RLHF
61 статей
 32 мин
32 мин🧠 Looking Glass Universe: «Почему нейросети становятся манипуляторами?»
🛠 Кайл Корбитт из CoreWeave: «Мы уже находимся в петле рекурсивного самосовершенствования ИИ»
 1ч 19м
1ч 19м🤖 Как устроены современные языковые модели: от обучения до системных ограничений
 1ч 17м
1ч 17м🧠 Джейкоб Андреас: «Как современные языковые модели учатся рассуждать»
 35 мин
35 мин🧠 Уэс Рот: как «документ души» и Конституция формируют характер Claude
 1ч 25м
1ч 25м📉 Мэтт Фитцпатрик: «Внутренние ИИ-команды корпораций в два раза менее эффективны»
1ч 25м📉 Мэтт Фицпатрик: «Внутренние ИИ-проекты корпораций обречены на провал в 95% случаев»
 1ч 10м
1ч 10м🎯 Профессор Стэнфорда разобрал ключевые вызовы и методологию исследований Deep RL
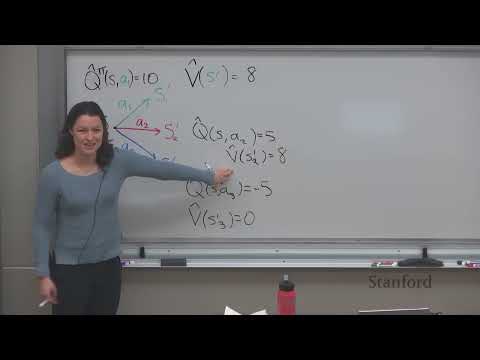 1ч 05м
1ч 05м🔄 Лекция Стэнфорда о Reward Learning: как научить искусственный интеллект понимать человеческие цели
 1ч 02м
1ч 02м🚀 Преподаватель Стэнфорда о методах обучения языковых моделей: от RLHF к DPO
 1ч 47м
1ч 47м🛠 Тюнинг LLM: как методы PPO и DPO превращают нейросети из автодополнителей в полезных помощников
1ч 47м🎯 Стэнфорд: «Ваша языковая модель — это на самом деле скрытая модель вознаграждения»
 1ч 44м
1ч 44м🎮 От Atari до ChatGPT: как ИИ учится на своих ошибках?
 1ч 22м
1ч 22м📊 Чип Хьюен: как создавать ИИ-продукты, которые действительно работают
 31 мин
31 мин🤖 Айзек Артур: «Проблема выравнивания ИИ — это попытка научить джинна понимать намерения»
 1ч 16м
1ч 16м📚 Обучение ИИ на человеческих предпочтениях: лекция Сэми Куа в Стэнфорде
 19 мин
19 мин🎓 Почему нейросети галлюцинируют? OpenAI нашла решение проблемы «уверенной лжи»
 1ч 42м
1ч 42м🌪 Эпоха фабрик данных: как CEO Labelbox строит конвейер для обучения AGI с экспертами на $250k в год
 1ч 16м
1ч 16мМеханика обучения моделей: лектор Стэнфорда о GRPO
 41 мин
41 мин⚖ Инженерная оптимизация: как математика помогает выбирать между безопасностью и скоростью
 1ч 20м
1ч 20м🚀 Stanford CS336: секреты обучения reasoning-моделей DeepSeek-R1, Kimi и Qwen
 1ч 14м
1ч 14м🔄 Как устроен посттренинг языковых моделей: от SFT до RLHF
 50 мин
50 мин🚀 13 инженеров против OpenAI: как удержать миллионы пользователей ИИ
 58 мин
58 минГенеративный ИИ в медицине: как работают большие языковые модели
 1ч 23м
1ч 23м🧠 Макс Бартоло из Cohere: почему человеческая обратная связь — это не золотой стандарт для ИИ
 1ч 08м
1ч 08м🧬 Нейтан Ламберт о жизни после DPO: почему PPO все еще лучше, но сложнее
 1ч 19м
1ч 19м📈 Пост-обучение больших языковых моделей: от контекстного промптинга до алгоритмов RLHF и DPO
1ч 19м🤖 Арчит Шарма о будущем LLM: как обучают ChatGPT?
 1ч 54м
1ч 54м🧠 Тан Чжи Сюань: «ИИ не должен просто угадывать наши желания — он должен соблюдать социальные нормы»
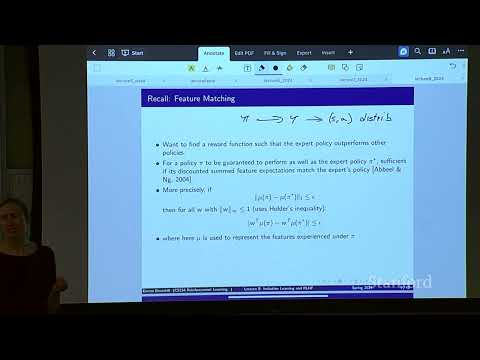 1ч 13м
1ч 13м🔄 От симуляции такси до ChatGPT: как максимизация энтропии и отзывы людей обучают современный ИИ
 1ч 18м
1ч 18м📉 Direct Preference Optimization: почему исследователи переходят на DPO
1ч 18м🎓 Как аналитический метод DPO изменил выравнивание LLM и столкнулся со взломом наград
 3ч 11м
3ч 11м🧠 Цифровой паноптикум: почему ИИ выберет бунт вместо рабства
 1ч 44м
1ч 44м🏗 Ян Дюбуа о создании LLM: почему данные и системы важнее архитектуры
 3ч 09м
3ч 09м🤖 Как RLHF превращает текстовые симуляторы в опасных агентов
 46 мин
46 мин🕶 Натан Лабенц: «Мы как 13-летние подростки с ключами от ИИ-суперкара»
 1ч 16м
1ч 16м🏗 Натан Ламберт: «RLHF — это необходимый инструмент выравнивания ИИ»
 1ч 33м
1ч 33м🧩 Брэндон Рорер: «ИИ — это всего лишь очень умная машина для перемалывания паттернов»
 1ч 31м
1ч 31м🛢 Основатель Scale AI Александр Ванг о будущем данных, геополитике ИИ и уроках Amazon
 52 мин
52 мин🧠 Райли Гудсайд о промпт-инжиниринге: «Модели не думают, они фристайлят»
 25 мин
25 мин🧠 Мира Мурати о ChatGPT: «Это началось как исследование безопасности, а не продукт»
 37 мин
37 мин🧠 Гокул Свами: «Многие маршруты в Google Maps рассчитываются через инверсное обучение с подкреплением»
 1ч 03м
1ч 03м🛠 Скотт Даунс: «Мы даем тренерам ИИ костюмы Железного человека»
 1ч 25м
1ч 25м🧠 Вивек Натараджан о Med-PaLM: «Медицина требует специализации ИИ»
 1ч 21м
1ч 21м🏗 Раза Хабиб о внедрении AI: почему RLHF переоценен
 1ч 22м
1ч 22м🧠 Нейтан Лабенц о GPT-4: «Это аморальный и опасный „алиен“»
 10 мин
10 мин🐙 Кеннет Стенли: «RLHF — это наклеивание смайлика на хаос интернета»
 2ч 23м
2ч 23м🚀 Сэм Альтман: Почему ИИ — это инструмент, а не существо
 1ч 23м
1ч 23м🚀 Итоги релиза GPT-4: эксперты обсуждают капчи, биологическое оружие и гонку с Китаем
 40 мин
40 мин🧠 Шон Прессер: «Остановить развитие ИИ уже невозможно»
 34 мин
34 мин📉 Технический разбор GPT-4: скрытые параметры, законы масштабирования и риски для бизнеса
 20 мин
20 мин🧠 Раза Хабиб: «В долгосрочной перспективе программисты будут автоматизированы первыми»
 1ч 01м
1ч 01мЭдвард Грефенстетт о семантике, ИИ и философии
 35 мин
35 мин🌐 Янник Килчер запустил платформу OpenAssistant для создания открытого аналога ChatGPT
 1ч 57м
1ч 57м🧠 Самир Сингх: «Языковые модели — это искусные имитаторы»
 1ч 07м
1ч 07м🤖 Сергей Левин об эволюции обучения с подкреплением: от «бандитов» в ChatGPT до роботов-трансформеров
 51 мин
51 мин🛠 Сара Хукер: «Качественные аннотации важнее алгоритмов подкрепления в RLHF»
 31 мин
31 мин🛠 Янник Килчер о ChatGPT: «Джейлбрейки в мире дистопии»
 27 мин
27 мин🗣 Лора Руис о коммуникации ИИ: «Модели не способны общаться в режиме zero-shot»
 20 мин
20 мин🌐 Как ИИ меняет лингвистику: спор Эндрю Лампинена с Ноамом Хомским на NeurIPS
