В данном материале представлен подробный разбор научной статьи исследователей из Microsoft, посвященной новой архитектуре языковых моделей DeBERTa. Популярный AI-блогер Янник Килчер анализирует, как разделение содержательной и позиционной информации, а также улучшенный декодер позволяют превзойти классические модели BERT и RoBERTa. Модель демонстрирует выдающиеся результаты на различных задачах обработки естественного языка и уже доступна для практического использования.
🧠 Новая архитектура на базе BERT и RoBERTa 0:01
Исследователи из Microsoft (Peng Cheng, Xiaodong Liu, Jianfeng Gao и Weizhu Chen) представили модель DeBERTa (Decoding-enhanced BERT with Disentangled Attention). Архитектура призвана существенно улучшить существующие подходы BERT и RoBERTa с помощью двух ключевых нововведений: раздельного внимания (disentangled attention) и расширенного декодера маскированных токенов (enhanced masked decoder). Модель уже доступна в библиотеке Hugging Face для интеграции в любые NLP-задачи.
В процессе разбора Янник Килчер обращается к своей аудитории с просьбой оценить его новую студию звукозаписи и оставить комментарии, подчеркивая, что до сих пор читает все отзывы лично.
🛠️ Проблема стандартного механизма внимания 2:40
Стандартный многоголовый механизм внимания (Multi-Head Attention) работает как алгоритм мягкой маршрутизации информации между токенами с помощью векторов запросов (queries), ключей (keys) и значений (values). Однако сам по себе этот механизм не способен определять порядок слов в предложении. Без дополнительных модификаций модель воспринимает текст как «мешок слов» (bag of words), не видя разницы между утверждением «I am hungry» и вопросом «Am I hungry».
Для решения этой проблемы в трансформерах традиционно используются два типа эмбеддингов, извлекаемых из специальных обучаемых таблиц:
- Векторы содержимого слов (word vectors), уникальные для каждого токена из словаря.
- Векторы абсолютных позиций (position encodings), привязанные к порядковому номеру слова в предложении.
Существует два основных способа объединения этих векторов перед подачей в слои внимания:
- Конкатенация (склеивание), которая существенно увеличивает размерность данных и вычислительную нагрузку.
- Поэлементное сложение (element-wise addition), являющееся наиболее популярным компромиссом.
Авторы статьи про DeBERTa утверждают, что стандартное сложение не является идеальным, поскольку позиционные сигналы слишком сильно смешиваются с содержательными. Их цель — полностью разделить эти потоки информации, чтобы сеть могла параллельно рассуждать о семантике слов и об их взаимном расположении.
📐 Раздельное внимание (Disentangled Attention) 10:47
В классическом BERT каждый элемент последовательности генерирует один ключ и один запрос, в которых смешаны семантика и позиция. В DeBERTa каждый токен представляется двумя раздельными векторами: вектором контента $h$ и вектором относительной позиции $p$. Соответственно, вычисление внимания между токенами $i$ и $j$ математически раскладывается на четыре типа взаимодействия:
- Содержимое со значением (content-to-content) — классическое семантическое внимание.
- Содержимое с позицией (content-to-position) — когда слово запрашивает информацию о контексте вокруг себя.
- Позиция с содержимым (position-to-content) — когда позиция токена определяет, какую семантическую информацию нужно собрать у соседей.
- Позиция с позицией (position-to-position) — взаимодействие позиций между собой.
Поскольку модель использует относительные координаты, взаимодействие «позиция-позиция» оказывается одинаковым для всех токенов и не несет полезной уникальной информации. Авторы DeBERTa решили полностью исключить этот четвертый компонент, формируя итоговую матрицу внимания как сумму первых трех составляющих.
Важной особенностью архитектуры является то, что вектор семантики $h$ трансформируется от слоя к слою ($h_0 \to h_1 \to h_2$), тогда как позиционная матрица $p$ остается неизменной и подается «свежей» на каждый слой трансформера. Янник Килчер высказывает определенный скептицизм по поводу «чистоты» этого разделения: по его мнению, уже после первого слоя семантический вектор $h$ неизбежно впитывает в себя позиционную информацию через механизмы кросс-внимания. Тем не менее, постоянная подпитка позиционными данными на каждом слое дает модели серьезное преимущество.
⏱️ Относительное кодирование и эффективная реализация 25:54
Относительное позиционирование означает, что система координат центрируется вокруг каждого токена индивидуально. Для условного центрального слова позиции соседей выглядят как последовательность относительных сдвигов, например $[-2, -1, 0, 1, 2]$.
Для оптимизации вычислений авторы используют два приема:
- Усечение окна контекста (truncation): вводится максимальная дистанция (например, $\kappa = 2$). Все токены за пределами этого окна получают фиксированный граничный вектор относительной позиции.
- Эффективный алгоритм матричного умножения: вместо дорогостоящего расчета относительных позиций для каждого токена по отдельности выполняется одно большое умножение матриц, из которого затем выбираются нужные элементы.
🧩 Ограничения относительных позиций и маскирование 28:43
Несмотря на преимущества относительного кодирования, авторы выявили фундаментальную проблему при обучении модели методом маскирования токенов (Masked Language Modeling). Янник Килчер приводит пример из статьи со следующим предложением: «A new store opened beside a new mall» («Новый магазин открылся рядом с новым торговым центром»).
Если замаскировать слова «store» и «mall», локальный контекст для обоих случаев окажется идентичным — оба слова идут сразу после прилагательного «new» с относительной позицией $+1$. Использования только относительных координат и окружающих слов становится недостаточно, чтобы модель могла различить, где должен быть магазин, а где торговый центр. Для полноценного понимания структуры предложения языковой модели все же требуются абсолютные позиции.
🚀 Расширенный декодер (Enhanced Masked Decoder) 31:48
В то время как классический BERT внедряет абсолютные позиции на самом первом, входном слое, создатели DeBERTa поступают иначе: они интегрируют абсолютные позиционные эмбеддинги в самом конце, после всех слоев трансформера, но непосредственно перед слоем softmax для предсказания замаскированных слов. Этот компонент получил название Enhanced Masked Decoder (EMD).
Эксперименты показывают, что подача абсолютных координат в конце работает значительно эффективнее. Авторы предполагают, что раннее добавление абсолютных позиций мешает трансформеру эффективно обучаться относительным паттернам.
Янник Килчер подробно разбирает этот шаг и признается, что не является сторонником подобного искусственного ограничения емкости модели. По мнению ведущего, если нейросеть обучается правильно, она должна уметь эффективно использовать абсолютные позиции с самого начала, не требуя их переноса в финал. Тем не менее, Янник отмечает, что в глубоком обучении любые теоретические сомнения аннулируются итоговым результатом, который у DeBERTa оказался превосходным.
📈 Трюки масштабирования, SiFT и результаты тестов 38:04
Помимо архитектурных изменений, в DeBERTa применяется метод SiFT (Scale-invariant Fine-Tuning) — масштабно-инвариантная тонкая настройка, использующая элементы виртуального состязательного обучения (virtual adversarial training) и нормализацию эмбеддингов перед апдейтом, что существенно помогает при адаптации модели под конкретные NLP-задачи.
В статье приводится исследование вклада отдельных компонентов (ablation study), показавшее следующие результаты:
- Удаление расширенного декодера (EMD) или любого из двух кросс-компонентов раздельного внимания (content-to-position / position-to-content) приводит к снижению точности на различных бенчмарках.
- Наилучший результат достигается исключительно при комбинации всех заявленных методов.
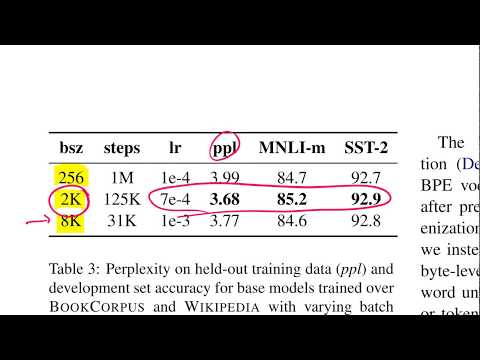
- DeBERTa значительно опережает RoBERTa по скорости сходимости, требуя меньше шагов предварительного обучения для достижения аналогичной точности.
При масштабировании архитектуры авторы применили оптимизационный трюк — совместное использование (sharing) проекционных матриц для относительных позиционных эмбеддингов и контента. Янник Килчер проводит математический анализ этого шага на доске и указывает, что при слиянии этих матриц формула внимания начинает сильно напоминать классический механизм с простым сложением векторов, за исключением кросс-компонентов. Ведущий задается вопросом, насколько критично само «разделение» представлений по сравнению с банальным фактом доступности позиционной информации на каждом слое сети.
Визуализация матриц внимания в конце статьи наглядно демонстрирует, что DeBERTa, в отличие от RoBERTa, формирует более четкие диагональные (локальные) паттерны внимания и реже полагается на размытые глобальные связи, за исключением специального токена CLS. Янник резюмирует, что DeBERTa представляет собой крайне эффективный и заслуживающий внимания алгоритм для построения современных SOTA-моделей.