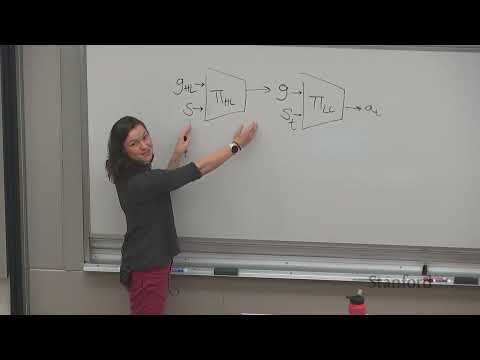
В рамках курса Stanford CS224R по глубокому обучению с подкреплением (Deep Reinforcement Learning) пятнадцатая лекция была посвящена одной из самых сложных проблем в робототехнике и ИИ — решению задач с длинным горизонтом планирования. Инструктор подробно разобрал, почему традиционные «плоские» (flat) нейросетевые политики пасуют перед сложными последовательностями действий и как иерархический подход позволяет имитировать человеческое планирование.
🏗️ Проблема длинного горизонта и суть иерархии 0:05
Задачи с длинным горизонтом — это процессы, состоящие из множества взаимозависимых этапов, такие как приготовление еды, ремонт программного кода или автономное вождение на большие расстояния . По мнению лектора, главная сложность здесь заключается в огромном распределении состояний, которые должен посетить агент. Любая ошибка на раннем этапе может стать фатальной, а отсутствие прогресса часто приводит к «зацикливанию» политики в одном и том же состоянии .
Иерархическое обучение с подкреплением (HRL) предлагает разбить одну сложную задачу на несколько уровней:
- Высокоуровневая политика (High-level policy, $\pi_{HL}$): Анализирует текущее состояние и ставит промежуточную цель или подзадачу (например, «купить ингредиенты») .
- Низкоуровневая политика (Low-level policy, $\pi_{LL}$): Выполняет конкретные атомарные действия для достижения этой цели (например, «сократить мышцу», «сделать шаг») .
Ключевое различие между ними — частота работы. Если низкоуровневая политика может работать на частоте 20 Гц (управление моторами робота) или пословно (в LLM), то высокоуровневая политика принимает решения гораздо реже — на уровне завершенных этапов или абзацев текста .
🧠 Почему иерархия эффективнее обычных моделей? 12:39
Лектор выделяет несколько фундаментальных преимуществ иерархического подхода перед стандартными «плоскими» политиками:
- Промежуточный надзор (Intermediate Supervision): Вместо того чтобы ждать редкой награды в самом конце (например, когда торт уже испечен), система получает сигналы за выполнение подзадач («нашел кастрюлю», «вскипятил воду») .
- Обмен знаниями: Низкоуровневая политика может использовать опыт, полученный в одной подзадаче, для ускорения обучения в другой, если они имеют схожую структуру .
- Структурированное исследование (Exploration): В RL-задачах агент исследует мир не на уровне случайных движений «джойстиком», а на уровне логичных высокоуровневых целей .
- Вычислительная эффективность: Сложные рассуждения (reasoning) происходят на низкой частоте, что экономит ресурсы .
В качестве альтернативы иерархии лектор упоминает метод «цепочки рассуждений» (Chain of Thought), где модель сначала проговаривает цель, а затем выполняет действие . Однако, по словам инструктора, эмпирических доказательств превосходства этого метода над чистой иерархией в робототехнике пока недостаточно .
🛠️ Дизайн-решения: Представление целей и выбор абстракций 19:27
Выбор того, как именно кодировать промежуточные цели, критически зависит от домена. В ходе лекции были рассмотрены следующие варианты:
- Координаты GPS: Для задач навигации на велосипеде или роботе-курьере .
- Естественный язык: Строки типа «разбей яйца» или «открой шкаф» — наиболее гибкий и выразительный способ .
- Изображения: Визуальные целевые состояния (как должен выглядеть результат этапа) .
Инструктор подчеркивает, что важно выбрать правильный уровень абстракции. Цель «нажми на педаль с силой X» слишком детализирована для верхнего уровня, а «стань лучшим поваром» — слишком абстрактна для управления манипулятором .
📉 Проблема «стыковки» уровней и надзор 25:52
Одной из самых острых проблем HRL является несогласованность уровней. Если обучать высокоуровневую и низкоуровневую политики отдельно, возникает «разрыв» в распределении состояний .
Например, если низкоуровневый навык «поиск пасты» обучался только из состояния «стоя у плиты», а высокоуровневая политика привела робота в состояние «стоя у холодильника», система сломается . По мнению лектора, для стабильной работы необходимо:
- Обеспечивать перекрытие (buffer) между состояниями разных навыков .
- Проводить совместную адаптацию уровней, чтобы они «подстраивались» под возможности и ошибки друг друга .
⏱️ Когда пора менять цель? 38:47
Существует два основных подхода к тому, когда высокоуровневая политика должна выдавать новую команду:
- По завершении (On completion): Низкоуровневая модель сама предсказывает индикатор успеха или прогресса . Это эффективно, но опасно: если классификатор успеха ошибется и решит, что задача не выполнена (хотя это не так), агент застрянет навсегда .
- Фиксированный интервал (Fixed timesteps): Пересмотр целей происходит каждые $N$ шагов (например, раз в секунду) .
Инструктор отмечает, что, несмотря на некоторую вычислительную избыточность, второй вариант (фиксированный интервал) чаще используется на практике, так как ошибки в нем менее фатальны для выполнения задачи .
🤖 Практические примеры систем: От текста до диффузии 45:17
Лектор разобрал несколько современных архитектур, представленных за последние несколько месяцев.
Иерархическое подражание с языковыми целями
В этом подходе демонстрации человека сегментируются и размечаются текстовыми метками («взял пакет», «насыпал M&Ms») . Для улучшения системы используется алгоритм DAgger (Dataset Aggregation) в пространстве языка. Инструктор показал пример, где оператор голосом корректирует высокоуровневую политику в реальном времени, если видит, что робот вот-вот совершит ошибку . Согласно приведенным данным, использование иерархии дает 34% прирост эффективности в задачах с длинным горизонтом по сравнению с плоскими моделями .
Изображения как цели и диффузионные модели 55:52
Вместо слов высокоуровневая политика может генерировать изображение будущего состояния (Goal Image) . Здесь используются генеративные модели (например, Diffusion models), которые «дорисовывают» текущую сцену до желаемого результата . Преимущество этого метода в том, что для обучения можно использовать неразмеченные видео из YouTube — модель учится понимать динамику мира, наблюдая за людьми .
Обучение с подкреплением и «релейблинг» 1:05:16
В классическом RL иерархия часто реализуется через Hindsight Relabeling (переименование целей задним числом). Если агент не достиг поставленной цели, но достиг чего-то другого, мы делаем вид, что именно это и было его целью . Это позволяет эффективно обучаться даже при очень редких наградах. Также ведутся активные исследования в области автоматического обнаружения навыков (Skill Discovery) без участия человека, однако их масштабирование на сложные задачи остается открытым вопросом .



