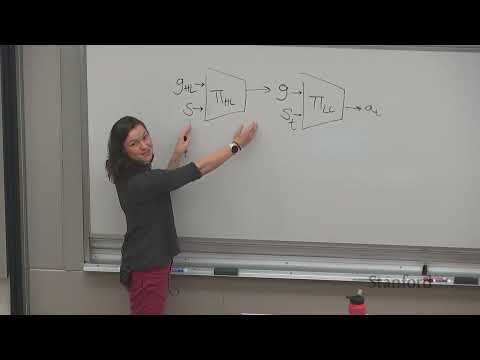На семинаре по робототехнике в Стэнфордском университете (Stanford Robotics Seminar ENGR319) ведущие исследователи представили концепцию «Пирамиды данных для манипуляций». В центре внимания — вопрос о том, как научить роботов выполнять сложные физические задачи, используя опыт людей, масштабные видеоданные из интернета и эффективное обучение с подкреплением.
🤖 Философия обучения: от младенцев до больших языковых моделей 0:10
По мнению спикера, современные роботы всё еще значительно уступают в ловкости даже годовалым детям или домашним животным . Ключевое отличие кроется в способности к «глубокой имитации» — возможности наблюдать за действиями со стороны (вид от третьего лица) и мгновенно воспроизводить их самостоятельно (вид от первого лица), адаптируя движения под собственную анатомию . В качестве примера приводится видео с собакой породы хаски, которая имитирует походку своего хозяина с травмированной ногой, перенося принцип движения с двух конечностей на четыре .
Другим важнейшим аспектом является «полировка» навыков. Спикер проводит аналогию с олимпийскими пловцами: можно часами смотреть видео их заплывов, но при первой попытке в бассейне новичок всё равно будет плавать плохо . Для достижения мастерства необходимо обучение с подкреплением (Reinforcement Learning, RL) непосредственно в физическом мире .
Эта концепция во многом повторяет путь развития больших языковых моделей (LLM):
- Предобучение (Pretraining): Чтение огромных массивов текста в интернете для понимания общих принципов.
- Обучение с подкреплением (RLHF): Практика (например, написание кода) и получение обратной связи для исправления ошибок и повышения точности .
🏗️ Пирамида данных для манипуляций 5:29
Для систематизации процесса обучения роботов была предложена трехуровневая структура — «Пирамида данных»:
- Нижний уровень: Масштабное предобучение. Обучение на огромном количестве данных из интернета (видео с людьми) или симуляций . Это закладывает априорные знания о мире.
- Средний уровень: Тонкая настройка под конкретное «тело» (Embodiment). Робот должен понять свои физические ограничения: длину манипулятора, грузоподъемность и диапазон движений .
- Верхний уровень: Обучение с подкреплением в реальном мире. Финальная стадия, позволяющая достичь сверхвысокой точности (например, попадание ниткой в игольное ушко) и надежности .
📹 Уровень 1: Извлечение знаний о движении из видео с YouTube 7:58
Главной проблемой существующих моделей (таких как Pi 0.5 от Physical Intelligence) спикер называет нехватку информации о динамике движений (motion level information) . Большинство интернет-данных статичны. Роботу же нужно знать, как именно брать чашку или наливать воду.
Исследовательская группа провела эксперимент по переносу знаний из человеческих видео на роботов:
- Метод: Сбор видео, где люди выполняют манипуляции, и извлечение ключевых точек рук. Эти движения переносились на морфологию робота .
- Данные: Смешивание данных телеуправления роботом и видео с людьми в единый массив для сквозного обучения .
- Результат: Модель, которая никогда не видела данных о выполнении конкретной задачи роботом (zero-shot), показала успех в 20% случаев .
Спикер признает, что 20% — это немного, но считает это прорывом, так как робот смог понять суть задачи (например, вытереть стол полотенцем или закрыть ноутбук) исключительно из наблюдений за людьми . Даже в случае неудач детальная оценка по «рубрикам» (начисление баллов за приближение к объекту, захват и т.д.) показала, что робот успешно осваивает траектории .
📈 Уровень 2: Закон масштабирования данных (Scaling Laws) 21:48
Второй проект исследователей был посвящен вопросу: сколько именно данных нужно собрать, чтобы робот эффективно работал в незнакомой среде? В ходе работы было собрано около 40 000 демонстраций и проведено более 15 000 тестов .
Ключевые выводы о масштабировании (Data Scaling Laws):
- Разнообразие важнее количества: Для обобщения навыков гораздо эффективнее собрать данные в 32 различных локациях с разными объектами, чем записать тысячи повторений в одной лаборатории .
- Точка насыщения: Если данных из одной среды становится слишком много, прирост производительности замедляется (плато) .
- Оптимальная схема: Исследователи выяснили, что для запуска нового навыка в дикой природе (например, вытаскивание зарядки из розетки) достаточно около 1 600 демонстраций, распределенных по 32 локациям (по 50 на каждую) . Это позволяет достичь успеха в 80–90% случаев всего за один день сбора данных .
⚡ Уровень 3: Эффективное RL с «фундаментальными априори» 38:30
Обучение с подкреплением обычно требует миллионов итераций, что невозможно в реальности. Однако люди учатся быстро, так как у них есть «априорные знания» (priors). Команда спикера предложила метод Reinforcement Learning with Foundation Priors .
Метод использует три типа внешних сигналов для ускорения RL:
- Policy Prior (Априорная политика): Базовые знания о том, как двигаться, полученные на предыдущих этапах пирамиды .
- Value Prior (Априорная ценность): Оценка того, насколько робот близок к цели. Для этого используется модель VIP (Value Implicit Pretraining), обученная на видео с людьми .
- Success Reward (Сигнал успеха): Определение факта выполнения задачи с помощью GPT-4 .
Этот подход позволил обучать роботов сложным навыкам (наливание воды из чайника, открывание ящиков, игра в мини-гольф) всего за 60 минут реального времени . Процесс происходит полностью автономно: робот пробует, корректирует движения на основе «памяти мышц» и постепенно достигает успеха без ручного проектирования функций вознаграждения .
❓ Вопросы и ответы 50:03
В ходе дискуссии были затронуты следующие темы:
- Генеративное видео (Sora): Спикер полагает, что в будущем сгенерированные видео от OpenAI Sora или аналогичных моделей смогут заменить YouTube в качестве источника данных для предобучения роботов .
- Человек в цикле (Dagger): Хотя помощь человека полезна, конечная цель — заставить робота обучаться самостоятельно, решая задачи сброса среды (reset) и обеспечения безопасности автономно .
- Ошибки оборудования: Около 70% неудач на этапе предобучения связаны с невозможностью выполнить деликатные манипуляции (захват), тогда как навигация манипулятора к цели (грубое движение) работает гораздо лучше . Спикер считает, что это отчасти вызвано ограничениями механических захватов (низкая степень свободы) .