Эффективность в условиях дефицита: EfficientZero меняет правила игры в Atari 0:00
Исследователи представили модель EfficientZero, способную достигать высокого уровня мастерства в играх Atari при критически ограниченных объемах данных. Автором этой работы выступила группа ученых (Liu, Kurotouch, Pietrabil, Gao), сосредоточившаяся на преодолении барьеров, с которыми сталкиваются современные алгоритмы обучения с подкреплением (Reinforcement Learning, RL).
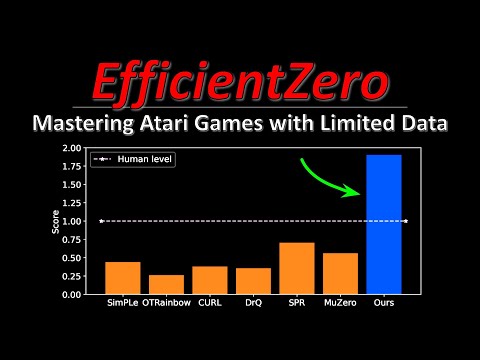
Ключевым вызовом для проекта стал бенчмарк Atari 100k, предполагающий обучение модели на данных объемом всего в 100 тысяч переходов — это эквивалент примерно двух дней реального игрового времени. По мнению Янника Килхера (Yannic Kilcher), автора популярного канала о машинном обучении, EfficientZero не просто превосходит другие RL-алгоритмы в этом режиме, но и демонстрирует производительность, сопоставимую с DQN при использовании в 500 раз большего объема данных.
🎮 Фундамент: от AlphaZero к MuZero 2:31
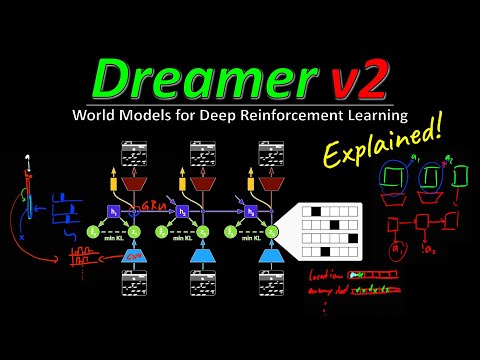
Чтобы понять суть улучшений EfficientZero, необходимо вспомнить работу его предшественника — MuZero. В классическом RL-подходе агент взаимодействует со средой, получая наблюдения и награды, чтобы максимизировать итоговый выигрыш.
- Model-free RL: Прямое обучение нейросети для предсказания действий на основе истории наблюдений без понимания структуры мира.
- Model-based RL (AlphaZero): Использование четкой модели среды (например, правил шахмат или Atari-симулятора) для поиска по дереву вариантов (Monte Carlo Tree Search).
MuZero совершил прорыв, отказавшись от жесткой привязки к модели среды. Вместо этого он обучается «латентной модели» — он переводит наблюдения в скрытое состояние (hidden state) и предсказывает будущее скрытое состояние, награду и значение (value) лишь на основе сигналов, полученных из среды.
🛠 Три кита эффективности: почему MuZero не хватало данных 10:51
Килхер отмечает, что авторы EfficientZero выделили три критических слабых места в архитектуре MuZero:
- Недостаточный надзор (Supervision) за моделью среды: Модель учится исключительно на «редких» сигналах наград и значений, что крайне затратно по данным.
- Проблема накопления ошибок (Aleatoric uncertainty): При поиске по дереву предсказания наград на каждом шаге содержат погрешность, которая при суммировании по глубине дерева превращается в огромную ошибку.
- Проблемы «off-policy» обучения: Использование данных, сгенерированных старыми версиями нейросети, снижает точность обучения, так как текущая политика уже ушла вперед.
🚀 Технические улучшения: как работает EfficientZero 14:13
Для решения этих проблем авторы внедрили три ключевых изменения:
- Самообучающаяся консистентность (Self-supervised consistency loss): Используя подход, аналогичный SimSiam, модель сравнивает скрытое состояние $t+1$, полученное из «реального» наблюдения, с предсказанным скрытым состоянием. Это принуждает нейросеть лучше понимать структуру среды, используя более богатый сигнал, чем просто цифра награды.
- Предсказание «префикса значений» (Value prefix prediction): Вместо накопления ошибок через пошаговое суммирование наград, модель использует LSTM-сеть, которая смотрит на предсказанные состояния на $k$ шагов вперед и выдает общую сумму наград как единое значение.
- Модельно-базированая коррекция (Model-based off-policy correction): Авторы ограничивают использование «старых» траекторий из буфера воспроизведения, обрезая их там, где неопределенность становится слишком высокой, и дополняя их «воображаемыми» траекториями, сгенерированными уже текущей версией модели.
⚖️ Анализ и выводы: прорыв или подстройка под бенчмарк? 25:52
Результаты исследований показывают значительный рост качества обучения. Однако Килхер обращает внимание на важный нюанс: в ходе тестов не удалось выявить единственную «серебряную пулю» среди трех улучшений. Для разных игр Atari критически важными оказываются разные механизмы.
По мнению Килхера, это создает определенный риск «переинжиниринга» (over-engineering) алгоритма под конкретный бенчмарк, вместо создания универсально эффективного метода. Тем не менее, он полагает, что EfficientZero — это амбициозный шаг вперед, и работа выглядит многообещающе, хотя для подтверждения статуса «стандартного» алгоритма для эффективного RL потребуются дополнительные испытания на других наборах задач, например, DeepMind Control Suite.