Линейная регрессия является одним из фундаментальных инструментов анализа данных, позволяющим не только прогнозировать будущие результаты, но и математически обосновывать принимаемые решения. В своем видеоуроке создатель образовательного проекта StatQuest Джош Стармер на наглядных примерах объясняет суть этого метода и демонстрирует, как правильно оценивать точность прогнозов. Лектор подробно разбирает, почему при масштабировании бизнеса нельзя полагаться исключительно на интуицию и как концепции R-squared и P-value помогают вовремя остановиться и запросить дополнительные данные.
📊 Построение линии тренда и проблема математического описания остатков 0:52
Представьте гипотетическую ситуацию: руководство крупной торговой сети Spend and Save Food Stores ставит перед аналитиками задачу оценить целесообразность строительства трех новых магазинов. При этом босс требует не просто вынести вердикт, но и количественно оценить степень уверенности в принятом решении, чтобы понимать, можно ли начинать стройку немедленно или стоит подождать. Для решения подобных задач идеально подходит метод линейной регрессии, который Джош Стармер предлагает разобрать на упрощенном примере с тремя вымышленными компаниями, принадлежащими персонажам по имени Сквоч, Норм и Гамма-Монстр.
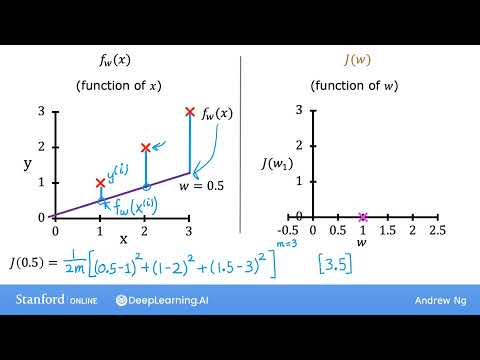
Собранные данные показывают общую закономерность: чем больше у компании точек, тем выше ее выручка. Однако этот тренд не является идеальным — например, компания Норма приносит больше дохода, хотя у нее меньше магазинов, чем у Гаммы. Чтобы использовать эту зависимость для прогнозирования, необходимо провести через имеющиеся точки прямую линию, но сделать это на глаз крайне сложно. Если провести линию строго через координаты Норма и Сквоча, то для Гаммы прогноз окажется совершенно неверным: реальная выручка составляет 7 единиц, а линия предсказывает 15,3. Любые другие попытки соединить две точки из трех вручную приводят к колоссальным погрешностям для оставшегося участника.
[Image of linear regression residuals]
Для выбора наилучшей прямой линии ученые используют объективный критерий, называемый суммой квадратов остатков (Sum of the Squared Residuals, SSR). Процесс вычислений строится на следующих правилах:
- Сначала для каждой точки рассчитывается остаток (residual) — разница между реальным наблюдаемым значением и значением, которое предсказывает линия.
- Остатки всегда измеряются параллельно оси Y, что позволяет сопоставлять наблюдаемую и предсказанную выручку для одного и того же количества магазинов на оси X.
- Простное сложение остатков не работает, так как положительные и отрицательные отклонения компенсируют друг друга, выдавая одинаковый итоговый результат для совершенно разных линий.
Чтобы избежать взаимного уничтожения отклонений, Джош Стармер указывает на необходимость сделать все значения положительными. Вместо функции модуля математики используют возведение остатков в квадрат, поскольку это существенно упрощает последующие вычисления производных. В результате для качественной синей линии сумма квадратов остатков составляет 33,25, тогда как для заведомо плохой черной линии она возрастает до 355,125, что наглядно доказывает преимущество первого варианта.
📉 Метод наименьших квадратов и поиск оптимальных параметров 9:40
Имея инструмент сравнения, можно перейти к поиску той единственной прямой, которая обеспечит минимально возможную сумму квадратов остатков для всего набора данных. Если зафиксировать угол наклона линии и начать постепенно изменять точку ее пересечения с осью Y (y-intercept), на графике зависимости SSR от этой величины начнет формироваться параболическая кривая. Сначала при увеличении координаты пересечения сумма квадратов остатков падает, что свидетельствует об улучшении точности, но после прохождения определенного оптимума SSR снова начинает расти.
Математическая суть линейной регрессии заключается в поиске самой нижней точки этой параболы, что достигается путем вычисления производной и приравнивания ее к нулю. Из этого уравнения выводится точная аналитическая формула для поиска оптимального пересечения с осью Y. Аналогичный шаг с вычислением производной применяется и для поиска идеального угла наклона (slope) линии.
Процесс подбора параметров линии имеет важные особенности:
- Данный математический метод называется методом наименьших квадратов (Least Squares).
- Современному аналитику не нужно заучивать эти сложные громоздкие формулы наизусть, так как компьютер выполняет все расчеты автоматически.
В рассматриваемом Джошем Стармером примере метод наименьших квадратов выдает оптимальные параметры: смещение по оси Y равное 3 и наклон 0,5. Полученное уравнение позволяет вернуться к вопросу руководителя сети магазинов Spend and Save Food Stores о расширении бизнеса. Если у компании уже есть 4 магазина и она планирует построить еще 3, аналитик подставляет итоговое число 7 в формулу и получает прогноз выручки в размере 6,5 единиц.
🎯 Квантификация точности прогноза с помощью коэффициента R-squared 16:03
Сам по себе точечный прогноз выручки мало что значит без понимания того, насколько ему можно доверять. Для полноценной квантификации уверенности необходимо оценить два независимых параметра: точность самого предсказания и вероятность того, что аналогичный результат мог быть получен по чистой случайности. Оценка точности производится путем сравнения суммы квадратов остатков регрессионной линии с суммой квадратов остатков относительно среднего арифметического значения выручки.
Джош Стармер объясняет, что среднее значение является базовым ориентиром, поскольку оно минимизирует сумму квадратов остатков в условиях, когда у нас вообще нет никакой информации о независимой переменной (количестве магазинов). Для сопоставления этих двух подходов используется коэффициент детерминации, известный как R-squared ($R^2$), который рассчитывается по следующему алгоритму:
- Из суммы квадратов остатков вокруг среднего значения вычитается сумма квадратов остатков вокруг регрессионной линии.
- Полученная разность делится на исходную сумму квадратов остатков вокруг среднего.
Для исходного датасета сумма квадратов остатков вокруг среднего составляет 45,5, а вокруг линии регрессии — 25,5, что в результате вычислений дает коэффициент $R^2$, равный 0,44. Этот показатель говорит о том, что учет количества магазинов позволил снизить общую ошибку прогноза на 44% по сравнению с использованием простого среднего значения.
Чтобы лучше понять природу коэффициента $R^2$, лектор приводит крайние примеры:
- Если регрессионная линия полностью совпадает со средним значением, коэффициент $R^2$ равен 0, что означает нулевую полезность модели для прогнозирования.
- Если все точки лежат строго на одной линии, остатки превращаются в ноль, и коэффициент $R^2$ становится равным 1,0, демонстрируя стопроцентное устранение неопределенности.
Поскольку шкала $R^2$ жестко ограничена диапазоном от 0 до 1, полученное значение 0,44 находится ровно посередине. Это означает, что модель работает заметно лучше, чем простое угадывание по среднему, но все еще оставляет огромные возможности для улучшения качества прогноза.
🎲 Борьба со случайностью: вычисление и интерпретация P-value 23:51
Высокий показатель точности модели может оказаться иллюзией, если данные были подобраны случайно. Джош Стармер наглядно демонстрирует эту проблему на примере выборки всего из двух точек: через любые две случайные точки всегда можно провести идеальную прямую линию с нулевыми остатками, из-за чего коэффициент $R^2$ автоматически станет равен 1,0. На этом основании автор подчеркивает, что сам по себе коэффициент детерминации не является самодостаточным инструментом, и в паре с ним всегда необходимо рассчитывать статистическую значимость — P-value.
Для простоты понимания концепции P-value (вместо разбора громоздких формул, зашитых в компьютерные программы) Стармер предлагает использовать метод симуляций и построения гистограмм случайного распределения. Если взять тысячи пар абсолютно случайных точек, построить для них линии регрессии и занести их показатели $R^2$ в общую гистограмму, то 100% из них покажут результат, равный единице. Сравнение нашей гипотетической модели из двух точек с этой гистограммой покажет, что вероятность получить $R^2 \ge 1$ на случайных данных равна 100%, то есть P-value составит 1,0, полностью обнуляя доверие к прогнозу.
В случае с реальным базовым датасетом из трех точек ситуация становится более показательной:
- Гистограмма, построенная на базе тысяч симуляций для трех случайных точек, отражает весь спектр возможных значений $R^2$.
- Математический анализ показывает, что в 53% случаев абсолютно случайные три точки дают коэффициент $R^2$ равный 0,44 или даже выше.
- Следовательно, P-value для исследуемой бизнес-модели составляет 0,53.
Такой высокий уровень P-value означает, что существует 53-процентная вероятность получить аналогичную или лучшую точность прогноза на абсолютно случайных данных. На основе этих вычислений Джош Стармер формулирует итоговый ответ для руководства торговой сети: несмотря на то, что модель предсказывает рост выручки до 6,5 единиц при открытии трех новых магазинов, математическая уверенность в этом результате ничтожно мала. Самым разумным решением в данной ситуации будет отложить дорогостоящее строительство и продолжить сбор статистических данных для построения более надежной регрессионной модели.