Dreamer v2: Прорыв в обучении агентов с помощью дискретных моделей мира 0:00
Алгоритм Dreamer v2, представленный исследователями из Google Brain, DeepMind и Университета Торонто, устанавливает новую планку в области обучения с подкреплением (Reinforcement Learning, RL) для среды Atari. В отличие от своих предшественников, этот метод использует «обучение в воображении»: агент сначала строит компактную модель мира, а затем обучается внутри неё, не взаимодействуя с реальной средой. Янник Килхер отмечает, что Dreamer v2 является лучшим алгоритмом для обучения на одной видеокарте (GPU), превосходя существующие модели, такие как Rainbow, IQN и DQN,.
Концепция моделей мира: от классики к «мечтам» 4:56
Традиционные RL-алгоритмы часто делятся на две категории: модельно-свободные (model-free) и модельно-ориентированные (model-based),.
- Модельно-свободные алгоритмы: Взаимодействуют с миром напрямую, пытаясь запомнить, какие действия в конкретных ситуациях приносят награду. Килхер указывает на их слабость: алгоритм может считать два визуально похожих, но чуть отличающихся состояния «совершенно разными», что замедляет обучение.
- Модельно-ориентированные алгоритмы: Сначала изучают структуру мира (как он меняется под действием агента), а затем используют эту модель для планирования действий.
Dreamer v2 комбинирует оба подхода: он строит точную модель мира, чтобы «мечтать» (имитировать игровой процесс), и внутри этого «сна» проводит обучение агента, что позволяет значительно ускорить процесс по сравнению с взаимодействием с реальной средой.
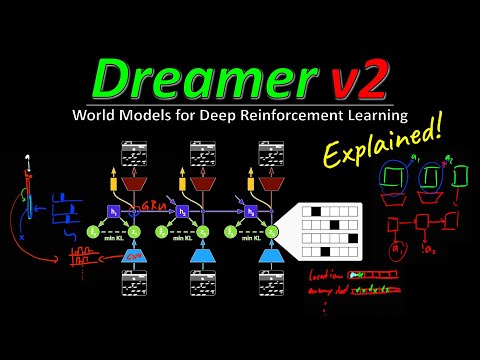
Архитектура модели: дискретные латентные состояния 12:12
Ключевой инновацией авторов стала замена традиционных гауссовских латентных переменных на дискретные (категориальные).
- Структура состояния: Состояние модели состоит из комбинации детерминированной части (выход GRU-сети) и стохастической части. Последняя представлена набором из 32 категориальных переменных, каждая из которых может принимать одно из 32 значений.
- Преимущества дискретности: По мнению Килхера, это позволяет модели эффективно кодировать важные аспекты игры (например, положение врага или состояние здоровья) в разреженном виде, а также предсказывать мультимодальные распределения будущего, что недоступно простым гауссовским моделям,.
- Сжатие: Система экстремально сжимает входящие изображения, превращая их в компактный набор дискретных кодов, что делает вычисления быстрыми.
Процесс обучения: KL-дивергенция и Straight-Through Estimator 26:01
Обучение модели включает предсказание будущих кадров и наград. Чтобы агент мог «мечтать» без реальных наблюдений, авторы используют механизм предсказания будущих состояний без обращения к визуальным данным.
- Trade-off: Модель должна сбалансировать точность реконструкции изображения (когда мы видим кадр) и точность предсказания динамики (когда мы «фантазируем»). За этот баланс отвечает KL-дивергенция.
- Straight-Through Estimator: Поскольку оператор взятия выборки (sampling) не позволяет напрямую передать градиент, авторы применяют трюк с градиентным обходом, позволяющий обучать сеть «через» стохастические этапы,. Это снижает вариативность сигналов при обучении политики.
Критика и ограничения 34:04
Несмотря на успех в Atari, Янник Килхер высказывает ряд замечаний по поводу применимости метода:
- Специфичность среды: Алгоритм кажется чрезмерно заточенным под специфику Atari. В играх, где важны мелкие детали (как в Video Pinball), модель может игнорировать критически важные объекты, концентрируясь на фоновом шуме,.
- Гиперпараметры: По словам ведущего, количество настроек (гиперпараметров) в алгоритме «ошеломляет». Модель использует сложные графики расписаний для коэффициентов обучения, что требует огромных усилий для первичной настройки.
- Проблема нормализации: Обсуждая лидерство модели, Килхер отмечает, что стандартные метрики в Atari могут быть обманчивы из-за игры на «рекордах». Он считает, что клиппинг результатов по человеческим мировым рекордам — спорный, но логичный шаг для оценки реальных навыков агента,.