В новом выпуске ML News ведущий Янник Кильхер разбирает громкий камбэк сверточных нейросетей с архитектурой ConvNeXt, которая бросает вызов доминированию трансформеров в компьютерном зрении. Также в центре внимания — новые жесткие правила регулирования рекомендательных алгоритмов в Китае, критический разбор исследования «мужского взгляда» в алгоритмах обрезки фото и запуск гипермодальной модели rudolph от Sber AI.
🚀 Реванш сверточных сетей: Meta представляет ConvNeXt 0:25
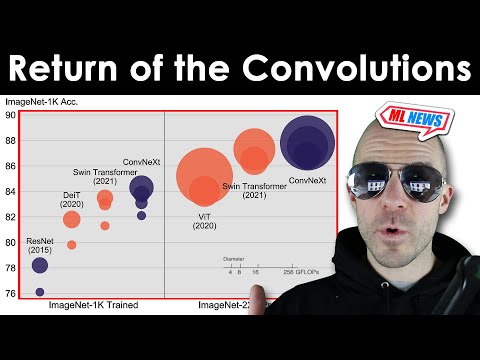
Исследователи из Meta (бывшая Facebook Research) опубликовали работу под названием «A ConvNet for the 2020s», в которой оспаривают мнение о том, что трансформеры полностью вытеснили сверточные сети (convnets) в задачах компьютерного зрения . Авторы утверждают, что превосходство архитектур типа Vision Transformer (ViT) обусловлено не столько механизмом внимания, сколько набором мелких архитектурных улучшений и методик обучения.
В ходе исследования архитектура классического ResNet была систематически модернизирована с применением лучших практик из трансформеров. Результатом стала сеть ConvNeXt, которая показывает результаты на уровне или выше Vision Transformers на датасетах ImageNet-1K и ImageNet-22K .
Однако в сообществе эта работа вызвала дискуссии:
- Лукас Байер отметил, что при правильном обучении ViT с использованием современных аугментаций преимущество ConvNeXt становится минимальным .
- Росс Уайтман, создатель библиотеки
timm, указал, что если «правильно» обучить стандартный ResNet, его точность поднимется до отметки 82%, что приближает его к младшим версиям ConvNeXt . - Миншин Тан дополнил сравнение данными модели EfficientNet v2, которая по-прежнему сохраняет конкурентоспособность на ImageNet .
По мнению Янника Кильхера, гонка архитектур в компьютерном зрении все еще открыта. Ведущий полагает, что результат может зависеть не от фундаментальных инноваций, а от количества параметров и правильности реализации стандартных приемов, либо же «ультимативная» архитектура зрения еще просто не найдена .
📸 Алгоритмы обрезки фото и «мужской взгляд»: критика методологии 2:53
Янник Кильхер разобрал исследование «Auditing saliency cropping algorithms», посвященное алгоритмам автоматической обрезки изображений в Twitter, Google и Apple . Эти системы определяют наиболее значимые (салиентные) области фото, чтобы подогнать их под формат ленты новостей.
Ранее алгоритмы Twitter критиковали за предвзятость: пользователи утверждали, что нейросети отдают предпочтение светлым тонам кожи и якобы фокусируются на телах женщин, игнорируя лица. Авторы статьи решили проверить гипотезу о «мужском взгляде» (male gaze) — концепции, согласно которой продукты и медиа создаются с позиции мужского восприятия, объективирующего женщин .
Основные выводы и критика исследования:
- Исследователи собрали датасет с фотографиями женщин на красных дорожках и подиумах .
- Выяснилось, что когда алгоритм не фокусировался на лице, он чаще всего выбирал корпоративные логотипы на заднем плане, которые находились не на уровне головы .
- Несмотря на то, что прямой связи с «объективацией» обнаружено не было, авторы статьи назвали эти артефакты «эффектами, подобными мужскому взгляду» (male gaze-like effects) .
По мнению Янника Кильхера, авторы статьи были изначально настроены найти подтверждение своей идеологической гипотезе . Он утверждает, что если бы данные не позволили сделать такие выводы, авторы могли бы «спрятаться» за методологией, а при продвижении работы в соцсетях использовать громкие заголовки. Янник Кильхер считает такой подход политически мотивированным и подчеркивает, что если бы алгоритм действительно фокусировался на интимных частях тела, тон статьи был бы совершенно иным .
🇨🇳 Китай против алгоритмической зависимости: новые правила для IT-гигантов 11:42
В Китае вступили в силу новые правила регулирования алгоритмов рекомендаций, которые напрямую затрагивают бизнес-модели техгигантов . Согласно документу, поставщики алгоритмов обязаны:
- Проактивно распространять «положительную энергию» .
- Предотвращать чрезмерные траты пользователей и бороться с развитием игровой или контентной зависимости .
- Предоставить пользователям возможность полностью отказаться от рекомендательных сервисов (opt-out) .
Янник Кильхер отмечает, что хотя некоторые эксперты считают влияние этих правил ограниченным (поскольку функция отключения может быть запрятана глубоко в настройках), само наличие выбора — позитивный шаг . По словам ведущего, он предпочел бы иметь возможность отключить алгоритм в меню, чем постоянно сталкиваться с раздражающими баннерами о приеме cookie-файлов на каждом сайте .
🗣 Технологии синтеза: голос на любом языке и оцифровка музыки 9:40
В блоке технических новинок Янник Кильхер выделил два проекта:
- yourTTS: система Text-to-Speech с возможностью zero-shot обучения. Она позволяет переносить голос говорящего на другие языки, на которых он не разговаривает . Ведущий продемонстрировал работу модели, синтезировав свою речь на французском языке, и отметил высокое качество и скорость работы .
- MT3: проект от Google Magenta для многозадачной транскрипции музыки . Система способна преобразовывать аудиозапись с несколькими инструментами в многодорожечный MIDI-файл. Хотя звучание MIDI отличается от оригинала, модель успешно разделяет параллельные треки разных инструментов .
🛠 Инструментарий ML-инженера и образовательные ресурсы 12:58
Янник Кильхер представил подборку полезных ресурсов для сообщества:
- Deep Learning Interviews: книга (PDF на 360+ страниц) с сотнями решенных задач для подготовки к собеседованиям в области ИИ .
- Deepchecks: фреймворк для юнит-тестирования моделей машинного обучения и проверки данных .
- DagsHub: платформа для версионирования данных, моделей и экспериментов, предлагающая опыт, схожий с GitHub, включая интеграцию разметки данных .
- Rumble: open-source база данных на базе Apache Spark для эффективной обработки неоднородных JSON-данных с помощью специального языка запросов .
- JAX Models: неофициальный репозиторий с реализациями глубокого обучения на JAX .
🤖 Гипермодальный трансформер rudolph от Sber AI 16:44
Команда Sber AI представила модель rudolph (Hyper-modal Transformer) . В отличие от классических мультимодальных систем, rudolph включает в себя сразу несколько компонентов:
- Генерация изображения по тексту (аналог DALL-E).
- Генерация текста по изображению (image-to-text).
Благодаря такой структуре модель способна выполнять задачи визуального ответа на вопросы (VQA), абстрактного логического рассуждения и проверки совместимости изображений и текста (как CLIP) . Для токенизации изображений используется VQGAN, после чего данные обрабатываются как последовательность токенов. Код и веса компактных версий модели уже доступны в открытом доступе .
Завершая выпуск, Янник упомянул годовой отчет Джеффа Дина из Google Research, где выделены 5 ключевых трендов ИИ 2021 года, включая создание более эффективных и универсальных моделей общего назначения .