуск базового цикла обучения будут подробно раскрыты ближе к концу статьи.
Подготовка рабочей среды: Импорт библиотек и проверка оборудования 22:29
Практическая часть проекта разворачивается в среде Google Colab, где перед написанием кода необходимо настроить аппаратное ускорение. Для эффективных вычислений автор подключает runtime к графическому процессору T4 GPU. После успешной инициализации среды выполняется импорт базовых библиотек экосистемы PyTorch. Первым делом загружается ядро — import torch. Вслед за ним импортируется подмодуль torch.nn (как nn), содержащий заготовки для слоев нейросетей и функций потерь, а также torch.nn.functional (под псевдонимом F).
Для настройки оптимизаторов, таких как Adam или SGD, подключается пакет torch.optim (как optim). Процесс разбиения датасета на пакеты возлагается на утилиту DataLoader, импортируемую из torch.utils.data. Из специализированной библиотеки torchvision извлекаются модули datasets для прямой загрузки CIFAR-10 и transforms для последующих манипуляций с изображениями. Математические операции обеспечиваются библиотекой numpy (как np), а генерация случайных индексов для визуализации картинок — встроенным модулем random. Наконец, для построения графиков и вывода изображений на экран импортируется matplotlib.pyplot под привычным именем plt. В качестве финальной проверки готовности окружения автор запускает вывод версий ПО: установленная версия PyTorch определилась как 2.6.0, а поддержка CUDA базируется на версии 12.4. Вопросы аугментации данных и повторного обучения на расширенном наборе будут рассмотрены в финальной главе.
⚙️ Настройка архитектуры и подготовка данных 28:30
На начальном этапе создания Vision Transformer (ViT) критически важно правильно сконфигурировать гиперпараметры и подготовить конвейер обработки данных. Эти настройки закладывают фундамент для стабильного обучения модели и её способности эффективно извлекать признаки из изображений.
Конфигурация гиперпараметров модели 28:30
После настройки среды и установки генератора случайных чисел (torch.manual_seed(42)), что гарантирует воспроизводимость результатов, инженер приступает к определению гиперпараметров. Выбор этих значений определяет не только архитектурную сложность, но и требования к вычислительным ресурсам.
Ключевые параметры, установленные в проекте:
- Batch Size: 128 (размер пакета). Использование степеней двойки или чисел, кратных 8, является индустриальным стандартом для оптимизации работы GPU.
- Epochs: 10 (количество полных проходов по обучающей выборке). Это значение можно варьировать для поиска баланса между недообучением и переобучением.
- Learning Rate: $3 \times 10^{-4}$ (или $0.0003$), что обеспечивает стабильную сходимость.
- Patch Size: 4. Этот параметр определяет «гранулярность» сегментации изображения.
- Embed Dimension: 256. Внутренняя размерность векторных представлений патчей.
- Depth: 6 (количество трансформерных блоков).
- MLP Dimension: 512 (размерность скрытого слоя в перцептроне).
Предобработка изображений и загрузка данных 31:37
Работа с набором данных CIFAR-10 требует приведения изображений к тензорному формату и их нормализации. Ранее в разговоре они касались общих принципов работы с датасетами. Для обучения используется комбинация transforms.Compose:
- To Tensor: Преобразование исходных изображений в тензоры PyTorch.
- Normalize: Нормализация с параметрами
mean=0.5иstd=0.5.
Такая нормализация преследует две цели: ускорение сходимости модели и обеспечение численной устойчивости вычислений. После подготовки трансформаций создаются DataLoader для тренировочной (50 000 изображений) и тестовой (10 000 изображений) выборок. Использование загрузчиков данных позволяет разбить массивные датасеты на мини-батчи (по 128 элементов), что критически важно для работы в рамках ограничений оперативной памяти GPU. Также в процессе загрузки реализована возможность перемешивания (shuffling) тренировочных данных, что считается хорошим тоном для повышения качества обучения.
Разработка механизма эмбеддинга патчей 45:07
Для того чтобы трансформер «понимал» картинку, её необходимо представить как последовательность токенов, подобно тому как это делается с текстом в NLP. Для этого создается класс PatchEmbedding. В его основе лежит сверточный слой (nn.Conv2d), который «нарезает» изображение на патчи.
Особенности реализации:
- Свертка как сегментатор: Размер ядра (kernel size) и шаг (stride) устанавливаются равными
patch_size(в данном случае 4), что позволяет полностью покрыть изображение без перекрытий. - Классификационный токен (CLS Token): Обучаемый параметр, который добавляется к последовательности патчей для выполнения задачи классификации. Он инициализируется случайными весами с помощью
nn.Parameter. - Позиционное кодирование: Дополнительный обучаемый параметр, сохраняющий пространственную информацию, которая иначе была бы потеряна из-за архитектурных особенностей трансформера.
🏗️ Реализация ключевых компонентов архитектуры Vision Transformer 54:16
После того как базовая логика обработки входных данных и механизмов эмбеддинга патчей была настроена — о чем подробнее говорилось ранее в курсе, — следующим этапом стала разработка структурных блоков сети. Первым из них стал многослойный перцептрон (MLP), который играет роль ключевого вычислительного узла в каждом блоке трансформера.
Реализация блока MLP 54:16
Класс MultilayerPerceptron наследуется от nn.Module, что является стандартом для любого слоя в PyTorch. В методе инициализации (__init__) определяются два полносвязных (линейных) слоя: fc1 и fc2. Процесс обучения модели требует настройки параметров in_features и hidden_features, определяющих размерность данных на входе и промежуточном этапе.
Для повышения устойчивости модели к переобучению в блок добавлен слой Dropout. Он случайным образом обнуляет часть нейронов с заданной вероятностью drop_rate во время обучения. В методе forward данные проходят через следующую цепочку преобразований:
- Применение слоя
Dropout. - Линейная трансформация через
fc1. - Активация функцией GELU.
- Второй проход через
Dropoutи линейный слойfc2.
Такая конфигурация позволяет сети эффективно извлекать сложные признаки из эмбеддингов патчей.
Программирование слоя кодировщика (Transformer Encoder) 1:01:01
Сборка блока TransformerEncoderLayer — это объединение механизмов нормализации, внимания и MLP в единую структуру. Для стабильности глубокого обучения здесь критически важно использование LayerNorm, которая нормализует данные до и после основных операций внимания и MLP.
Основным компонентом блока является MultiheadAttention. При его инициализации важно выставить параметр batch_first=True, чтобы PyTorch корректно интерпретировал размерности входного тензора. В методе forward реализуется логика остаточных связей (residual connections): выходной тензор каждой операции складывается с исходными данными (x = x + ...). Это предотвращает проблему затухающих градиентов при обучении глубокой сети.
Объединение в класс VisionTransformer 1:05:52
Финальный этап — создание класса VisionTransformer, который агрегирует все модули в полноценную нейросеть. В его конструкторе инициализируются три основных компонента:
batch_embed: модуль, преобразующий изображение в последовательность векторов.encoder: последовательность из нескольких блоковTransformerEncoderLayer. Использованиеnn.Sequentialи списка в цикле позволяет динамически задавать глубину сети (depth).head: классификационная «голова» на основе линейного слоя, которая преобразует выходные признаки в логиты для заданного количества классов.
После сборки архитектуры происходит инстанцирование модели. При передаче параметров (таких как image_size, depth, num_heads) важно строго соблюдать их порядок, а также отправить модель на целевое устройство (CUDA) методом .to(device). Это завершает формирование архитектуры, готовой к этапу обучения.
🚀 Настройка процесса обучения: функции потерь, оптимизаторы и цикл обучения
После того как архитектура Vision Transformer была успешно инстанцирована, следующим критическим этапом становится определение инструментов для оптимизации модели. Ранее в разговоре они касались структуры датасета CIFAR-10 и принципов сборки модели.
Настройка функции потерь и оптимизатора 1:17:10
Для управления процессом обучения необходимо выбрать функцию потерь (loss function) и оптимизатор, который будет обновлять веса модели. В качестве критерия качества была выбрана кросс-энтропия (nn.CrossEntropyLoss), так как она является стандартом для задач многоклассовой классификации. Функция потерь измеряет «ошибочность» предсказаний, вычисляя разницу между прогнозом модели и реальными метками классов.
В качестве оптимизатора используется алгоритм Adam, который динамически подстраивает параметры обучения. Оптимизатору передаются параметры модели (model.parameters()) и заданный ранее коэффициент обучения (learning rate). Проверка конфигурации показывает, что для Adam по умолчанию заданы такие параметры, как AMSGrad (установлен в False) и betas. Основная задача этого компонента — минимизировать значение функции потерь путем итеративного обновления весов нейросети.
Создание функций обучения и валидации 1:19:00
Фундамент процесса обучения составляют две функции: train для корректировки весов и evaluate для контроля качества модели.
- Функция обучения (
train): Переводит модель в режимmodel.train(), который активирует слои, специфичные для обучения. Внутри цикла по батчам данных происходит перенос тензоров на целевое устройство (в данном случае — GPU/CUDA). Ключевые шаги включают: обнуление градиентов (optimizer.zero_grad), прямой проход (forward pass) для получения логитов, вычисление потерь, обратное распространение ошибки (loss.backward) для расчета градиентов и шаг оптимизатора (optimizer.step). - Функция оценки (
evaluate): Переводит модель в режимmodel.eval()и активирует контекстный менеджерtorch.inference_mode()для отключения вычисления градиентов, что экономит память и ускоряет процесс. Эта функция выполняет прямой проход для тестового набора, вычисляет предсказания черезargmaxи сравнивает их с истинными метками для подсчета итоговой точности.
Для корректной нормализации метрик в обеих функциях используется деление накопленных значений потерь и количества правильных ответов на размер датасета.
Запуск базового цикла обучения нейросети 1:30:53
Непосредственный запуск обучения осуществляется в цикле по количеству эпох (в данном случае выбрано 10). Для отслеживания прогресса используется библиотека tqdm, которая автоматически распознает среду Google Colab и выводит удобную полосу загрузки.
В каждой эпохе вызывается функция train для обучения на тренировочном наборе данных и evaluate для валидации на тестовом наборе. Результаты точности (accuracy) сохраняются в соответствующие списки для последующего анализа динамики обучения.
После завершения 10 эпох модель достигает следующих показателей:
- Точность на тренировочных данных: около 75% (при значении
train loss0.68). - Точность на тестовых данных: около 62%.
Графическое представление этих данных с помощью matplotlib демонстрирует, что точность стабильно растет, однако на определенном этапе кривая тестирования начинает выходить на плато. Это сигнализирует о необходимости дальнейшей настройки или применения методов повышения качества, что стало отправной точкой для следующего этапа работы над моделью.
🎨 Визуализация предсказаний на сетке изображений 1:40:30
Для наглядной оценки работы модели Vision Transformer (ViT) необходимо реализовать функцию визуализации, которая выводит сетку предсказаний. Процесс начинается с перевода модели в режим оценки (eval mode) для отключения специфических слоев, таких как Dropout, что критически важно для корректной инференции.
Сам процесс визуализации строится на использовании библиотеки matplotlib и создании сетки подграфиков (subplots), размер которой определяется заранее (например, 3x3). Внутри цикла, перебирающего позиции сетки, выполняются следующие шаги:
- Выбор данных: случайным образом выбирается индекс изображения из тестового набора данных.
- Подготовка тензора: изображение извлекается из датасета и приводится к формату, ожидаемому моделью. Поскольку PyTorch работает с батчами, необходимо использовать
unsqueeze(0), чтобы добавить размерность батча к тензору размером (3, 32, 32). - Инференция: с использованием контекстного менеджера
torch.inference_mode()модель делает предсказание, что позволяет ускорить вычисления за счет отключения механизмов обратного распространения ошибки. - Денормализация и вывод: перед визуализацией тензор необходимо «разонормализовать» (разделить на 2 и добавить 0.5), так как стандартные методы отрисовки некорректно обрабатывают отрицательные пиксели, нормализованные в процессе обучения. После этого изображение перемещается на CPU, преобразуется в массив NumPy и транспонируется для соответствия формату
matplotlib(высота, ширина, каналы).
Цветовая индикация результата — зеленая для верных предсказаний и красная для ошибочных — позволяет быстро оценить качество работы классификатора.
🔄 Внедрение методов аугментации данных Torchvision 1:52:09
После анализа базовой точности модели (около 62% на тестовом наборе) становится очевидным, что для повышения устойчивости и предотвращения переобучения необходимо внедрение методов аугментации. Библиотека torchvision.transforms предоставляет инструменты для трансформации изображений «на лету», что позволяет модели видеть более разнообразные варианты обучающих данных.
Для улучшения обобщающей способности ViT применяются следующие техники, объединенные в transforms.Compose:
- RandomCrop: случайное кадрирование изображения с добавлением отступов (
padding), что помогает модели фокусироваться на ключевых характеристиках объектов, таких как текстуры, границы и контуры, независимо от их точного расположения. - RandomHorizontalFlip: горизонтальный переворот, увеличивающий вариативность ракурсов объектов.
- ColorJitter: случайное изменение яркости, контрастности, насыщенности и цветового тона (hue), что делает модель менее чувствительной к освещению и цветовым искажениям исходных снимков.
Эти трансформации значительно повышают робастность сети, позволяя ей извлекать более надежные признаки из обучающего набора.
🚀 Повторное обучение на дополненных данных 1:58:41
После обновления конфигурации трансформаций модель необходимо обучить заново. Это требует сброса весов: поскольку после начального этапа модель уже содержит обученные параметры, необходимо заново инстанцировать класс VisionTransformer, чтобы начать процесс с «чистого листа».
Важно отметить, что гиперпараметры обучения, такие как функция потерь (CrossEntropyLoss), оптимизатор и скорость обучения, остаются идентичными базовому циклу. Разница заключается исключительно в подаче аугментированных данных в процессе обучения, что заставляет модель адаптироваться к более сложным условиям.
Результаты такого подхода демонстрируют заметный прогресс: после завершения обучения точность на тренировочной выборке достигла 76%, а на тестовой — 64% (против 62% ранее), при этом итоговое значение функции потерь также снизилось. Ранее в ходе работы рассматривались теоретические принципы и настройка базовых компонентов, но именно комбинация визуального контроля и грамотной аугментации данных позволяет довести качество классификации до приемлемых показателей.