Революция в архитектуре Transformer: Анализ модели Synthesizer 0:01
Традиционный механизм Self-Attention, основанный на dot-product (скалярном произведении), долгое время считался «сердцем» моделей Transformer. Исследователи из Google Research в работе «Synthesizer: Rethinking Self-Attention in Transformer Models» поставили под сомнение незаменимость этого механизма, предложив альтернативные способы формирования весов внимания. Ведущий канала Yannic Kilcher разбирает, можно ли действительно исключить дорогостоящие операции скалярного произведения и как предложенный авторами подход меняет способ маршрутизации информации в нейронных сетях.
Механизм внимания: от классики к синтетике 2:22
В стандартном Transformer каждый токен последовательности генерирует три вектора: Query (запрос), Key (ключ) и Value (значение). Внимание между токенами вычисляется через скалярное произведение Query и Key, что позволяет динамически определять, какую информацию от других слов нужно «взять» для понимания контекста.
Что предлагает Synthesizer?
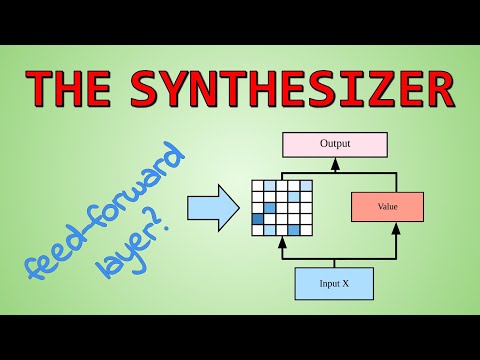
Авторы предлагают модель, которая учится генерировать веса внимания без взаимодействия «токен-токен».
- Dense Synthesizer: Каждый входной токен самостоятельно генерирует L-мерный вектор (где L — длина последовательности), определяющий распределение внимания. Решение принимается на основе позиции токена и его внутренних свойств, без оглядки на то, какие еще токены присутствуют в предложении. Для этого используется нейросеть с одним скрытым слоем и нелинейностью ReLU.
- Random Synthesizer: Более радикальный вариант, где веса внимания либо фиксированы и случайны, либо обучаются глобально, не завися от конкретных входных данных.
По мнению Yannic Kilcher, важно отметить, что архитектурно Random Synthesizer во многом напоминает обычный полносвязный (feedforward) слой, что вызывает вопросы о новизне подхода.
Результаты экспериментов: неоднозначный успех 25:40
Исследователи протестировали модель на задачах машинного перевода и моделирования языка. Yannic Kilcher отмечает, что машинный перевод является «благоприятной» средой для таких моделей, так как в нем часто присутствует закономерность: порядок слов в переводимых языках (например, немецком и английском) часто совпадает, что позволяет использовать глобальные паттерны маршрутизации.
- Производительность: Модели с механизмом Synthesizer показывают результаты, сопоставимые с классическими Transformer, но не всегда превосходят их [21:0, 30:18].
- Смешанные подходы: Комбинирование ванильного внимания (dot-product) и плотного синтезатора иногда дает лучшие метрики, но это неизбежно увеличивает количество параметров модели.
- Проблемы с обобщением: В задачах summarization (аннотирования) и генерации диалогов результаты оказались нестабильными: разные метрики (ROUGE-1, ROUGE-2, ROUGE-L) отдают предпочтение разным архитектурам.
Анализ «черного ящика» и критика методологии 42:08
В завершающей части работы авторы пытаются интерпретировать поведение модели, изучая распределение весов и влияние количества «голов» внимания (attention heads).
Однако Yannic Kilcher выражает скепсис по поводу глубины этого анализа:
- Отсутствие интерпретации: Авторы просто констатируют факты (например, изменение распределения весов), не объясняя, почему это происходит или что это значит для эффективности модели.
- Эффект параметров: Yannic Kilcher указывает, что во многих случаях улучшение результатов можно списать на простое увеличение количества обучаемых параметров, а не на качественное преимущество новой архитектуры.
Несмотря на критику, ведущий признает ценность самого подхода: задавать фундаментальные вопросы о том, как работают современные нейросети и действительно ли текущие стандарты являются оптимальными. Это «мышление вне коробки» — важный этап для развития глубокого обучения, даже если конкретная реализация Synthesizer оставляет пространство для дискуссий.



